Кластеризация Web-серверов гарантирует «безотказность» критически важных приложений

|
| Кластеризация Web-серверов и приложений гарантирует готовность, масштабируемость и надежность критически важных приложений |
Кроме того, можно защитить целостность данных на случай сбоя в любой уязвимой точке. Наращивание по мере необходимости числа компьютеров увеличивает надежность, причем цена этого наращивания, как правило, значительно ниже стоимости системы с симметричной многопроцессорной обработкой.
Проблема, с которой приходится здесь сталкиваться, связана с управлением самими кластерами. Их зачастую непросто развернуть и еще сложнее оптимизировать. Более того, из-за больших расходов и трудностей, связанных с созданием приложений или написанием специализированных скриптов, обеспечивающих повышенный уровень готовности, потенциал кластеризации во многом остается неиспользованным.
В ситуациях, когда простой, потеря данных и узкие места при обработке транзакций недопустимы, компьютерная кластеризация может предоставить стабильную основу для увеличения готовности, надежности и балансировки нагрузки, необходимых для оперативной обработки транзакций (OLTP).
Как правило, для увеличения производительности приложений используется три варианта кластеров: вычислительные кластеры, кластеры с балансировкой нагрузки и кластеры высокой готовности.
Кластеризация предохраняет от аппаратных и программных сбоев за счет поддержки зеркального отражения работы сервера на вторичной резервной системе, или узле. При возникновении системной ошибки на первичном узле дублирующий узел берет на себя доставку приложений.
Кластеры с балансировкой нагрузки динамически распределяют процессорную нагрузку и сетевой трафик между имеющимися системами в серверной ферме, гарантируя, что ни одна система или сетевой канал не выйдут из строя при обработке клиентских запросов. Узлы в кластерах с балансировкой нагрузки, которые можно удалять или добавлять по мере необходимости, как правило, группируются в соответствии с конкретным приложением. При этом один и тот же набор приложений работает в одном кластере, чтобы обеспечить готовность в случае резких колебаний в уровне использования.
В то время как кластеры высокой готовности защищают от сбоев, кластеры с балансировкой нагрузки гарантируют оптимальное использование сетевых и аппаратных ресурсов. На практике в большинстве кластерных реализаций OLTP применяется смешанный подход, который позволяет использовать преимущества кластеров обоих типов для увеличения эффективности приложений и гарантий непрерывной работы систем.
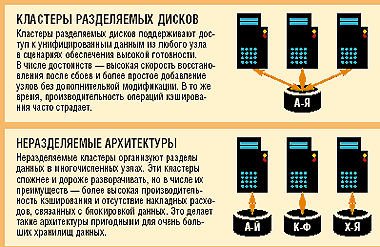
С ростом требований к доставке персонифицированного и динамического информационного наполнения возникает необходимость в производительности и готовности, значительно превышающих средний уровень. В итоге для критически важных приложений электронного бизнеса приходится прибегать к кластеризации баз данных. Но о том, какая из архитектур — разделяемый диск или не использующий общие ресурсы кластер — является предпочтительной, ведутся жаркие споры.
При подходе, предусматривающем совместное использование диска, любой узел в кластере может обращаться к любому блоку данных, так что входящие запросы могут направляться к любому экземпляру реляционной СУБД. С другой стороны, в не использующем общие ресурсы кластере данные разделены на статические, логические сегменты, к каждому из которых можно получить доступ только с одного узла-«хозяина».
Метод совместного использования диска имеет преимущества в тех ситуациях, когда требуется высокая готовность. Запросы могут динамически балансироваться или распределяться между узлами вне зависимости от того, к какому разделу данных обращен запрос. В случае возникновения ошибки на узле запросы направляются на следующий доступный узел без нарушения готовности данных. Добавление узлов в кластер не требует переконфигурации архитектуры, приложений или базовой организации данных.
Недостаток такого подхода состоит в том, что подобный повсеместный доступ к данным требует, чтобы в определенный момент времени к конкретному блоку данных обращался только один узел. Как следствие, необходим распределенный менеджер блокировки, который обеспечит глобальное управление обновлением кэш-памяти и записью на диск для того, чтобы гарантировать целостность данных, и этот контроль будет осуществляться за счет снижения скорости.
С другой стороны, не использующий общие ресурсы кластер не требует блокировки и позволяет увеличить производительность за счет эффективного использования кэширования. Поскольку данные локализованы, шансы попадания в кэш на узле каждого раздела увеличиваются. Из-за этой способности распределять данные по непересекающимся сегментам — подход, не предполагающий совместно использования ресурсов, остается более предпочтительным для увеличения производительности в крупных хранилищах данных.
Кластеризация приложений и БД
Производители могут наперебой расхваливать преимущества своих архитектур баз данных, но лучшие решения будут настроены на уникальные требования каждого пользователя к готовности и производительности