
Компания «НейрОК» разрабатывает систему подготовки тезаурусов и поиска с их помощью
Любая информационная система должна строиться таким образом, чтобы рутинная работа по выявлению структуры данных выполнялась автоматически и структура эта была представлена человеку в наиболее удобной форме — в виде двухмерных или даже трехмерных моделей. Современные базы данных и поисковые системы, как правило, не дают пользователю возможности представить структуру информации достаточно наглядно. Однако сейчас пользователи все больше и больше ценят удобство в общении с базой данных. Для препарирования данных требуется привлечение труда многочисленных экспертов, и это является основной проблемой при построении крупных баз данных и знаний.
Структура языка, которую должны учитывать такие системы, определяется тезаурусом — набором терминов и связями между ними. Большинство баз данных и поисковых систем опираются на тезаурус, загодя подготовленный экспертами. Это позволяет поисковику более качественно работать с конкретным языком. Однако подготовить тезаурусы для каждого сообщества практически невозможно. Так возникает необходимость в автоматизированной системе для подготовки тезаурусов и поиска с их помощью необходимой информации. В этой статье речь идет об одной из таких систем, разработанной российской компанией «НейрОК».
Семантический анализатор
В «НейрОК» построили систему для выделения информации из большого объема данных с помощью методов распознавания образов. Система занимается анализом семантических конструкций текста, чтобы понять смысл, зашифрованный во взаимоотношениях между словами. У каждого слова может быть несколько значений, но в зависимости от сочетания слов выбирается одно из них. Ядро семантического анализатора «НейрОК» работает примерно так: система просматривает большое количество отрывков текстов и выясняет отношение слов друг к другу. В результате выделяются базовые семантические категории, по которым можно расслоить темы анализируемых фрагментов. Каждое слово получает свое семантическое представление, то есть фиксируется, в каких категориях оно присутствует и в какой степени.
Компания поставила своей целью сделать работу с данными наиболее естественной и простой. Для этого были созданы визуальные компоненты, которые показывают семантические структуры текстов в виде графических образов. В итоге при обращении к базам данных созданная технология позволяет работать уже не с SQL-подобными запросами, а с графическим представлением информации. Базу данных можно представить в виде карты галактики, где звездами являются отдельные документы. Все близкие по смыслу документы собраны в тематические галактики, а их светимость пропорциональна числу находящихся в них документов. Расстояния между ними отражают расстояния между документами в многомерном семантическом пространстве. Пользователь может заглянуть внутрь галактики и посмотреть структуру каждой из них более подробно. Таким образом, вся база данных представляется в виде кластеров документов, объединенных по ассоциативным признакам в соответствии с ранее установленной семантической структурой документов. При этом система фактически обучается языку предметной области и раскладывает в терминах этого языка содержание документов базы.
Семантический анализатор не требует обучающей выборки, а самостоятельно разделяет неструктурированный набор документов на кластеры. Таким образом, подавая на его вход набор документов, на выходе получим разбитую по темам подборку материалов и ее графическое представление. «Расстояние» между темами определяется исходя из того, насколько близки их семантические структуры.
Такой системой можно пользоваться как поисковой. В этом случае она находит кластер документов, который ближе всего подходит к искомому слову, пользуясь при этом выделенной семантикой как тезаурусом. При поиске система учитывает и ассоциативные связи. Подобная система поиска имеет два плюса — не нужны специальные эксперты для создания тезауруса, и качество автоматически генерируемого тезауруса улучшается с увеличением объема информации. Система анализа семантики позволяет для каждого языка построить собственный тезаурус и настроиться на диалект конкретного сообщества. Аналогичным образом система может работать и с разными национальными языками.
Система также может реализовать ассоциативный поиск, не задействуя сложный язык запросов. Чем больше слов пользователь укажет, тем точнее система подберет для него нужные документы. При этом самый точный поиск — «найти похожий документ», который также легко реализовать с помощью семантических структур. Причем поиск учитывает не просто ключевые слова, но и комбинации слов. Впрочем, если сделать поиск полностью ассоциативным, это может вызвать некоторые затруднения у пользователей. Скажем, если в машине ассоциативного поиска искать слово «Мерседес», то будут также найдены документы, в которых упоминаются другие марки автомобилей. Поэтому применяется некоторый комбинированный вариант, учитывающий ассоциативные связи слов.
Персональная газета
Известно, что существует два типа поиска — активный и пассивный. При активном поиске человек старается найти что-то конкретное и ему заранее известное. Пассивный поиск характерен для задач фильтрации, например для поиска новости по определенной теме. Во втором случае использование ассоциативного поиска наиболее оправданно, поскольку точное вхождение слов не обязательно, а требуется найти документы по определенной теме. Как правило, для тематического поиска сложно правильно сформулировать запрос, и в этом случае хорошо помогает именно ассоциативный поиск. Фактически это еще один интеллектуальный способ доступа к информации. Использовать эту технологию в сетях intranet можно для автоматической категоризации любой текстовой информации; это поможет сотрудникам компаний быстрее искать нужные им данные.
Впрочем, семантический анализатор можно использовать и для персональной работы с помощью специальных агентов. Такие агенты следят за деятельностью пользователя, выявляя предпочтения «хозяина» и предлагая ему новые документы, которые соответствовали бы этим предпочтениям. А информация о том, где в Internet искать документы на данную тему, может находиться на некотором центральном сервере.
Сейчас такая система реализована в виде «персональной газеты». Она отслеживает появление новых документов, сравнивает их семантическую структуру с предпочтениями пользователей и выдает пользователю только необходимые для него. Систему можно постоянно обучать, указывая ей, какие документы подошли по теме, а какие нет. В результате чем больше документов было аннотировано подобным образом, тем более точно система настроится на предпочтения пользователей. Такая система, например, уже развернута компанией InfoArt в качестве основы службы iPost. Кстати, совсем не обязательно, чтобы агенты работали на клиентах. Агенты можно использовать на условиях «аренды». В принципе агент можно использовать и для публикации информации, распространяя сообщение о теме нового документа по сети центральных серверов. Сейчас в «НейрОК» работают над созданием таких интеллектуальных агентов.
Децентрализация информационных потоков
Вообще же в будущем, скорее всего, станут более популярными специализированные системы поиска, которые выделяют в Internet информацию по определенной теме и позволяют пользователям искать только в ней. Для реализации подобной системы найдут применение многочисленные тематические агенты. Такая распределенная сеть будет обладать свойствами одного большого поисковика. Тематические агенты будут автоматически определять, соответствует ли новый документ их теме, поскольку они будут хорошо знать значения слов в контексте.
«Internet будущего — это интеллектуальная оболочка множества семантических серверов разного масштаба, — считает Сергей Шумский, вице-президент «НейрОК». — Все они работают по одному и тому же протоколу, поддерживают одну и ту же технологию и могут обмениваться данными друг с другом. Эта система будет работать постоянно, поддерживая актуальность всего громадного объема информации, который сейчас содержится в Internet. Такая технология позволит индексировать Internet в реальном времени».
Сервер, как и клиент, написан на Java. Управление базой производится серверной частью. Основная часть обработки — индексация массива информации и построение по нему семантических описаний. Эта операция векторная. Надо отметить, что сервер для категоризации и индексации полностью написан 15 разработчиками «НейрОК». Он очень маленький — около 200 Кбайт, хотя может работать с большими объемами информации. Информация хранится в виде индекса, а сами данные могут храниться как в директориях и Web, так и в любой базе данных, к которой можно получить доступ посредством интерфейса JDBC или ODBC.
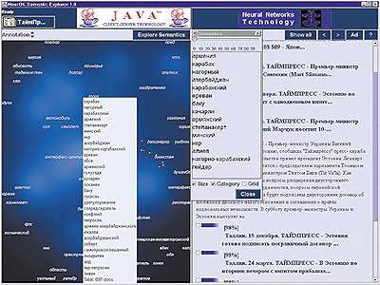 |
| Семантический анализатор может реализовать ассоциативный поиск, не задействуя сложный язык запросов. Чем больше слов пользователь укажет, тем точнее система подберет для него нужные документы |
Сейчас компания готовится к открытию службы Internet-Analist. С ее помощью посетители смогут задать вопрос по интересующей их тематике, и им будет подготовлена тематическая база данных по информации, находящейся в Internet. Пока это лишь демонстрация возможностей технологии, а потом на основе этой базы данных можно будет завести специальный тематический агент, который станет создавать пользователю «персональную газету».
В дальнейшем «НейрОК» планирует научить агенты взаимодействовать между собой для создания распределенной сети. Таким образом, компания рассчитывает изменить подход к распространению информации через Internet.
Нейронные технологии «НейрОК»
- Разработчик: компания «НейрОК». Помимо семантического анализатора занимается также другими наукоемкими технологиями, например, трехмерными дисплеями
- Платформа: Java на сервере и на клиенте
- Продукты: семантический анализатор, работающий на сервере; Java-клиент для визуализации полученных данных; «персональная газета»
- Примеры: демонстрационный сервер AlterEgo (http://beta.alterego.ru/ae2000); служба iPost портала InfoArt (http://iPost.infoart.ru/)