. Примеры могут быть найдены в совершенно разных предметных областях: классификация товаров, контрагентов, комплектация изделия, иерархия должностей, административно-территориальное деление, генеалогическое древо, наконец, просто дерево перебора вариантов или дерево классов.
В общем случае все сводится к моделированию многоуровневой связи «главный—подчиненный», «предок—потомок», «общий—конкретный». Говоря более строгим математическим языком, мы моделируем граф без циклов.
Углубляться в теорию графов в рамках статьи мы не будем, ограничившись минимальными пояснениями по ходу изложения, и рассмотрим наиболее часто встречающиеся варианты реализации древовидных структур в базах данных. В качестве примера используем Microsoft SQL Server 2005, но, познакомившись с общими принципами, вы сможете без затруднений перенести реализацию на любую другую СУБД, с которой придется работать.
Список смежности
Это интуитивно понятный способ организации дерева: замыкаем связь таблицы на саму себя (рефлексивная связь), рис. 1.

Как известно из теории, граф можно представить в виде матрицы, где на пересечении i-й строки и j-го столбца стоит 1, если между узлами (вершинами) графа с номерами i и j есть связь (ребро, дуга), или 0 в противном случае. Такая абстракция называется матрицей смежности.
Матрица смежности может быть также представлена в виде списка (множества) пар с номерами (идентификаторами, кодами) вершин по принципу: есть пара — есть связь, нет пары — нет связи.
Корневые вершины отличаются от других пар пустой (NULL) ссылкой на предка, в приведенном примере это поле «Код вышестоящей территории».
Для выполнения часто используемых выборок требуется поддержка рекурсивных запросов. Если СУБД не умеет выполнять такие запросы, то выборки придется строить с использованием других механизмов, например временных таблиц или хранимых процедур и функций. Рассмотрим примеры запросов.
Выборка поддерева по заданному узлу (здесь и далее по тексту используем синтаксис MS SQL Server 2005):
WITH Поддерево ([Код территории], [Код вышестоящей территории], Наименование, Уровень) AS
(
SELECT [Код территории], [Код вышестоящей территории], Наименование, 1
FROM Территории
WHERE [Код вышестоящей территории] = 40288000 — корень поддерева или IS NULL для корня целого дерева
UNION ALL
SELECT Территории.[Код территории], Территории.[Код вышестоящей территории], Территории.Наименование, Уровень + 1
FROM Территории
INNER JOIN Поддерево ON Территории.[Код вышестоящей территории] = Поддерево.[Код территории]
WHERE Территории.[Код вышестоящей территории] IS NOT NULL
)
SELECT [Код территории], [Код вышестоящей территории], Наименование, Уровень
FROM Поддерево
Выборка всех предков (путь к узлу от корня):
WITH Поддерево ([Код территории], [Код вышестоящей территории], Наименование, Уровень) AS
(
SELECT [Код территории], [Код вышестоящей территории], Наименование, 1
FROM Территории
WHERE [Код территории] = 40288000 — узел
UNION ALL
SELECT Территории.[Код территории], Территории.[Код вышестоящей территории], Территории.Наименование, Уровень + 1
FROM Территории
INNER JOIN Поддерево ON Территории.[Код территории] = Поддерево.[Код вышестоящей территории]
)
SELECT [Код территории], [Код вышестоящей территории], Наименование, (SELECT MAX(Уровень) FROM Поддерево) — Уровень
FROM Поддерево
Проверка, входит ли узел в поддерево, определяемое своим корнем (например, входит ли данный товар в группу одного из верхних уровней, «Кисточка» в «Инструменты для ремонта»):
WITH Поддерево ([Код территории], [Код вышестоящей территории], Наименование, Уровень) AS
(
SELECT [Код территории], [Код вышестоящей территории], Наименование, 1
FROM Территории
WHERE [Код территории] = 40288000 — узел, проверяемый на вхождение
UNION ALL
SELECT Территории.[Код территории], Территории.[Код вышестоящей территории], Территории.Наименование, Уровень + 1
FROM Территории
INNER JOIN Поддерево ON Территории.[Код территории] = Поддерево.[Код вышестоящей территории]
)
SELECT result =
CASE
WHEN EXISTS(
SELECT 1 FROM Поддерево
WHERE [Код территории] = 40260000 /* корень поддерева */)
THEN ‘Узел входит в поддерево’
ELSE ‘Узел НЕ входит в поддерево’
END

Подмножества
Сразу оговорюсь: к способу, продвигаемому Джо Селко (Joe Celko) и по недоразумению называемому nested sets (вложенные множества), эта схема никакого отношения не имеет. Поэтому, чтобы избежать путаницы, я даже изменил информативное название «вложенные множества» на более простое.
В этой схеме дерево представляется вложенными подмножествами: корневой уровень включает в себя все подмножества — узлы первого уровня, а они, в свою очередь, включают в себя все узлы второго уровня и т.д. Иерархия территорий может выглядеть так, как показано на рис. 2.

В реляционном же виде схема представлена на рис. 3.


Но за излишества надо платить. Целостность данных будет поддерживаться триггерами, которые перезаписывают список и уровни предков данного узла при его изменении. Для операции удаления достаточно декларативной ссылочной целостности (каскадное удаление), если ваша СУБД его поддерживает.
Если за образец принять список смежности, который не содержит никакой избыточности, то для метода подмножеств на каждый уровень потребуется столько дополнительных записей в таблице подмножеств, сколько элементов находится на данном уровне дерева, умноженном на номер уровня (вершину считаем первым уровнем). Количество записей растет в арифметической прогрессии.
Однако стоит взглянуть на примеры все тех же типовых запросов, как становятся очевидными преимущества, полученные от избыточности хранения: запросы стали короткими и быстрыми.
Выборка поддерева по заданному узлу:
SELECT [Код подмножества], Уровень
FROM Подмножества
WHERE [Код множества] = 123 — корень поддерева
ORDER BY Уровень
Выборка всех предков (путь к узлу от корня):
SELECT [Код множества], Уровень
FROM Подмножества
WHERE [Код подмножества] = 345 — узел
ORDER BY Уровень
Проверка вхождения узла в поддерево:
SELECT result =
CASE
WHEN EXISTS(
SELECT 1 FROM Подмножества
WHERE [Код подмножества] = 345 /* узел */
AND [Код множества] = 211 /* корень поддерева */)
THEN ‘Узел входит в поддерево’
ELSE ‘Узел НЕ входит в поддерево’
END

Маршрут обхода
Как известно из уже упомянутой теории графов, для обхода дерева существует три способа: можно проходить узлы в префиксном, инфиксном или суффиксном порядке. Префиксный порядок обхода дерева рекурсивно определяется так: сначала корень дерева, потом узлы левого поддерева в префиксном порядке, наконец, узлы правого поддерева в префиксном порядке. Сложно? Взгляните на рис. 4, и все станет предельно ясно.

Хранение маршрута обхода дерева в префиксном порядке и есть тот самый способ, который его уважаемый автор Джо Селко (или его интерпретаторы), видимо, по недоразумению продвигает под названием «вложенные множества» (nested sets). По недоразумению, потому что из рис. 4 ясно, что о множествах здесь речи не идет. Однако эта неувязка с названиями нисколько не уменьшает практической ценности метода.
 Квадратик на рисунке обозначает узел, цифра в левом его углу является порядковым номером этапа маршрута при входе в узел, а цифра справа — при выходе, т.е. когда тем же способом пройдены все потомки. Как нетрудно заметить, номера потомков всегда располагаются в интервале между соответствующими номерами предка, сколь угодно дальнего. Храня порядок обхода дерева (рис. 5), этим замечательным свойством можно воспользоваться в типовых запросах, избежав рекурсии.
Квадратик на рисунке обозначает узел, цифра в левом его углу является порядковым номером этапа маршрута при входе в узел, а цифра справа — при выходе, т.е. когда тем же способом пройдены все потомки. Как нетрудно заметить, номера потомков всегда располагаются в интервале между соответствующими номерами предка, сколь угодно дальнего. Храня порядок обхода дерева (рис. 5), этим замечательным свойством можно воспользоваться в типовых запросах, избежав рекурсии.
Очевидная сложность — пересчет порядка обхода при добавлении новых или перемещении имеющихся узлов (удаление можно игнорировать). В триггере придется реализовать последовательный порядок обхода с оптимизацией. Но, например, если добавляется элемент самого нижнего уровня, то все равно придется пересчитать все, что «выше» или «правее», а это может быть сравнимо с пересчетом маршрута по всему дереву.
Типовые запросы в методе маршрута обхода также лаконичные и быстрые.
Выборка поддерева по заданному узлу:
SELECT T1.*
FROM [Территории 3] as T1, [Территории 3] as T2
WHERE T1.Вход BETWEEN T2.Вход AND T2.Выход
AND T2.[Код территории] = 123 — корень поддерева
ORDER BY T1.Вход
Выборка всех предков симметрична предыдущему запросу относительно BETWEEN:
SELECT T1.*
FROM [Территории 3] as T1, [Территории 3] as T2
WHERE T2.Вход BETWEEN T1.Вход AND T1.Выход
AND T2.[Код территории] = 345 — узел
ORDER BY T1.Вход
Проверка вхождения узла в поддерево:
SELECT result =
CASE
WHEN EXISTS(
SELECT 1 FROM [Территории 3] as T1, [Территории 3] as T2
WHERE T1.[Код территории] = 456 /* узел */
AND T2.[Код территории] = 123 /* корень поддерева */
AND T1.Вход BETWEEN T2.Вход AND T2.Выход)
THEN ‘Узел входит в поддерево’
ELSE ‘Узел НЕ входит в поддерево’
END

Оптимизация: хранение номеров с «дырками»
Давным-давно, в эпоху распространенности языка Бейсик (не путать с Visual Basic), строки программы последовательно нумеровались. Делалось это для того, чтобы, во-первых, интерпретатору было легче обрабатывать текст программы, а во-вторых, чтобы работали многочисленные операторы безусловного перехода (GOTO, если кто забыл) на строку с таким-то номером. Существовало и ограничение, согласно которому на каждой строке мог находиться только один оператор.
Поскольку программа во время своей жизни подвергалась изменениям, то в нее добавлялись новые операторы. Опытные программисты сразу нумеровали строки не 1, 2, 3, а 10, 20, 30. Это позволяло вставить в текст новую строку без полной перенумерации всех последующих.
Думаю, идею вы уже поняли: надо нумеровать входы и выходы из узлов с некоторым интервалом, например 100 или 1000, что в значительной степени зависит от предварительных оценок количества хранимых узлов дерева.
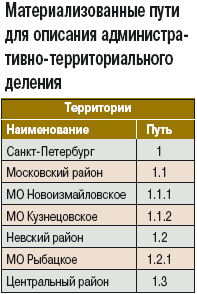
Материализованные пути
 Суть метода заключается в хранении пути от вершины до данного узла в явном виде и в качестве ключа. Например, ранее приведенная на рисунке иерархия территорий могла бы выглядеть так:
Суть метода заключается в хранении пути от вершины до данного узла в явном виде и в качестве ключа. Например, ранее приведенная на рисунке иерархия территорий могла бы выглядеть так:
Как видите, очень напоминает нумерацию частей, разделов и глав в книге.
Данный метод является наиболее наглядным с точки зрения кодификации элементов: каждый узел получает интуитивно понятное значение, сам код и его части несут смысловую нагрузку. Подобные свойства важны в классификациях, предназначенных для широкого использования, например в стандартизованных справочниках территорий (ОКАТО), отраслей экономики (ОКВЭД, NAICS), медицинских диагнозов (МКБ — международный классификатор болезней) и во многих других областях.
Сложнее ситуация с запросами. Они лаконичны, но не всегда эффективны, так как могут требовать поиска по подстроке.
Выборка поддерева по заданному узлу:
SELECT *
FROM [Территории 4]
WHERE Путь LIKE ‘1.2%’ — корень поддерева
ORDER BY Путь
 Выборка всех предков:
Выборка всех предков:
SELECT *
FROM [Территории 4]
WHERE ‘1.2.1’ /* узел */ LIKE Путь + ‘%’
ORDER BY Путь
или
SELECT T1.*
FROM [Территории 4] T1, [Территории 4] T2
WHERE T2.Путь LIKE T1.Путь + ‘%’
AND T2.Наименование like ‘МО Рыбацкое’
Проверка вхождения узла в поддерево:
SELECT result =
CASE
WHEN EXISTS(
SELECT 1 FROM [Территории 4] as T1, [Территории 4] as T2
WHERE T1.Наименование = ‘МО Рыбацкое’ /* узел */
AND T2.Наименование = ‘Невский район’ /* корень поддерева */
AND T1.Путь LIKE T2.Путь + ‘%’)
THEN ‘Узел входит в поддерево’
ELSE ‘Узел НЕ входит в поддерево’
END

Оптимизация
Зная заранее максимальное количество уровней и максимальное число прямых потомков, можно обойтись без разделителей, используя числовые коды с фиксированной разбивкой на группы разрядов. Пустые лидирующие разряды заполняются нулями.
Подобная система используется во многих межсистемных классификаторах, например относящихся к государственному стандарту ОКАТО (Общероссийский классификатор объектов административно-территориального деления) или NAICS (North American Industry Classification System — Североамериканская система классификации отраслей экономики).
Итоги
Пришла пора подвести черту под нашим небольшим обзором. Если собрать достоинства и недостатки в одну общую таблицу, то мы получим более полную картину.
Следует помнить, что нет «плохих» или «хороших» методов: вы делаете оценки и выбор, исходя из условий конкретной задачи.
Нам хотелось показать вам основные принципы, используя которые вы сможете не только сделать обоснованный рациональный выбор одного из известных методов, но и создать свой, оптимизированный вариант. В конце концов, инженер тем и отличается от рабочего на сборке, что может и должен уметь находить оптимальные средства для решения задачи, а не слепо копировать чужие инструкции и шаблоны.
Рекомендуемая литература и ресурсы
- Joe Celko. Trees in SQL. Some answers to some common questions about SQL trees and hierarchies. http://www.intelligententerprise.com/001020/celko.jhtml?_requestid=1266295
- Vadim Tropashko. Trees in SQL: Nested Sets and Materialized Path. http://www.dbazine.com/oracle/or-articles/ tropashko4
- Джо Селко. Стиль программирования Джо Селко на SQL. Пер. с англ. СПб.: Питер, 2006.
ОБ АВТОРЕ
Сергей Тарасов — инженер, e-mail: serge@arbinada.com.
Преимущества и недостатки рассмотренных методов