Какие инструменты вы используете для разработки и отладки программ? Большинство из нас пишет код в полноэкранном редакторе, транслирует его с помощью компилятора, затем с помощью отладчика исправляет ошибки, а для архивирования и обмена программами применяет систему управления исходными текстами.

Эти средства появились еще в 70-е годы, когда переход от пакетного к интерактивному программированию стал стимулом для разработки новых языков, инструментов, сред и других утилит, существование которых сейчас считается само собой разумеющимся.
Спустя три десятилетия такие средства по-прежнему остаются основными инструментами, с помощью которых разработчики пишут программное обеспечение. Хотя с тех пор их существенно усовершенствовали, эти инструменты не отвечают требованиям сложных программ и практически не используют возможности современных быстродействующих компьютеров. Сейчас инструментальные средства эпохи дефицита вычислительных ресурсов работают на машинах, быстродействие которых — на четыре порядка больше, чем прежде. Разработчики тратят немало сил на создание и поддержку сложных программных систем, в то время как огромные компьютерные ресурсы пропадают втуне.
Microsoft Research разработала два поколения инструментальных средств, которые уже используются в Microsoft для поиска и исправления ошибок. Этот инструментарий помогает компенсировать разрыв между целью, стоящей перед программистом, и огромным количеством кода, требуемого для реализации такой цели. Задача разработчика — преодолеть эту пропасть, а задача инструментальных средств проверки корректности программ — гарантировать, что получившийся «мост» будет прямым, ровным и соединит нужные точки.
Появление все более качественных средств программирования (или более быстрых компьютеров) вряд ли превратит разработку программного обеспечения в рутинную деятельность. Программирование — сложная интеллектуальная задача, требующая от талантливых людей длительной сосредоточенной работы. Однако, как механические устройства высвобождают потенциал творческих людей, помогая им выполнять физическую работу, так и средства программирования делают разработку более эффективной, принимая на себя контроль за «мелочами», выявляя несовместимости и гарантируя единое качество.
Инструменты проверки правильности программ
Программные ошибки, которые обнаруживаются инструментальными средствами, разделяют на две большие категории.
- Ошибки в использовании возможностей языка программирования. Например, к ним относится ссылка на неинициализированную переменную. Подобные ошибки могут находить такие инструменты, как компиляторы и программа Lint [1].
- Ошибки в использовании прикладного программного интерфейса. Это, скажем, попытка второй раз закрыть дескриптор файла. Такие ошибки значительно сложнее языковых, поскольку они специфичны для каждого из API. Существует множество разных API. Одни из них открыты и широко используются, а другие — внутренние и применяются только в одной программе. С практической точки зрения, инструменты для поиска подобных ошибок должны быть расширяемыми, благодаря чему программисты смогут определять новые правила их использования, не обращаясь к помощи разработчиков инструментария.
Ошибки обеих категорий, как правило, выявляются с помощью статического анализа, в рамках которого изучаются возможные варианты выполнения программы без ее реального запуска. Альтернативный подход — тестирование — позволяет выявить ошибки во время выполнения программы.
Оба подхода дополняют друг друга. Статический анализ помогает определять все варианты выполнения программы, поэтому позволяет искать ошибки вне зависимости от входных данных. Однако иногда он указывает на ложные ошибки. Мало того, эффективный анализ может выполняться лишь для небольшого числа относительно простых возможностей программы. Сейчас и в ближайшем будущем тестирование останется основной методикой, с помощью которой можно установить, что программа работает корректно и порождает правильный результат. Тем не менее статический анализ весьма полезен, поскольку благодаря ему можно находить ошибки, не проявляющиеся во время тестирования или существующие в вариантах выполнения программы, которые не проверяются при тестировании.
Основу анализа программ составляет сформулированная Тьюрингом проблема останова. Она показывает, что в общем случае невозможно определить, будет ли программа работать с ошибкой. Как следствие, инструментарий лишь аппроксимирует поведение программы, а это заставляет идти на компромисс, выбирая между надежностью и полнотой. Надежная (sound) модель программы позволяет найти каждую программную ошибку, но некоторые ошибки являются ложными, т.е. возникают из-за дефектов анализа. Полная (complete) модель программы гарантирует, что каждая ошибка в модели представляет собой ошибку в программе и ни одна из таких ошибок не является ложной.
С учетом проблемы останова невозможно создать инструментарий, способный отвечать на любые нетривиальные вопросы о поведении программы, поэтому разработчикам таких утилит приходится выбирать между надежностью и полнотой. Большинство отдает предпочтение надежному анализу и терпимо относится к сообщениям о ложных ошибках, хотя множество полезных инструментов создается на базе эвристик, не являющихся ни надежными, ни полными.
Чтобы конкретизировать сказанное, рассмотрим следующий код.
FILE* f;
if (complex_calc1())
f = fopen(...);
...
if (complex_calc2())
fclose(f);
Этот код выполняется корректно только в том случае, если предикаты условных операторов complex_calc1 и complex_calc2 порождают одинаковые результаты. Надежная модель предполагает, что каждое условие допустимо вычислять разными способами, поэтому каждая файловая операция может выполняться независимо от других. Хотя иногда это не так, данный подход позволяет найти ошибку, возникающую, когда обе функции не коррелируют друг с другом. В свою очередь, полный анализ приведет к выдаче сообщения об ошибке только в том случае, если будет установлена взаимосвязь между двумя предикатами (например, в одном x < 0, а в другом x > 0). Если о такой взаимосвязи не известно, при полном анализе ошибка найдена не будет.
На практике, если задача инструментария заключается в поиске ошибок, он не обязательно должен быть надежным или полным. С учетом имеющейся альтернативы надежность более предпочтительна, поскольку такая модель позволяет найти все ошибки, а разработчики могут обрабатывать ложные отчеты с помощью технологий фильтрации и сортировки. Кроме того, только надежные инструменты гарантируют, что конкретная ошибка возникнуть не сможет.
В Microsoft разделили свои инструменты на два поколения. Средства первого поколения PREfix и PREfast используют эвристический ненадежный анализ, но являются устойчивыми, высококачественными решениями. Большинство наших групп разработки регулярно применяют их для проверки своего кода. Средства второго поколения — результаты исследований в области надежного анализа программ — только начинают активно применяться. Хотя эти инструменты в первую очередь ориентированы на поиск ошибок при использовании API, они опираются на множество точных расширяемых методик анализа программ.
Инструментарий Microsoft первого поколения
PREfix и PREfast используют для поиска ошибок дополняющие подходы. PREfix выполняет детальный анализ с последовательным перебором всех возможных вариантов выполнения программы, чтобы проследить передачу информации между функциями. PREfast — более простой инструмент, выполняющий локальный поиск ошибок. Он разбирает отдельные функции и предоставляет инфраструктуру, с помощью которой пользовательские подключаемые модули могут проходить по деревьям разбора, чтобы идентифицировать проблематичные выражения и сообщать о них.
Оба инструмента доказали свою эффективность при поиске ошибок и постоянно используются для проверки большинства продуктов Microsoft. С их помощью было найдено 12,5% всех ошибок, исправленных в Windows Server 2003. Это весьма существенное количество, особенно если учесть ограниченный спектр дефектов, которые могут обнаруживаться такими инструментами.
PREfix
PREfix способен выявлять лишь некоторые виды ошибок в программах, написанных на Си и C++ [2]. К ним относятся ссылки на нулевые указатели, некорректное резервирование и освобождение памяти, применение неинициализированных переменных, простые ошибки состояния ресурсов и некорректное использование библиотек.
PREfix проходит по графу вызовов программы, анализируя все функции снизу вверх. При анализе функции PREfix уже «видит» подпрограммы, вызванные этой функцией, и использует модели, созданные ранее для аппроксимации результатов вызова кода. Рассмотрим, к примеру, функцию на рис. 1. PREfix ничего не знает о параметре j, поскольку программа может вызывать функцию myfunc в разных местах. В силу этого PREfix прослеживает два варианта исполнения в теле программы и в одном из них сообщает о ссылке на неопределенную переменную. Затем, анализируя оба варианта, он порождает модель и указывает, что на параметр есть ссылка, а возвращаемая переменная может быть не проинициализирована. PREfix использует эту модель при вызовах myfunc, чтобы гарантировать: когда фактическое значение аргумента будет равно 0, он сообщит о возможной ссылке на неопределенный результат.
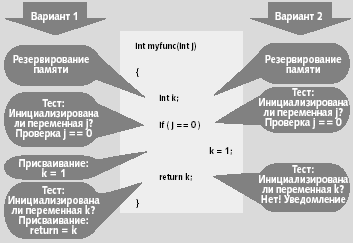
|
| Рис. 1. За каждый проход PREfix создает модель функции и анализирует ее на наличие ошибок |
Эвристический анализ PREfix не является ни надежным, ни полным. Он упрощает аппроксимацию, чтобы сделать анализ возможным для больших исходных текстов с неполной информацией [2]. Например, PREfix проверяет фиксированное число вариантов выполнения функции (как правило, 100). При тщательном выборе таких вариантов PREfix способен найти многие из ошибок, возникающих при различных сценариях выполнения программы, хотя и не может гарантировать отсутствия конкретной ошибки. PREfix позволяет сделать уменьшающие надежность предположения о пропускаемых функциях, чтобы сократить число ложных ошибок, но при этом увеличивается риск не заметить реальную ошибку.
PREfast
PREfast выполняет локальный анализ программ в поисках выражений, ассоциирующихся с ошибками программирования. Разработчики могут легко расширить его функциональность за счет подключаемых модулей, дабы пополнить библиотеку шаблонов, появление которых может свидетельствовать об ошибке. С помощью синтаксического анализатора компилятора Visual C++ PREfast генерирует абстрактные синтаксические деревья для каждой языковой конструкции C++. PREfast выполняет синтаксический разбор функции, а затем вызывает подключаемые модули, каждый из которых анализирует дерево разбора функции в поисках выражений, которые могут свидетельствовать о некорректном использовании или ошибке.
Так, в коде
extern void my_wcsncpy(wchar_t *, wchar_t *, size_t);
wchar_t pPtr1[5];
my_wcsncpy(pPtr1, input,
sizeof(pPtr1))
PREfast жирным шрифтом выделяет выражения, которые могут содержать ошибку, поскольку функция my_wcsncpy в качестве параметра использует строку Unicode (wchar_t). Но последний аргумент — это длина строки в байтах, а не число символов. В коде
my_wcsncpy(pPtr1, input, sizeof(pPtr1)/sizeof(pPtr1[0]))
PREfast выполняет только локальный анализ. Поскольку он работает быстро, программисты все шире применяют его в повседневной работе. Так как PREfast использует синтаксический анализатор компилятора Visual C++, он способен анализировать весь исходный код и формировать инфраструктуру, которую сообщество ученых и разработчиков может использовать для создания все более совершенных инструментальных средств, предназначенных для проверки корректности программ.
Инструментарий второго поколения
PREfix и PREfast подтвердили свою эффективность, однако они способны обнаружить лишь ограниченное число ошибок и реализуют только модель ненадежного анализа. В силу этого Microsoft Research разработала технологию, которая позволяет улучшить имеющийся инструментарий проверки корректности программ в двух важных направлениях. Во-первых, новые инструменты начинают работу с декларативного описания корректного и некорректного поведения программы. Таким образом, их можно настроить на поиск новых ошибок, определив иные правила для API. Во-вторых, эти инструменты используют надежный анализ программ, который дает возможность не пропускать реальных ошибок. Итак, средства второго поколения гарантируют, что конкретная ошибка в программе не возникает.
Slam
Некорректная классификация дефектов нередко порождает ошибки. Например, код, который устанавливает блокировку, зачастую некорректно снимает ее во всех вариантах выполнения. Правила формирования последовательности выполнения программы естественным образов описываются машиной конечных состояний, которая допускает корректные последовательности программных событий и отвергает некорректные. С помощью этих интерфейсов машина предлагает точную спецификацию формирования последовательностей, которую инструментарий может сравнивать с реальным поведением программы.
Slam начинает работу с программы на Си и правил использования. Он либо находит вероятные варианты выполнения программы, в которых нарушается какое-либо правило, либо определяет, что все варианты с точки зрения данного правила корректны [3]. Правила пишутся на Simple Logic (SLIC) c Си-подобной нотацией. Так, на рис. 2 представлены правила, управляющие блокировкой.

|
| Рис. 2. Правила, управляющие блокировкой |
Slam упрощает анализируемые программы, скрывая детали, не имеющие отношения к соответствующему правилу. Даже при наличии сложных правил он может игнорировать большую часть программного кода и данных или преобразовать их к более простому виду. Упрощенное представление Slam — это булева программа, которая содержит конструкции управляющей логики Си и только булевы переменные. Каждая такая переменная контролирует прогнозируемое значение в состоянии программы на Си. Подобное упрощение имеет два преимущества.
- Законченность. Поскольку булевы программы в каждой конкретной точке имеют ограниченное количество булевых переменных, они удобны для автоматизированного анализа завершения программ, такого как анализ потоков данных и проверка модели.
- Надежность. Каждая ошибка использования API в программе на Си также представляется в виде булевой программы, что делает анализ Slam надежным.
Еще одна ключевая возможность Slam заключается в том, что он способен улучшать абстракции булевой программы. Поскольку булева программа в общем случае имеет больше вариантов поведения, чем соответствующая программа на Си, булева программа может содержать варианты, в которых возникают ложные ошибки, невозможные в коде на Си. Для того чтобы ликвидировать ложные пути в булевой программе, Slam использует технологию контрпримеров.
Пример. Чтобы проиллюстрировать работу Slam, проанализируем код на Си, представленный на рис. 3a, на соответствие правилу блокировки, приведенному на рис. 2. Согласно этому правилу возможна ошибка — попытка в одной последовательности дважды установить (или снять) блокировку. Сначала Slam генерирует булеву программу, как показано на рисунке 3б. Для каждого оператора в программе на Си Slam определяет влияние на предикаты правила и записывает эту информацию в булевой программе. Все выражения присваивания игнорируются, поскольку они не влияют на любой из предикатов.
На следующем шаге Slam определяет, возможен ли в булевой программе вариант выполнения, нарушающий правило SLIC. В модели нашего примера есть несколько таких вариантов; Slam начинает с кратчайшего варианта [A, A], который дважды устанавливает блокировку. Затем Slam использует символическое исполнение, чтобы определить, возможен ли данный вариант исполнения в оригинальной программе на Си. Если он возможен, значит, Slam обнаружил реальную ошибку, если же нет, Slam указывает небольшой набор предикатов, который «объясняет» невозможность этого варианта. В нашем примере Slam определяет, что данный вариант выполнения программы невозможен, поскольку он требует, чтобы условие (nPackets=npacketsOld) было одновременно истинным и ложным, и в качестве подтверждения возвращает предикат (nPackets=nPacketsOld).
Этот предикат Slam использует для улучшения своей модели (рис. 3в). Булева переменная (b) представляет предикат (nPackets=nPacketsOld). Присваивание в оригинальной программе nPacketsOld = nPackets; делает данное условие истинным, поэтому соответствующее выражение булевой программы будет выглядеть как b := true;. Slam определяет: если предикат истинен перед оператором nPackets++, то после него он будет ложным, а если предикат перед этим оператором был ложным, то после его выполнения значение предиката неизвестно. Такая связь оформляется оператором b := b ? false : *.
Улучшенная булева программа теперь содержит достаточно информации, чтобы показать, что все варианты исполнения соответствуют правилу блокировки, поскольку блокировка присутствует в цикле тогда и только тогда, когда предикат (nPackets=nPacketsOld) истинен. Если этот предикат истинен, то блокировка есть, цикл выполняется и программа снимает блокировку. Если предикат ложен, то блокировки в конце цикла нет, и цикл повторяется.
Обсуждение. Мы использовали Slam при анализе более сотни драйверов устройств для Windows на предмет выполнения свыше 30 правил и обнаружили множество ошибок. Slam успешно работает в данной предметной области, поскольку может отделять путь управления драйвером от пути передачи данных. Большинство правил, гарантирующих корректность драйвера, касаются корректного использования ресурсов ядра. Slam способен выделять часть драйвера, которая обменивается данными с аппаратным обеспечением, поэтому он может сосредоточиться на проверке корректности пути управления. Поскольку Slam успешно справляется с поиском ошибок в драйверах, отдел разработки Windows внедрил этот инструментарий.
ESP
Инструментарий выявления ошибок с помощью масштабируемого анализа программ (scalable program analysis, ESP) почти аналогичен Slam — за исключением того, что он ориентирован на анализ очень больших исходных текстов [4]. Его методика глобального анализа также отличается от методики Slam и жертвует точностью ради масштабируемости.
ESP предлагает прагматическое решение проблемы анализа больших программ за счет объединения точного анализа внутри компонентов с менее точным, но более масштабируемым анализом между компонентами. ESP гарантирует, что программа на Си или C++ соответствует набору правил, написанных независимо на простом языке Object Property Automata Language (OPAL), которые объединяют машины конечных состояний с синтаксическими шаблонами кода. ESP основан на надежном анализе, поэтому находит все случаи возникновения конкретной ошибки.
Правила OPAL. Рассмотрим код, который, в зависимости от условий, открывает и закрывает два файла:
void main () {
if (dump1) /* B1 */
fil1 = fopen(dumpFile1,»w»);
if (dump2) /* B2 */
fil2 = fopen(dumpFile2,»w»);
if (flag) x = 0;
else x = 1;
if (dump1) /* B3 */
fclose(fil1);
if (dump2) /* B4 */
fclose(fil2);
}
Код, который манипулирует файлом, должен соответствовать хорошо известным правилам. В частности, вызов fclose может закрыть файл только в том случае, если он не был закрыт раньше. Формально OPAL записывает эти правила так, как показано на рис. 4.
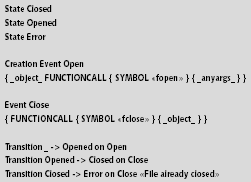
|
| Рис. 4. Правила OPAL для открытия и закрытия файлов |
Спецификация OPAL состоит из двух частей. Первая содержит машину конечных состояний, имеющую три состояния, два события и преобразования состояний, помеченные событиями. Вторая часть представляет собой синтаксические шаблоны, идентифицирующие события. Сохраняющие состояние дескрипторы файлов создаются по событию Open, которое инициируется вызовом fopen, и закрываются по событию Close. Дескрипторы файлов, которые создают событие Open, переводятся в состояние Opened.
OPAL — интуитивно понятный, построенный на правилах язык. Он способен выражать только те свойства, которые действительно можно проверить.
Механизм анализа ESP. Основную идею анализа ESP можно объяснить с помощью представленной спецификации и примера OPAL, приведенного на рис. 4. Один из способов анализа кода состоит в символической оценке каждого варианта выполнения программы. Для каждого такого варианта ESP поддерживает символическое состояние, в котором хранится все, что известно о выполнении программы. Кроме того, этот механизм способен обновлять машину конечных состояний при возникновении любого события в варианте исполнения программы. В приведенном на рисунке коде OPAL, например, такой подход позволяет распознать корреляцию между ветвями B1 и B3. К сожалению, данная методика неэффективна с практической точки зрения, поскольку с каждой ветвью число символических состояний может удваиваться.
В качестве альтернативы допускается избегать проверки вариантов исполнения за счет связывания состояний с местонахождением в программе. В таком случае анализ эффективен, но генерируется слишком много сообщений о ложных ошибках. В нашем примере инструментарий такого рода способен сообщить лишь о том, что файл может быть не открыт в момент вызова двух операторов fclose, поскольку инструментарий не в состоянии проследить корреляцию между предикатами и состоянием файла.
Мы основали алгоритм ESP на том, что конкретное правило не затрагивает большинство ветвей. В нашем примере промежуточный условный оператор не влияет на поведение файла. ESP идентифицирует и отслеживает подходящие ветви согласно правилу, в соответствии с которым на условный оператор правило распространяется, если при выполнении данной ветви машина конечных состояний, связанная с объектом, переходит в другое состояние. Когда это происходит, код, расположенный далее в программе, может снова использовать корреляцию между ветвью и состоянием машины. ESP отслеживает такую корреляцию и не объединяет информацию из двух ветвей. Если же состояние машины в обоих путях идентично, ESP объединяет информацию и прекращает отслеживать корреляцию с ветвями. Это эвристическое правило приводит к алгоритму, время работы которого растет как полином, что достаточно эффективно для больших программ.
Еще один важный аспект анализа — определить, будет ли событие инициировать изменение в машине конечных состояний для контролируемого объекта. Например, меняет ли fclose(fil2) состояние FILE fil1? ESP позволяет получить ответы на такие вопросы, выполняя детальный анализ ссылок (проверяя, не ссылаются ли они на один и тот же объект) и прослеживая передачу значений в программе.
Обсуждение. Мы использовали ESP для поиска переполнений буфера в коде крупномасштабной системы и для проверки свойств защиты ядра ОС. Последний случай демонстрирует преимущества ESP: этот инструментарий проверяет все варианты исполнения программы в коде, состоящем из миллиона строк, на соответствие более чем 500 свойствам, что занимает лишь по несколько минут на каждое свойство. Из ошибок, обнаруженных ESP, лишь 25 оказалось ложными.
Vault
Vault реализует иной подход, нежели Slam и ESP, добавляя возможности выявления ошибок в сам язык программирования, а не реализуя эти возможности в отдельном инструменте [5]. Язык Vault представляет собой безопасную версию Си. Его система типов позволяет разработчикам записывать правила использования в сигнатуре типов интерфейса, и его модуль проверки типов гарантирует, что клиентский код, использующий этот интерфейс, соответствует правилам. Как и в случае со Slam и ESP, правила Vault описывают ограничения на порядок выполнения.
Существенное отличие Vault от других инструментальных средств заключается в модульной проверке Vault, которая дает разработчикам возможность независимо проверять единицы компиляции (функции). Как и при традиционной проверке типов, проверка типов в Vault эффективна, и ее можно расширять до поддержки программ любого размера. Недостаток Vault заключается в том, что программист должен поддерживать больше аннотаций. Как и в случае деклараций типов данных, эти аннотации описывают намерения разработчика и позволяют модулю проверки быстро и локально устанавливать корректность свойств. Более того, аннотации позволяют Vault находить ошибки максимально рано, когда разработчики впервые компилируют свой код.
Примеры с сокетами. Рассмотрим, например, хорошо известный прикладной программный интерфейс сокетов, который разделяет процесс установки соединений на несколько шагов. Самая распространенная ошибка — пропуск одного или нескольких из этих шагов. Жирным шрифтом на рис. 5 в интерфейсе Vault выделен код, описывающий эти правила.

|
| Рис. 5. Выделенные аннотации указывают контролируемую переменную и определяют состояние машины, которое описывает приемлемые последовательности операций над переменными данного типа |
Интерфейс Vault связывает абстрактные состояния (raw, named, listening, ready) с программными объектами с целью реализации последовательности шагов, требующихся для создания соединения. Функция socket создает новый сокет. Ее аннотация, tracked(@raw), указывает Vault на необходимость во время компиляции проконтролировать (track) возвращаемое значение состояния, которое в начальный момент имеет значение raw. В последовательно контролируемых аннотациях имя в скобках — это ключ (key), представляющий собой имя переменной времени компиляции, ссылающееся на объект в конкретной точке. Описание воздействия функции выражает пред- и постусловия для состояния объекта. Например, функция receive требует, чтобы ее сокет был в состоянии ready, а функция bind меняет сокет с требуемого состояния raw на состояние named.
Это упрощенный интерфейс, поскольку он игнорирует возможность некорректного выполнения. В действительности, функция bind возвращает код ошибки, указывающий, насколько успешно была выполнена операция. Если bind завершена успешно, новое состояние сокета — это name, в противном случае оно остается raw. Мы можем описать такую ситуацию точно с помощью чуть более сложной сигнатуры:
variant status
[ `Ok {K@named}
| `Error(error_code) {K@raw} ];
tracked status
bind(tracked(S) sock, sockaddr)
[-S@raw];
Статус типа variant имеет два конструктора: `Ok — для случая успеха, а `Error — для случая неудачи (включает в себя код ошибки, объясняющий, в чем она состоит). Оба конструктора принимают ключ K, который идентифицирует объект сокет. В конструкторе `Ok сокет имеет состояние named, а в `Error — состояние raw. Описание воздействия функции bind утверждает, что при входе сокет должен находиться в состоянии raw, но оно отсутствует при выходе (о чем свидетельствует знак «-»). Статус результата, по существу, закрывает доступ к сокету после вызова. Тип variant результата заставляет разработчика проверить статус, возвращаемый bind, чтобы возобновить доступ к сокету. Такой подход гарантирует, что в случае некорректного выполнения bind об этом станет известно.
Выразительность. Vault описывает не только протоколы конечных состояний объекта. Последний может находиться в одном из многих состояний (хотя их число конечно). Сигнатуры функций выражают предусловия на состояние объекта и описывают, как состояние объекта меняется в результате вызова. Кроме того, Vault может указывать протоколы резервирования и освобождения ресурсов через аннотации, которые явно определяет, когда объекты создаются и когда становятся недоступными. Модуль проверки в Vault гарантирует, что на недоступные объекты сослаться невозможно.
С помощью этих механизмов Vault способен обеспечить безопасность работы с памятью даже для программ, использующих явное освобождение ресурсов (такое как free) и не обращающихся к функции сборки мусора. Вкупе с его достоинствами, как языка общего, назначения это уникальное свойство превращает Vault в эффективный инструментарий для написания безопасного низкоуровневого системного кода. Даже в языках, рассчитанных на сборку мусора, обеспечение корректного управления ресурсами дает свои преимущества. В них многие ресурсы, такие как дескрипторы файлов, соединения с базами данных и т. д., должны быть явно освобождены в коде программы. Vault может контролировать эти ресурсы и проверять корректность работы с ними.
Проверка. Vault отдельно проверяет каждую функцию программы. Результат действия функции преобразуется в предусловие и постусловие для каждого параметра объекта. Модуль проверки анализирует потоки управления и потоки передачи данных во всех вариантах выполнения программы. В каждой инструкции он проверяет все специфические для данного выражения условия на их соответствие состоянию объекта времени компиляции. Это происходит следующим образом.
- После каждой инструкции он удостоверяется, что ни один из объектов не стал недоступным, и в результате не возникла утечка памяти.
- При вызове функции он устанавливает, что текущее состояние удовлетворяет предусловию функции. В этом случае текущее состояние обновляется с помощью постусловия функции.
- В точках слияния управляющих потоков модуль определяет, согласуются ли состояния входящих потоков.
- Наконец, если функция существует, модуль проверяет, согласуется ли состояние с постусловием функции.
Проверка — быстрая, простая и выполнимая операция, поскольку модуль проверки поддерживает большое количество инвариантов. Если, к примеру, в некоторой точке программы есть два контролируемых объекта, которые помечены ключами с различными именами, то объекты также будут различны. Это свойство (игнорирование использования псевдонимов для контролируемых объектов) позволяет модулю проверки следить за состоянием объектов, не делая чересчур консервативных предположений о том, что два указателя ссылаются на один и тот же объект.
Инструментальные средства проверки корректности программ помогают нашим разработчикам находить и исправлять ошибки, и мы работаем над созданием новых инструментов, которые выявляют другие типы ошибок и проще расширяются. Кроме того, в Microsoft активно работают над превращением некоторых из наших инструментов проверки корректности программ в продукты, полезные для разработчиков других компаний. В будущем мы можем рассчитывать на появление программного обеспечения с правилами для формирования точных описаний, которые помогут разработчикам понять и корректно использовать прикладные программные интерфейсы.
В то же время круг задач, которые мы ставим перед этими инструментами, ограничен. Хотя они проверяют важные и необходимые свойства, они далеки от того уровня, который позволял бы с уверенностью гарантировать корректность программ. Набор свойств конечных состояний (вне зависимости от их многообразия и детализации) никогда не будет полностью описывать поведение сложного программного обеспечения.
Нам предстоит еще немало сделать, если мы хотим использовать потенциал компьютеров для совершенствования разработки программного обеспечения. Машины — достаточно производительны, память — достаточно велика, а программный анализ — достаточно хорошо разработан, чтобы создавать значительно более мощные инструменты. Глубокое понимание семантики и поведения программ в один прекрасный день позволит выпустить инструментальные средства, способные выполнять рутинные задачи и тем самым дающие возможность разработчикам и тестировщикам сосредоточиться на творческих аспектах создания программного обеспечения.
Литература
- S.C. Johnson. Lint, a C Program Checker. Unix Programmer?s Manual, AT&T Bell Laboratories, 1978.
- W.R. Bush, J.D. Pincus, D.J. Sielaff. A Static Analyzer for Finding Dynamic Programming Errors, Software Practice and Experience, vol. 30, №. 7, 2000.
- T. Ball, S.K. Rajamani. The Slam Project: Debugging System Software via Static Analysis, Proc. 29th ACM SIGPLAN-SIGACT Symp. Principles of Programming Languages (POPL 2002), ACM Press, 2002.
- M. Das, S. Lerner, M. Seigle. ESP: Path-Sensitive Program Verification in Polynomial Time. Proc. ACM SIGPLAN Conf. Programming Language Design and Implementation (PLDI 02), ACM Press, 2002.
- R. DeLine and M. Fahndrich. Enforcing High-Level Protocols in Low-Level Software. Proc. ACM SIGPLAN Conf. Programming Language Design and Implementation (PLDI 01), ACM Press, 2001.
Джеймс Ларус (larus@microsoft.com) — заместитель директора и старший научный сотрудник Microsoft Research. К области его научных интересов относятся языки программирования, компиляторы и параллельные вычисления. Томас Болл (tball@microsoft.com) — старший научный сотрудник группы Testing, Verification, and Measurement Research в Microsoft Research. К его научным интересам относятся применение программного анализа и технологии языков программирования к решению задач, связанных с обеспечением корректности и надежности программ. Манувир Дас (manuvir@microsoft.com) возглавляет в Microsoft Research исследовательскую группу Scalable Program Analysis. Среди его основных научных интересов — языки программирования и технология компиляторов, а также обеспечение надежности программ. Роберт Делайн (rdeline@microsoft.com) — программный инженер Microsoft Research. В последнее время его деятельность связана со статическими инструментальными средствами, используемыми для проверки корректности программного обеспечения. Мануэль Фендрих (maf@microsoft.com) — научный сотрудник Microsoft Research. Он специализируется на программном анализе и языках программирования. Джон Пинкус (jpincus@microsoft.com) — старший научный сотрудник Microsoft Research. В настоящее время занимается вопросами защиты и конфиденциальности, а раньше разрабатывал и внедрял инструментальные средства, использующие программный анализ (такие как PREfix и PREfast), был одним из основателей и директором по технологиям компании Intrinsa. Шрирам Раджамани (sriram@microsoft.com) возглавляет в Microsoft Research группу Software Productivity Tools. К области его научных интересов относятся инструментальные средства и технологии создания надежных систем. Раманатан Венкатапати — менеджер исследовательских разработок Microsoft Research. К его научным интересам относятся программный анализ и разработка инструментальных средств грамматического анализа и защиты.
James Larus, Thomas Ball, Manuvir Das, Robert DeLine, Manuel Fahndrich, Jon Pincus, Sriram Rajamani, Ramanathan Venkatapathy. Righting Software. IEEE SOFTWARE, May/June 2004. IEEE Computer Society, 2004, All rights reserved. Reprinted with permission.
Смежные работы
Существует множество инструментальных средств статического анализа, предназначенных для поиска ошибок в программах. К их числу можно отнести самые разные решения — от эвристических инструментов, таких как Unix-утилита Lint [1] и ее более современных преемников (скажем, LCLint [2] и Metal [3]), до средств, основанных на корректирующем анализе программ (доказательство теорем [4], проверка корректности моделей [5], теория типов [6], интерпретация абстракций [7]).
PREfix, первый инструмент поиска ошибок от Microsoft, отличается от других эвристических инструментов тем, что способен выполнять межпроцедурный анализ программ, содержащих десятки миллионов строк, поддерживает все функции C++ и имеет обширные возможности фильтрации ошибок. В последующих инструментальных средствах коррекции ошибок, предложенных Microsoft, были реализованы новые технологии наподобие проверки программных моделей, служащие для выполнения анализа корректности программ коммерческого уровня — как по размеру, так и по сложности.
Литература
- S.C. Johnson. Lint, a C Program Checker. Unix Programmer?s Manual, AT&T Bell Laboratories, 1978.
- D. Evans et al. LCLint: A Tool for Using Specifications to Check Code. Proc. ACM SIGSOFT 2nd Symp. Foundations of Software Eng., ACM Press, 1994.
- D. Engler et al. Checking System Rules Using System-Specific, Programmer-Written Compiler Extensions. Proc. 4th Symp. OS Design and Int?l (OSDI 2000), ACM Press, 2000.
- C. Flanagan et al. Extended Static Checking for Java. Proc. ACM SIGPLAN Conf. Programming Language Design and Implementation, ACM Press, 2002.
- J. Hatcliff, M. Dwyer. Using the Bandera Tool Set to Model-Check Properties of Concurrent Java Software. Proc. 12th Int?l Conf. Concurrency Theory (CONCUR 2001), LNCS 2154, Springer-Verlag, 2001.
- T. Jim et al. Cyclone: A Safe Dialect of C. Proc. Usenix Ann. Conf., Usenix Assoc., 2002.
- B. Blanchet et al. A Static Analyzer for Large Safety-Critical Software. Proc. ACM SIGPLAN Conf. Programming Language Design and Implementation (PLDI 03), ACM Press, 2003.
