
Компьютерная лингвистика — раздел науки, изучающий применение математических моделей для описания лингвистических закономерностей. Ее можно разделить на две большие части. Одна из них изучает способы применения вычислительной техники в лингвистических исследованиях — применение известных математических методов (например, статистическая обработка) для выявления закономерностей. Обнаруженные закономерности используются другой частью, изучающей вопросы осмысления текстов, написанных на естественном языке, — создание математических моделей для решения лингвистических задач и разработка программ, функционирующих на основе этих моделей. Эта часть компьютерной лингвистики тесно соприкасается с разделом искусственного интеллекта, занимающегося разработкой систем обработки текстов на естественном языке.
Общая схема обработки текстов (рис. 1) инвариантна по отношению к выбору естественного языка. Независимо от того, на каком языке написан исходный текст, его анализ проходит одни и те же стадии. Первые две стадии (разбиение текста на отдельные предложения и на слова) практически одинаковы для большинства естественных языков. Единственное, где могут проявиться специфичные для выбранного языка черты, - это обработка сокращений слов и обработка знаков препинания (точнее, определение того, какие из знаков препинания являются концом предложения, а какие нет).
 |
| Рис. 1. Общая схема обработки текста |
Последующие две стадии (определение характеристик отдельных слов и синтаксический анализ), напротив, сильно зависят от выбранного естественного языка. Последняя стадия (семантический анализ) также мало зависит от выбранного языка, но это проявляется только в общих подходах к проведению анализа.
Семантический анализ основывается на результатах работы предыдущих фаз обработки текста, которые всегда специфичны для конкретного языка. Следовательно, способы представления их результатов тоже могут сильно варьироваться, оказывая большое влияние на реализацию методов семантического анализа. Результаты анализа, произведенного на ранних стадиях, могут быть многозначны: для выходных параметров указывается не одно, а сразу несколько возможных значений (скажем, может существовать несколько способов трактовки одного и того же слова). В таких случаях последующие стадии должны выбирать наиболее вероятные значения результатов ранних стадий анализа и уже на их основе проводить дальнейший анализ текста.
Рассмотрим детальнее каждую из стадий анализа текста после разделения текста на отдельные слова и предложения. К первой стадии (анализ отдельных слов) относится морфологический анализ (определение морфологических характеристик каждого слова — часть речи, падеж, склонение, спряжение и т.д.) и морфемный анализ (приставка, корень, суффикс и окончание); ко второй стадии — синтаксический анализ; к третьей — различные задачи семантического анализа (поиск фрагментов, формализация, реферирование и т.д.).
Анализ отдельных слов
В эту стадию обработки входят морфологический и морфемный анализы слов. Входным параметром является текстовое представление исходного слова. Целью и результатом морфологического анализа является определение морфологических характеристик слова и его основная словоформа. Перечень всех морфологических характеристик слов и допустимых значений каждой из них зависят от естественного языка. Тем не менее, ряд характеристик (например, название части речи) присутствуют во многих языках. Результаты морфологического анализа слова неоднозначны, что можно проследить на множестве примеров.
Существует три основных подхода к проведению морфологического анализа. Первый подход часто называют «четкой» морфологией; для русского языка он основан на словаре Зализняка [1]. Второй подход основывается на некоторой системе правил, по заданному слову определяющих его морфологические характеристики; в противоположность первому подходу его называют «нечеткой» морфологией [2]. Третий, вероятностный подход, основан на сочетаемости слов с конкретными морфологическими характеристиками [3]; он широко применяется при обработке языков со строго фиксированным порядком слов в предложении и практически неприменим при обработке текстов на русском языке. Рассмотрим все три способа морфологического анализа подробнее.
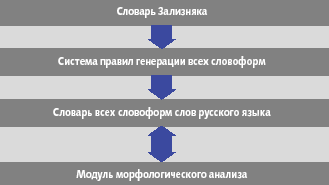
Словарь Зализняка содержит основные словоформы слов русского языка, для каждой из которых указан определенный код. Известна система правил, с помощью которой можно построить все формы данного слова, отталкиваясь от начальной словоформы и соответствующего ей кода. Помимо построения каждой словоформы, система правил автоматически ставит в соответствие ей морфологические характеристики. При проведении четкого морфологического анализа необходимо иметь словарь всех слов и всех словоформ языка. Этот словарь на входе принимает форму слова, а на выходе выдает его морфологические характеристики. Данный словарь можно построить на основе словаря Зализняка по очевидному алгоритму: перебрать все слова из словаря, для каждого из них определить все возможные их словоформы и занести их в формирующийся словарь.
 |
| Рис. 2. Морфологический анализ на основе словаря Зализняка |
При таком подходе для проведения морфологического анализа заданного слова (рис. 2) необходимо просто найти его в словаре, где уже хранятся точные, «окончательно известные» значения всех его морфологических характеристик. Для одного и того же входного слова могут встретиться сразу несколько вариантов значений его морфологических характеристик.
К сожалению, этот способ применим не всегда: слова, поступающие на вход, могут не входить в словарь всех словоформ. Такая ситуация может возникнуть из-за ошибок ввода исходного текста, из-за наличия в тексте имен собственных и т.д. В случае, когда метод не дает нужного результата, применяется нечеткая морфология.
 |
| Рис. 3. Морфемный анализ |
Целью морфемного анализа слова является разделение слова на приставки, корни, суффиксы и окончания (рис. 3). В словаре морфем русского языка [4, 5] указано разделение каждого слова на отдельные части, но не указаны типы каждой из них — какая из них является приставкой, какая корнем и т.д. Множество всех корней слов русского языка открыто, но множество всех возможных приставок, суффиксов и окончаний ограничено; кроме того, известно, что в любом слове сначала идут приставки, затем корни, далее суффиксы и окончания. Поэтому на основе словаря морфем русского языка можно построить другой словарь, который будет содержать не только разбиение каждого слова на части, но и тип каждой из них. В таком случае, для проведения морфемного анализа слова необходимо обратиться к этому словарю.
Морфемный анализ не ограничивается обращениями к словарю. В ситуации, когда слово отсутствует в словаре, возможно непосредственное проведение анализа на основе стандартного строения слов русского языка (приставка — корень — суффикс — окончание) и множества всех приставок, суффиксов и окончаний.
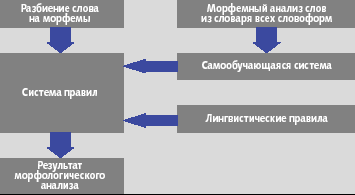
Вернемся к морфологическому анализу слова в той ситуации, когда не удалось определить характеристики слова с помощью методов четкой морфологии, но удалось расчленить его на части. Наличие тех или иных лексем может определять морфологические характеристики слова: можно построить систему правил, которая будет опираться на наличие или отсутствие каких-либо частей и выдавать одно или несколько предположений о морфологических параметрах. Такой набор правил можно построить двумя способами. Первый основан на морфемном анализе слов, содержащихся в словаре всех словоформ, и их морфологических характеристик. Рассмотрим эту задачу формальнее: известны пары значений, состоящие из морфемного строения слова и его морфологических характеристик. Это есть не что иное, как «вход» и «выход» системы правил, которая по морфемному строению слова будет определять его морфологические характеристики. Задачу построения такой системы правил можно решить с помощью самообучающейся системы (рис. 4). Для ее реализации могут быть использованы деревья решений, программирование на основе индуктивной логики (ILP, Inductive Logic Programming) или другие алгоритмы.
 |
| Рис. 4. Нечеткий морфологический анализ |
Второй подход состоит в формировании набора правил вручную. По большому счету, его реализация — ничто иное, как написание экспертной системы диагностирующего типа.
Вероятностный способ [6] проведения морфологического анализа слов состоит в следующем. Одна и та же словоформа может принадлежать сразу к нескольким грамматическим классам. Для каждой словоформы определяются все ее грамматические классы, а также вероятность ее отношения к каждому из этих классов. Это выполняется на основе некоторого набора документов, где каждому слову предварительно поставлен в соответствие грамматический класс. После этого вычисляются вероятности сочетаний определенных грамматических классов для слов, стоящих рядом — для двоек, троек, четверок и т.д. На основе этих чисел может проводиться анализ слов, но для него необходимо уже не только само слово, но и стоящие рядом с ним слова.
Необходимо сделать два важных замечания. Во-первых, вероятностный метод применим только для тех языков, у которых четко фиксирован порядок слов в предложении. Если же порядок слов можно изменять, то все возможные сочетания грамматических классов будут практически равновероятны. Во-вторых, если первые два способа анализа (четкая и нечеткая морфология) на входе принимают отдельные слова, то вероятностный способ, напротив, на входе принимает либо все предложение, либо, по крайней мере, несколько стоящих рядом слов.
Анализ отдельных предложений
После того как произведен анализ каждого слова, начинается анализ отдельных предложений (синтаксический анализ), позволяющий определить взаимосвязи между отдельными словами и частями предложения (рис. 5). Результатом такого анализа является граф, узлами которого выступают слова предложения; при этом, если два слова связаны каким-либо образом, то соответствующие им вершины графа связаны дугой с определенной окраской. Возможные окраски дуг зависят от языка, на котором написано предложение, а также от выбранного способа представления синтаксической структуры предложения.
При синтаксическом анализе предложений русского языка в качестве окрасок дуг можно использовать вопросы, задаваемые от одного слова к другому. В вершинах графа слова пишутся не в том виде, в котором они встречаются в предложении, а в своей основной словоформе. Некоторым словам (например, предлогам) вообще не соответствует ни одна из вершин графа, но эти слова влияют на вопросы, задаваемые от одного слова к другому.
Возможны и другие способы представления зависимостей между словами в предложении (например, разбор предложения по частям и выделение подлежащего, сказуемого и т.д.). На основе системы этих зависимостей могут быть разработаны иные способы представления синтаксической структуры предложения [7].
Перейдем к методам синтаксического анализа предложений. Их можно разделить на две группы: методы с фиксированным, заранее заданным набором правил и самообучающиеся методы. Правила представляются не в виде классических продукций («если ..., то ...»), а в виде грамматик, задающих синтаксис языка. Исторически, первым способом описания синтаксиса языка были формальные грамматики [8]. Они задаются в виде четырех компонентов: множество терминальных символов, множество нетерминальных символов, правила вывода и начальный символ. Формальные грамматики хорошо изучены и широко применяются при описании формальных языков (например, языков программирования), но непригодны для описания синтаксиса естественных языков.
Трансформационные грамматики [8] разрабатывались уже специально для задания синтаксических правил построения предложений, написанных на естественном языке. Такие грамматики задаются в виде ориентированного графа состояний, всем дугам которого поставлены в соответствие определенные части речи. В начале работы алгоритм синтаксического анализа находится в некотором начальном состоянии; ему соответствует некоторая вершина графа. Алгоритм просматривает предложение слева направо, анализирует встречающиеся слова и делает переходы из одного состояния в другое в соответствии с выходящими из текущей вершины дугами и очередным словом предложения. Работа алгоритма заканчивается, когда предложение просмотрено полностью, либо когда невозможно сделать переход из текущего состояния (нет выходящей дуги с необходимой пометкой).
К сожалению, трансформационные грамматики не способны задавать рекурсивные синтаксические правила; кроме того, построение таких грамматик даже для небольшого подмножества языка требует больших усилий.
Оба описанных подхода заключают в себе четко заданную систему правил, согласно которым производится синтаксический анализ предложения. Помимо уже указанных недостатков они имеют еще один большой минус, который состоит в их неспособности анализировать неправильно построенные предложения. Это привело к созданию новых методов синтаксического анализа, основанных на вероятностном подходе; к ним относятся вероятностные грамматики и вероятностный разбор.
Вероятностные грамматики [6] расширяют формальные грамматики: каждому правилу построения предложения указана некоторая вероятность применения этого правила. После того, как произведен синтаксический анализ предложения, становится известно, на основе каких правил оно было построено, и на основе сопоставленных с ними вероятностей может быть посчитана «суммарная» вероятность. Конечно, одно и то же предложение может быть разобрано несколькими способами; для каждого из них считается его «суммарная» вероятность и выбирается наиболее вероятный способ построения предложения. Этот метод позволяет анализировать неправильно построенные предложения; однако он, как и два предыдущих, включает в себя систему заранее задаваемых правил.
Синтаксический анализ на основе обучающихся систем — пока еще малоизученный подход. Он заключается в следующем. Разрабатывается множество примеров, содержащих пару — исходное предложение и результат его синтаксического анализа. Этот результат вводится человеком, занимающимся обучением системы, в ответ на каждое подаваемое на вход предложение. Затем, при подаче на вход предложения, не входящего в список примеров, система сама генерирует результат. Для реализации такой обучающейся системы используются такие методы, как нейронные сети, деревья вывода, ILP и методы поиска ближайшего соседа.
Это далеко не весь спектр методов синтаксического анализа. Удовлетворительных решений данного вопроса пока еще не найдено, хотя есть методы, дающие неплохие результаты, но работающие только на подмножестве языка [7]. Решение задачи синтаксического анализа текста должно послужить основой, во-первых, для построения более совершенных синтаксических корректировщиков (программные средства, проверяющие правильность построения предложения) и, во-вторых, для построения алгоритмов более качественного семантического анализа текстов.
Семантический анализ
Семантический анализ текста базируется на результатах синтаксического анализа, получая на входе уже не набор слов, разбитых на предложения, а набор деревьев, отражающих синтаксическую структуру каждого предложения. Поскольку методы синтаксического анализа пока мало изучены, решения целого ряда задач семантической обработки текста базируются на результатах анализа отдельных слов, и вместо синтаксической структуры предложения, анализируются наборы стоящих рядом слов.
Большинство методов семантического анализа, так или иначе, работают со смыслом слов. Следовательно, должна быть какая-то общая для всех методов анализа база, позволяющая выявлять семантические отношения между словами. Такой основой является тезаурус языка. На математическом уровне он представляет собой ориентированный граф, узлами которого являются слова в их основной словоформе. Дуги задают отношения между словами и могут иметь ряд окрасок.
- Синонимия. Слова, связанные дугой с такой окраской, являются синонимами.
- Антонимия. Слова, связанные дугой с такой окраской, являются антонимами.
- Гипонимия. Дуги с такой окраской отражают ситуацию, когда одно слово является частным случаем другого (например, слова "мебель" и "стол"). Дуги направлены от общего слова к более частному.
- Гиперонимия. Отношение, обратное к гипонимии.
- Экванимия. Дугами с такой окраской связаны слова, являющиеся гипонимами одного и того же слова.
- Амонимия. Слова, связанные таким отношением, имеют одинаковое написание и произношение, но имеют различный смысл.
- Паронимия. Данный тип дуги связывает слова, которые часто путают.
- Конверсивы. Слова, связанные такой окраской, имеют "обратный смысл" (например, "купил" и "продал").
Таким образом, тезаурус задает набор бинарных отношений на множестве слов естественного языка. В настоящий момент создан тезаурус английского языка [9]; для русского языка работа по созданию тезауруса еще не завершена, хотя имеются коммерческие продукты, включающие в себя тезаурус подмножества русского языка [2], а также отдельные словари синонимов [10] и антонимов [11] для подмножества русского языка. К сожалению, в электронном виде эти словари пока не доступны.
Семантический анализ текста включает в себя ряд практически важных задач. Поэтому рассмотрим не методы анализа, а актуальные задачи и уже существующие их решения. Одна из наиболее изученных задач — контекстно-свободный поиск текстовой информации [12]. Ее смысл заключается в следующем: имеется большой набор файлов, содержащих тексты на некотором естественном языке, и задана некоторая строка. Необходимо найти все файлы, в которых она встречается или похожая текстовая информация. В подавляющем большинстве случаев необходим именно «нечеткий» поиск (т.е. поиск по смыслу слова с учетом специфики естественного языка). Большинство существующих систем основываются исключительно на морфологическом анализе слов и не задействуют более сложных схем анализа.
Наиболее важная задача — извлечение информации из текстов и представление ее в виде формальной системы знаний (в частности, в виде семантической сети). Выполнен ряд экспериментальных разработок в данном направлении, ориентированных на конкретные предметные области, однако коммерческих программных продуктов нет. Рассмотрим эту задачу подробнее.
Имеется семантическая сеть [8], состоящая из узлов и связей; каждому из узлов соответствуют некоторые атомарные данные, а каждой дуге — некоторая окраска. Если семантическая сеть построена на основе анализа некоего текста и является формализованным представлением содержащихся в нем знаний, то каждому ее элементу соответствует определенный фрагмент исходного текста. Узлам, отражающим одинаковые по смыслу данные (скажем, вес, возраст, дата рождения), соответствуют аналогичные по синтаксическому строению фрагменты исходного текста. Значит, можно ввести шаблоны, описывающие синтаксическую структуру части исходного текста и создаваемые элементы семантической сети. При описании синтаксической структуры указываются не только связи слов в предложении, но и условия, накладываемые на каждое из слов. Эти условия могут проверять как морфологические или семантические (на основе тезауруса) характеристики слова, так и смысловые пометки этого слова, поставленные при поиске других шаблонов. Если какая-то часть текста удовлетворяет всем указанным в шаблоне условиям, то происходит ее формализация.
Извлечение информации из текстов — основа для «раскопки» текста [13], а также для создания систем загрузки текстов в хранилища данных. Подобные системы существуют и предназначены для интеграции и очистки данных, помещаемых в хранилища, но они не предоставляют никаких средств ввода данных, содержащихся в текстовом виде.
Наряду с извлечением информации существует и обратная задача генерации правильно построенных текстов [14]. Исходными данными для таких систем является четко формализованные знания. На первый взгляд, эта задача может показаться странной, ведь в большинстве случаев формализованные знания можно представлять в виде бланков, имеющих четкую, заранее определенную систему полей. Но это не всегда так. Если предметная область имеет сложную и разветвленную структуру, то большинство полей бланка часто оказываются пустыми, сильно затрудняя восприятие информации; для конченого пользователя было бы гораздо проще и удобнее иметь дело не с такими бланками, а с неформализованным (но корректно построенным) текстовым описанием тех же самых данных.
С целью поиска решения двух указанных задач интересно рассмотреть методы обработки текстовой информации, разработанные Шенком [8]. Они образуют психолингвистический подход к анализу текстовой информации и основываются на двух идеях. Во-первых, для анализа одного предложения не обязательно рассматривать все его слова: смысл предложения можно определить по «ключевым» словам и наличию связей между ними. Вторая идея заключается в представлении результатов анализа текста в виде концептуальной сети, способной формально описать смысл, содержащийся в исходном тексте и являющейся семантической сетью с предопределенным набором типов узлов и дуг.
Еще две известные задачи обработки текстовой информации — автоматическое реферирование и автоматический машинный перевод.
Основные требования, предъявляемые к реферату, таковы: он должен отражать основные идеи и моменты текста, оставаясь корректно построенным текстом. Известны два основных направления в решении этой проблемы — удаление из исходного текста всех «ненужных» предложений и самостоятельное построение реферата исходного текста. Основные сложности, связанные с первым подходом, заключаются в определении ключевых предложений текста и последующем увязывании этих предложений в единый, удобочитаемый текст. Второй подход включает в себя три этапа: анализ текста и построение его формального описания; выбор из этого описания ключевых моментов; формирование реферата. На сегодняшний день имеются как научные, так и коммерческие разработки систем реферирования, способные обрабатывать русскоязычные тексты.
Автоматический машинный перевод — одна из старейших задач искусственного интеллекта. К настоящему времени представлено множество коммерческих систем, способных переводить несложные тексты.
***
Задачи обработки текстов возникли практически сразу после появления вычислительной техники. Несмотря на полувековую историю исследований в области искусственного интеллекта, накопленный опыт вычислительной лингвистики, огромный скачок в развитии ИТ и смежных дисциплин, удовлетворительного решения большинства практических задач обработки текста пока не найдено. Однако ИТ-индустрия потребовала удовлетворительного решения некоторых задач обработки текстов. Так, развитие хранилищ данных делает актуальными задачи извлечения информации и формирования корректно построенных текстовых документов. Бурное развитие Internet повлекло за собой создание и накопление огромных объемов текстовой информации, что требует создания средств полнотекстового поиска и автоматической классификации текстов (в частности, программные средства для борьбы со спамом), и если первая задача более или менее удовлетворительно решена, то до решения второй пока еще далеко.
В последнее время, благодаря развитию систем документооборота, наличию множества постоянно обновляемых юридических справочников, ряду других факторов, наблюдается накопление массивов специализированных (но не формализованных) текстовых документов. По аналогии со структурированной информацией, когда усовершенствование средств анализа вылилось в появление хранилищ данных, развитие систем документооборота со временем может потребовать создания полнотекстовых хранилищ, дающих возможность всестороннего анализа и исследования неформализованных текстов на естественном языке. n
- Зализняк А.А. Грамматический словарь русского языка. Словоизменение. 3-е изд. М. Русский язык, 1987.
- Гарант-Парк-Интернет. Технологии анализа и поиска текстовой информации.
- SRILM - The SRI Language Modeling Toolkit.
- Тихонов А.Н. Морфемно-орфографический словарь: Русская морфемика. М. Школа-Пресс, 1996
- Кузнецова А.И., Ефремова Т.Ф. Словарь морфем русского языка. М. Русский язык, 1986.
- C. Manning, H. Schutze. Foundations of Statistical Language processing. The MIT Press, 1999.
- Т.А. Грязнухина, Н.П. Дарчук, В.И. Критская, Н.П. Маловица и др. Синтаксический анализ научного текста на ЭВМ, К.: Научная мысль, 1999.
- Хант Э. Искусственный интеллект. Пер. с англ. -М.: Мир, 1978
- WordNet: a lexical database for the English language.
- Горбачевич К.С. Русский синонимический словарь СПб. ИЛИ РАН, 1996.
- Меркурьева Н. М. Словарь антонимов русского языка: Сложные слова. Около 1800 антонимических пар. М., Издательство: "Газета "Правда"", 1999
- Е. Игумнов, Основные концепции и подходы при создании контекстно-поисковых систем на основе реляционных баз данных.
- U. Nahm, R. Mooney. Mining soft-matching rules from textual data. WA, 2001.
- D. Jurafsky, James H. Martin. Speech and Language Processing: An introduction to natural language processing, computational linguistics, and speech recognition. Prentice-Hall, 2000.
Константин Селезнев (skostik@relex.ru) — старший инженер-программист НПП «Релэкс» (Воронеж).
«Невод» со смыслом
Представленный в статье материал получен в ходе выработки проектных решений для задач автоматизации сбора данных и их очистки перед укладкой в хранилище, созданное с помощью системы «Невод», служащей для построения информационно-аналитических систем. (Прочитать о ней можно, например, в статье В. Максимова, Л. Козленко, С. Маркина и И. Бойченко «Защищенная реляционная СУБД Линтер», опубликованной в журнале «Открытые системы», 1999, № 11-12.) Основываясь на реальном состоянии дел в области компьютерной лингвистики, проведенное исследование позволяет реализовать в составе хранилища данных:
- контекстно-свободный поиск текстовой информации ("поиск по смыслу");
- извлечение информации из текстовых данных и представление ее в виде формальной системы знаний;
- генерацию правильно построенных текстов;
- автоматическое реферирование и машинный перевод.
Система «Невод» и инструментарий быстрой разработки приложений LAB предназначены для создания прикладных систем, работающих с СУБД «Линтер». Разработанная в НПП «Релэкс», данная СУБД сертифицирована Гостехкомиссией на второй класс защищенности данных от несанкционированного доступа.
