
Работы, выполненные по программе СКИФ (Россия и Белоруссия), а также по национальным целевым программам, позволили освоить и развить технологии серийного создания высокопроизводительных многопроцессорных вычислительных систем (ВМВС) среднего класса с производительностью до нескольких сотен GFLOPS.
Вместе с тем, необходима организация работ по следующим направлениям:
- освоению, развитию и внедрению наукоемких технологий на базе ВМВС в промышленности и социально-экономической сфере;
- созданию системного программного обеспечения ВМВС на базе новых вычислительных моделей;
- созданию вычислительных систем следующего поколения, позволяющих достичь пиковой производительности в несколько петафлоп (1015 операций в секунду) и имеющих значительно более высокий уровень реальной производительности, чем в современных системах.
Работы по этим направлениям планируются, например, в рамках комплексной программы «Триада», а также в национальных целевых программах России и Белоруссии.
Суперкомпьютеры против кластеров
С некоторым упрощением любую современную высокопроизводительную вычислительную систему можно представить как множество многопроцессорных вычислительных узлов, связанных одной или несколькими коммуникационными сетями. Важная общая характеристика таких систем — логическая организация оперативной памяти, с которой работают вычислительные узлы. Оперативная память может быть: разделяемой для всех узлов; распределенной — доступной только для процессоров своего узла; распределенной разделяемой — доступной для процессоров своего узла и из других узлов, но с применением специальных программно-аппаратных средств.
Остановимся на позиционировании кластерных ВМВС в соответствии с их пиковой и реальной производительностью.
Основные отечественные ВМВС — это вычислительные кластеры, собранные из коммерчески доступных компонентов. Данное направление стремительно развивалось в последние годы за рубежом [1]. В нашей стране поставщиками таких систем являются НИИ «Квант» и ОАО НИЦЭВТ, входящие в Российское агентство по системам управления. Некоторые высокопроизводительные системы собираются по близким технологиям коммерческими компаниями, а более простые варианты — непосредственно пользователями. Работы по ВМВС ведутся в рамках российско-белорусской программы СКИФ.
Важные преимущества кластерных ВМВС — доступность технологий сборки и возможность экономически эффективного получения достаточно высокой производительности. Но насколько высока их производительность по отношению к тем системам, которые принято называть суперкомпьютерами?
Сегодня наивысший уровень производительности суперкомпьютеров измеряется десятками терафлоп, достигаемых на многопроцессорных векторно-конвейерных системах (NEC Earth Simulator System на базе SX-6 [2] и Cray X1 [3, 4]), массово-параллельных системах, в том числе, и системах кластерного типа от HP, IBM, Intel и Cray. Кластерные системы с числом процессоров в несколько тысяч и производительностью около 1 TFLOPS можно со всем основанием считать суперкомпьютером.
Кластерные системы с производительностью от нескольких десятков до нескольких сотен GFLOPS будем называть просто высокопроизводительными системами. Именно этот класс машин широко используется в современных высокотехнологичных отраслях промышленности, а также в социально-экономической сфере и представляет наибольший практический интерес.
При обсуждении суперкомпьютеров обычно используют термин «производительность», не всегда при этом уточняя, какая это производительность — пиковая или реальная. Вообще говоря, вопрос оценки производительности ВМВС — не простая тема, заслуживающая отдельного рассмотрения [5]. Здесь лишь отметим, что ВМВС с классической векторно-конвейерной структурой, которые обычно противопоставляются кластерным системам и характеризуются как «настоящие суперкомпьютеры», имеют наивысшие показатели по пиковым характеристикам применяемых в них процессоров и подсистем оперативной памяти (рис. 1).
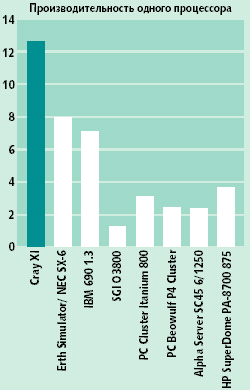 |
| Рис. 1. Пиковые характеристики процессоров и памяти современных ВМВС |
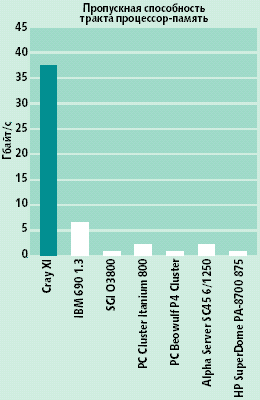 |
Высшие пиковые характеристики, особенно подсистемы памяти, позволяют на векторно-конвейерных системах получить очень высокие значения реальной производительности на векторизуемых задачах. Например, SX-6 при выполнении пакета инженерных расчетов Nastran в несколько раз превосходит производительность лучших MPP-систем. Другой пример: тест Linpack, по которому составляется Top500, хорошо векторизуется, поэтому векторно-конвейерные системы занимают высшие позиции в этом рейтинге. Реальная производительность на этой задаче достигает 90% от пиковой, что позволяет развивать большую скорость вычислений на небольшом числе процессоров; нагрузка на коммуникационную сеть здесь не так велика, как в MPP-системах.
Между тем, векторизуемые задачи — далеко не единственные, требующие высокопроизводительных средств, а Linpack — вовсе не бесспорная оценочная программа, отражающая практически важные характеристики ВМВС. Невекторизуемые задачи, допускающие распараллеливание, могут решаться на массово-параллельных ВМВС с различной организацией оперативной памяти. Залог успеха при решении таких задач — локализуемость параллельно выполняемой части задачи в кэш-памяти и небольшой рост коммуникационных потерь. Такие условия хорошего распараллеливания объясняются, прежде всего, свойством современных микропроцессоров показывать высокие характеристики лишь при эффективном использовании кэш-памяти, а также все еще недостаточно высокими скоростями коммуникационных сетей. На рис. 2 показана типичная зависимость реальной производительности микропроцессора от объема обрабатываемых данных и характерное изменение скорости вычислений и коммуникационных потерь при распараллеливании. Вторую зависимость целесообразно рассмотреть подробнее.
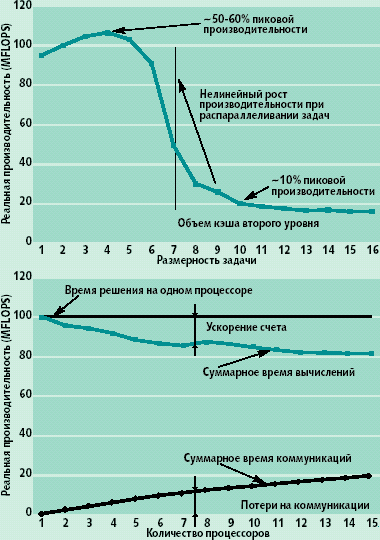 |
| Рис. 2. Зависимость реальной производительности процессора вычислительного узла от объема обрабатываемых данных и изменение скорости вычислений и коммуникационных потерь при распараллеливании |
Приведенная на рисунке зависимость строится следующим образом. На всех процессорах измеряется время, расходуемое на коммуникации, до и после обращения к функциям библиотеки передачи сообщений расставляются обращения к счетчикам времени. Доля вычислений получается для каждого процессора путем вычитания времени коммуникационных потерь из общего времени счета. Общие затраты на счет и коммуникации при построении рассматриваемой зависимости вычисляются суммированием по всем процессорам.
Если задача идеально (линейно) распараллеливается, то сумма затрат на коммуникации и вычисления с увеличением количества процессоров должна быть постоянной и равна времени счета задачи на одном процессоре. Обычно при распараллеливании происходит уменьшение времени вычислений по причине ускорения счета из-за более эффективной работы кэша, поскольку рабочий объем адресов данных при распараллеливании уменьшается. Это бывает не всегда, поскольку вместе с уменьшением объема может меняться динамика обращений и хуже работает опережающая подкачка данных в кэш, меньше используется расслоение памяти. Поэтому эффективность использования кэша не увеличивается. Эффективность кэша при вычислениях также может уменьшаться из-за увеличения объемов передаваемых данных, также прокачиваемых через кэш-память, что вносит помехи в его работу непосредственно на вычислительной части задачи.
Затраты на коммуникации при увеличении количества процессоров обычно растут. При этом, как правило, длина передаваемых сообщений уменьшается, поэтому при работе некоторого числа процессоров становится более важным время задержки передачи сообщения (Latency), а не скорость передачи (Bandwidth). В потери на коммуникации также входят и затраты на синхронизацию поставщиков и потребителей информации, происходящие из-за рассинхронизации параллельных процессов. Если увеличение скорости счета вследствие улучшения использования кэша компенсирует затраты на коммуникации, то происходит линейное ускорение. Нетрудно понять, при каких условиях в ВМВС будет «суперлинейное» и «сублинейное» ускорение.
Каковы же оценки практически достигаемой эффективности векторно-конвейерных и массово-параллельных систем? Увы, их реальная эффективность оставляет желать лучшего. Так уж сложилось, что если верхняя оценка реальной производительности оценивается посредством Linpack, то нижнюю оценку «коридора реальной производительности» ВМВС дают тестовые задачи пакета NASA NPB версии 2.3 и выше. Такая методика применяется и Центром независимого межведомственного тестирования суперкомпьютерных систем ГУ РИНКЦЭ Министерства науки, промышленности и технологий РФ. Для NPB 2.3 реальная производительность составляет обычно 5-10% от пиковой, а реальные задачи, оптимизированные для ВМВС, позволяют получить 20-40% от пиковой.
Однако сегодня ситуация с реальной производительностью еще хуже, большой интерес стали представлять алгоритмы решения задач, для которых характерна интенсивная нерегулярная работа с памятью и необходимость балансировки загрузки процессоров при счете. Это требуется, например, для перспективных расчетных алгоритмов на динамически изменяемых неструктурированных сетках, а также для множества алгоритмов, применяемых в военных системах; реальная производительность на таких задачах составляет уже 0,1-1% от пиковой. Причины столь резкого падения реальной производительности таковы: задержки выполнения операций с оперативной памятью (особенно, если она организована как общая для всех процессоров); задержки выполнения операций с коммуникационной сетью; задержки из-за рассинхронизации процессов и потерь на операционную систему, характерные для синхронных вычислительных моделей; задержки выполнения команд, обусловленные их зависимостью по управлению и по данным.
Для решения современных задач используются несколько типов ВМВС; универсального решения пока нет, для одних типов задач хороши одни системы, для других — другие. Это учитывают даже ведущие производители ВМВС, выпуская системы разного типа. Отечественные ВМВС — один из популярных подтипов выпускаемых во всем мире ВМВС; это надо четко осознавать. Одновременно, в работах над ними должна учитываться и глобальная проблема эффективности ВМВС, которая усиливается появлением новых алгоритмов и тенденциями изменения характеристик новой элементной базы — ростом разрыва скорости работы памяти и логических схем.
Одна из наиболее актуальных задач — преодоление проблемы низкой реальной производительности. Без этого невозможно создание систем петафлопного уровня, а также компактных и неэнергоемких высокопроизводительных систем для новых образцов изделий. Работы в этом направлении очень активно ведутся за рубежом, особенно в США, чего нельзя сказать о России, хотя исследования такого типа уже начались. Выполнение таких работ связано с формированием глубокого понимания существа вычислительных процессов, возникающих при решении задач, перестройкой моделей вычислений, возможностью проведения интенсивных исследований новых архитектур на имитационных моделях. В отечественных условиях это было бы невозможным без наличия кластерных ВМВС, которые сегодня имеются даже в серийном исполнении и начали использоваться в промышленности.
Вычислительные кластеры
Усилиями НИИ «Квант», ИПМ РАН и Межведомственного суперкомпьютерного центра разработан кластер класса МВС-1000М, содержащий 768 микропроцессоров Alpha 21264, объединенных коммуникационной сетью Myrinet 2000. Сегодня МВС-1000М входит в список Top 500 самых мощных компьютеров в мире.
Другая реализация — типовая кластерная система ОАО НИЦЭВТ (серия ЕС 1720), структура 12-процессорного варианта которой представлена на рис. 3. Это система среднего класса производительности, которая является типовой для промышленных применений и ориентирована на серийный выпуск. Ее вычислительные узлы — стандартные серверные платы с процессорами Pentium 4 Xeon (рассматриваются варианты использования AMD Opteron и Itanium 2), оперативной памятью до 2 Гбайт, локальными дисками и сетевыми платами Fast Ethernet, Gigabit Ethernet и основной коммуникационной сетью для передачи данных SCI (Scalable Coherent Interface, стандарт IEEE 1596). Применяются аппаратные сетевые средства компании Dolphin (Норвегия) и системное программное обеспечение от Scali (Норвегия). На опытном производстве НИЦЭВТ освоен выпуск отечественных адаптеров SCI, проведены работы по импортозамещению системных программных средств.

Рис. 3. Типовая 12-процессорная кластерная ВМВС
Топологию коммуникационной сети SCI могут образовывать двухмерный тор, трехмерный тор, либо коммутируемые через центральный коммутатор SCI-кольца вычислительных узлов. Топология «трехмерный тор» позволяет строить системы с количеством узлов более 64; имеются системы такого типа с несколькими сотнями узлов, обладающие терафлопным уровнем производительности. Топология соединяемых через коммутатор SCI-колец позволяет добиться повышенной производительности обменов типа «все-всем», что важно, например, для решения задач имитационного моделирования.
Коммуникационная сеть SCI позволяет передавать данные со скоростью до 300 Мбайт/с на уровне пользовательской программы при использовании Pentium 4 Xeon/2,4 ГГц и до 390 Мбайт/с для Itanium 2. Уникальной характеристикой SCI являются малые значения задержек передачи сообщений, например, задержка передачи сообщения нулевой длины занимает всего 3,5 мкс. Рекордно мало и время групповой барьерной синхронизации — несколько микросекунд, причем с увеличением числа узлов это время увеличивается незначительно. Таким образом, сеть SCI является не только высокоскоростной, но и высокореактивной, что важно на практике при решении ряда задач, а также позволяет реализовать перспективные модели вычислений с высокой грануляцией параллельных процессов и большой асинхронностью. Из других решений такими свойствами обладает лишь значительно более дорогая сеть Quadrics, используемая в некоторых высших моделях кластерных ВМВС американской программы стратегической компьютерной инициативы ASCI.
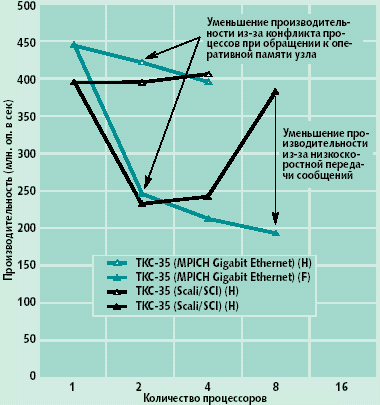 |
| Рис. 4. Типовые характеристики производительности на один процессор |
На рис. 4 приведены экспериментально полученные на кластере ТКС-35 оценки реальной производительности одного процессора в зависимости от числа процессоров, применяемых при параллельном счете. Результаты получены на задаче LU (класса сложности А) пакета NASA NPB 2.3. Это задача решения уравнения Навье-Стокса; для используемого метода решения характерно наличие большого количества передач коротких сообщений. Приводятся данные для сетей SCI и Gigabit Ethernet при условии использования одних и тех же вычислительных узлов с двумя процессорами Pentium 4 Xeon/2,4 ГГц и 400-мегагерцевой системной шиной. Характеристики с индексом H соответствуют режиму использования при решении одного процессора вычислительного узла, а с индексом F — двух процессоров.
Более высокое качество сети SCI сказывается при использовании уже двух процессоров, а особенно заметно при 8 процессорах. Резкий рост реальной производительности при 8 процессорах, зависимость ТКС-35 (Scali/SCI) (F), объясняется тем, что задача при распараллеливании разбилась так, что уже хорошо локализуется в кэше, и скорость вычислений резко увеличилась, однако высокое качество сети позволило не потерять преимущества за счет роста скорости вычислений (рис. 2). Gigabit Ethernet этого не позволяет: для этой сети пропускная способность на уровне пользователя составляет около 50 Мбайт/c, а задержка передачи сообщения нулевой длины — около 46 мкс.
Различие реальной производительности для режимов H и F объясняется межпроцессорными помехами внутри платы вычислительного узла при доступе к общей памяти. Это досадное явление присуще Pentium 4 Xeon, который сегодня является стандартом де-факто для кластерных ВМВС в варианте двухпроцессорных серверных плат. Для AMD Opteron и Itanium 2 этого не наблюдается; вместе с тем, пока эти процессоры в существующих реализациях показывают обычно меньшую производительность, чем Pentium 4 Xeon, и их применение представляется преждевременным.
Практическое применение отечественных кластерных ВМВС связано с выполнением на них популярных наукоемких задач, например, инженерных расчетов. На рис. 5 приведен ряд таких пакетов с указанием их особенностей по распараллеливанию и интенсивности вычислений над выбираемыми из памяти данными. В НИЦЭВТ проведены работы по адаптации некоторых инженерных пакетов на отечественных кластерных ВМВС; в сотрудничестве с MSC Software адаптированы пакеты MSC Nastran и MSC Marc; адаптированы пакеты LS-DYNA и СFX-5; ведутся работы по пакетам Fluent и Ansys. Результаты этих работ уже используются в авиационной промышленности России. В ИПС РАН на кластерной установке СКИФ такого же типа адаптирован пакет Star-HPC.

Рис. 5. Пакеты инженерных расчетов и их особенности распараллеливания и локализуемости в кэш-памяти
Адаптация и освоение пакетов инженерных расчетов — составная часть большого комплекса работ по постановке наукоемких технологий на кластерных ВМВС. Данное направление задает одну из основных тем проектов по программе «Триада».
Новые вычислительные модели и архитектуры
Деятельность по созданию перспективных отечественных ВМВС с повышенной эффективностью на широком классе задач была начата в 2002 году в виде научно-исследовательской работы «Исследования по архитектурам и системным программным средствам для компьютеров и систем мультитредового типа» в рамках ФЦП «Национальная технологическая база». Предполагается подготовить технические предложения в виде вариантов принципов работы, описаний структуры и функционирования, принципов построения системного программного обеспечения для комплексов нового поколения в диапазоне от 100 GFLOPS до нескольких PFLOPS. Результатом выполнения программы должны стать исходные данные для разработки российских вариантов систем нового поколения, близких по техническим характеристикам к зарубежным системам в диапазоне от Cray MTA 2 (первый образец поставлен в начале 2002 года) до BlueGene (поставка первой системы BlueGene/L производительностью 200 TFLOPS намечена в США на 2004 год).
Исследования ведутся по следующим направлениям:
- выделение типовых проблем, возникающих при решении задач на современных вычислительных системах и обуславливающие их низкую реальную производительность, поиски путей их решения за счет использования мультитредовых (multithread) архитектур и соответствующих программ;
- разработка принципов организации мультитредовых процессоров с разной организацией (архитектура с управлением потоком данных - DF; мультитредовая архитектура - MT; параллельная мультитредовая архитектура - SMT, мультитредовая архитектура с управлением потоком данных - MT/DF или SMT/DF; чип-мультитредовая архитектура - CMP; архитектура процессоров внутри кристалла памяти - PIM);
- разработка принципов организации коммуникационных сред с высокой пропускной способностью и малой задержкой передачи сообщений для мультитредовых вычислительных систем;
- разработка принципов организации мультитредовых систем с распределенной разделяемой памятью и динамической балансировкой загрузки процессоров;
- разработка принципов организации компиляторов языков программирования для мультитредовых процессоров и систем, обеспечивающих статическое и динамическое автоматическое распараллеливание;
- разработка принципов организации исполняемых мультитредовых программ;
- разработка принципов построения систем предобработки больших объемов сигнальной информации в реальном времени.
Остановимся на системах типов DF и SMT.
DF-система разработана на базе ОСВМ [6], но является менее «радикальной» и приближенной к современным системам с мультитредовой архитектурой. В значительной степени на это решение повлияла архитектура системы TeraMTA, а также очень близкие по тематике исследования работы Стэнфордского университета и Массачусетского технологического института.
В основе DF-системы лежит классический мультитредовый RISC-микропроцессор (p фон-неймановской архитектуры, обычным образом работающий с оперативной памятью, но имеющий одну особенность, связанную с поддержкой вычислений, управляемых потоком данных. Особенность эта состоит в том, что в состав блоков (p введен особый блок приема/выдачи DF-сообщений, который может принимать исполняемые пары, а также выдавать формируемые в (p токены. Простые операции узлов потокового графа программы при помощи соответствующих исполняемых пар передаются этим блоком непосредственно в функциональные устройства (p. После их выполнения функциональные устройства порождают и передают обратно в блок приема/выдачи DF-сообщений заявки на порождение токенов с результатами этих операций.
Инициализация вычислений, соответствующих сложным узлам DF-графа, производится также блоком приема/выдачи DF-сообщений. После поступления в него исполняемой пары этот блок порождает тред микропроцессора, (p, который далее выполняется так, как если бы был явным образом порожден обычным средством типа fork. Эта возможность значительно повышает динамику порождения тредов. Существенно и то, что пользователь освобожден от порождения явным образом: они порождаются автоматически в соответствии с графом потока данных программы.
Если рассматривать работу (p на уровне микроархитектуры, то оказывается, что он фактически имеет два блока выборки команд для загрузки своих функциональных устройств. Один из них — обычный блок выборки команд запущенных тредов основного (фон-неймановского) набора команд, а другой — это блок приема/выдачи DF-сообщений. Он также передает исполняемые команды в функциональные устройства, но эти команды происходят из вычислений, управляемых потоком данных. В отличие от исполнительного устройства ОСВМ, микропроцессор (p выполняет сразу вычисления по множеству вычислительных узлов DF-графа программы, причем как простых, так и сложных. При этом одновременно еще выполняются обычные программы, работающие с оперативной памятью, но в режиме мультитредовости.
Еще одна особенность предложенной DF-системы — резко усиленная по сравнению с ОСВМ по своим функциональным возможностям часть, связанная с реализацией потокового управления — спаривания токенов, приходящих в вычислительные узлы DF-графа программы (DF-часть). В ОСВМ эти функции выполняли модули ассоциативной памяти. В предложенной DF-системе вместо модуля ассоциативной памяти введен мультитредовый микропроцессор доступа к данным (процессор dp). Этот процессор работает с банками ассоциативной и локальной оперативной памяти, однако при этом выполняет значительно больший репертуар операций. Собственно, эти узлы были фактически введены и в ОСВМ, однако в DF-системе они значительно разнообразнее.
Повышение сложности работы с узлами в DF-части привело к тому, что обработка поступающих в нее токенов стала достаточно сложным и многошаговым процессом, для которого характерна интенсивная работа как с ассоциативной, так и с локальной оперативной памятью. Проблема обеспечения интенсивной работы с памятью в dp решается стандартным для современных микроархитектур способом — введением мультитредовости. Каждый тред автоматически порождается по пришедшему в dp токену. Таким образом, dp может одновременно выполнять сложную обработку множества токенов.
Предложенная DF-система обладает свойствами современных мультитредовых систем, однако включает элементы потокового управления и использования ассоциативного доступа к данным. Теоретические оценки DF-системы, сделанные пока на простых примерах типа DAXPY с использованием реальных для реализации временных диаграмм работы устройств, показывают, что она может развивать сопоставимую с векторными машинами (Сray SV1, SV2 или Cray X1) скорость, причем даже над нерегулярно расположенными в памяти данными, что крайне важно для современных приложений.
Если проводить аналогию с современными системами, то предложенную DF-систему можно рассматривать как многопроцессорную мультитредовую, в которой применяется кэш-память с большим расслоением и возможностями сложной выборки данных. Такая сложная подсистема кэш-памяти — это и есть DF-часть.
Описанная DF-система послужила базой для разработки системы SMT-типа. Микропроцессор (p SMT-системы отличается лишь тем, что вместо блока приема/выдачи DF-сообщений в нем введен кэш команд и данных второго уровня, добавлен кэш данных первого уровня, а в блоке выборки команд введена возможность выборки команд на такте не из одного треда, а из нескольких. В (p SMT-системы также усилены возможности спекулятивного выполнения команд.
Значительное внимание уделено разработке базового пакета тестов для исследования эффективности предложенных архитектур с использованием разработанных на имеющихся кластерных ВМВС параллельных имитационных моделей этих систем. При их составлении изучены пакеты комплексного тестирования Tera MTA, AlphaServer SC и IBM SP3, Cray SV1. Также рассматривались и специальные тестовые пакеты, включая как ставшие уже классическими: ливерморские циклы, NASKER, NPB 2.3, Linpack, Euroben 3.9, так и появившиеся недавно пакеты C3I Parallel Benchmark Suite, DIS, DIS Stressmarks.
Исследования предложенных архитектур ведутся сейчас на параллельных имитационных моделях. Необходимость их усовершенствования может возникнуть при проработке вопросов: создания операционной системы, повышении возможностей эффективного межтредового взаимодействия (это необходимо, например, при решении задачи эмуляции на этих машинах архитектур других систем), аппаратной поддержке обнаружения информационной зависимости параллельно выполняемых участков программ при использовании современных методов динамического распараллеливания и др. Особое место занимают вопросы обеспечения отказоустойчивости, снижения потребляемой энергии.
***
В статье были рассмотрены основные тенденции развития отечественных ВМВС. Естественно, сюда не вошли все направления; значительный интерес представляют, например, работы по реконфигурируемым системам, ведущиеся под руководством академика А.В. Каляева. Работы в такой стратегически важной и системообразующей области, как высокопроизводительные вычисления, не могут эффективно вестись оторванными друг от друга организациями; нужна поддерживаемая государством инфраструктура крупного комплексного проекта. Это подтверждает как опыт зарубежных стран, так и отечественный опыт. Некоторым продвижением в этом направлении была программа СКИФ, а в более полной мере могут стать комплексная программа «Триада» и планируемая программа СКИФ-2.
- Cluster Computing White Paper. Version 2.0, December 28, 2000. M. Baker ed.
- S. Habata, M. Yokokawa, S. Kitawaki. The Earth Simulator System. NEC Research & Development, 2003, Vol. 44, No. 1.
- En Route to Petaflop Computing Speed: Introducing the Cray X1 Supercomputer. Cray Inc., 2002.
- R. Partridge. Cray Launches X1 for Extreme Supercomputing. D.H. Brown Associates.
- Л.К. Эйсымонт. Оценочное тестирование высокопроизводительных систем: цели, методы, результаты и выводы. Сб. лекций Второй Всероссийской молодежной школы "Суперкомпьютерные вычислительно-информационные технологии в физических и химических исследованиях", // Черноголовка, 2000.
- В.С. Бурцев. Выбор новой системы организации выполнения высокопараллельных вычислительных процессов, примеры возможных архитектурных решений построения суперЭВМ. В сб. трудов академика В.С. Бурцева "Параллелизм вычислительных процессов и развитие архитектуры суперЭВМ". // ИВВС РАН, М., 1997.
Валерий Митрофанов — генеральный директор НИЦЭВТ, Анатолий Cлуцкин (slutskin@nicevt.ru) — заместитель генерального директора по научной работе НИЦЭВТ, Константин Ларионов (larka@nicevt.ru) — начальник отдела «Высокопроизводительные вычислительные системы», главный конструктор кластерных ВМВС серии ЕС 1720, Леонид Эйсымонт (verger-lk@yandex.ru) — начальник сектора отдела «Высокопроизводительные вычислительные системы» НИЦЭВТ (Москва).
