Хранение данных во внешней памяти в известных СУБД (Oracle, IBM DB2, Microsoft SQL Server, CA-OpenIngres, решения от Sybase и Informix и др.) организовано очень похожим образом.
Организация хранения
Основными единицами физического хранения являются блок данных, экстент, файл (либо раздел жесткого диска). Логический уровень представления информации включает пространства (либо табличные пространства). Блок данных (block) или страница (page) является единицей обмена с внешней памятью. Размер страницы фиксирован для базы данных (Oracle) или для ее различных структур (DB2, Informix, Sybase) и устанавливается при создании. Очень важно сразу правильно выбрать размер блока: в работающей базе изменить его практически невозможно (для этого часто проводят ряд испытаний базы данных-прототипа).
Размер блока оказывает большое влияние на производительность базы данных — при больших размерах скорость операций чтения/записи растет (особенно это характерно для полных просмотров таблиц и операций интенсивной загрузки данных), однако возрастают накладные расходы на хранение (база увеличивается) и снижается эффективность индексных просмотров. Меньший размер блока позволяет более экономно расходовать память, но вместе с тем относительно дорог. Длинные блоки (16, 32 или 64 Кбайт) лучше использовать для больших объектов данных: полнотекстовые фрагменты, мультимедиа-объекты, длинные строки и т.п. Короткие блоки (2 или 4 Кбайт) лучше подходят для значений числовых типов, недлинных строк, значений даты и времени. Следует также учитывать размер блока ОС, он должен быть кратен размеру блока базы данных. Малый размер блока лучше подходит для систем оперативной обработки транзакций, потому что, если сервер блокирует данные на уровне блоков, то это позволяет большему числу пользователей работать, не мешая друг другу (рис. 1). В системах поддержки принятия решений, для которых более критичным является не общая пропускная способность (количество транзакций в единицу времени), а среднее время отклика (response time), больший блок предпочтительнее.
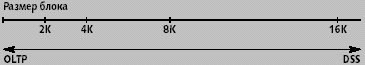 |
| Рис. 1. Зависимость размера блока данных от типа приложения |
Администратор отводит пространство для базы данных на внешних устройствах большими фрагментами: файлами и разделами диска. В первом случае доступ к диску осуществляется операционной системой, что дает определенные преимущества, например, работа с файлами средствами ОС. Во втором случае с внешним устройством работает сам сервер. При этом достигается более высокая производительность; кроме того, использование дисков необходимо в случае, если кэш ОС не может работать в режиме сквозной (write-through) записи. Диски особенно эффективны для ускорения операций записи данных (подобный механизм поддерживается Oracle, DB2 и Informix; например, в DB2 данная единица размещения называется контейнером).
Пространством внешней памяти, отведенным ему администратором, сервер управляет с помощью экстентов (extent), т.е. непрерывных последовательностей блоков. Информация о наличии экстентов для объекта схемы данных находится в специальных управляющих структурах, реализация которых зависит от СУБД. На управление экстентами (выделение пространства, освобождение, слияние) тратятся определенные ресурсы, поэтому для достижения эффективности нужно правильно определять их параметры. СУБД от Oracle, IBM, Informix позволяют определять параметры этих структур, а в Sybase экстенты имеет постоянный размер, равный 8 страницам. Уменьшение размера экстента будет способствовать более эффективному использованию памяти, однако при этом возрастают накладные расходы на управление большим количеством экстентов, что может замедлить операции вставки большого количества строк в таблицу. Кроме того, сервер может иметь ограничение на максимальное количество экстентов для таблицы. При слишком большом размере экстентов могут возникнуть проблемы с выделением для них необходимого количества памяти. Обычно определяется размер начального экстента, размер второго и правило определения размеров следующих экстентов. На рис. 2 иллюстрируется взаимосвязь блоков, экстентов и файлов баз данных.
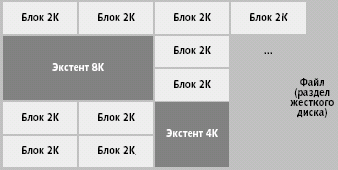 |
| Рис. 2. Блоки, экстенты и файлы базы данных |
В Informix существует еще одна единица физического хранения, промежуточная между файлом (или разделом диска) и экстентом, — это «чанк» (от английского chunk, что дословно переводится как «емкость»). Чанк позволяет более гибко управлять очень большими массивами внешней памяти. В одном разделе диска или файле администратор может создать несколько чанков. Чанк также служит единицей зеркалирования.
Общим для СУБД Oracle, DB2 и Informix является понятие пространства (для Oracle и DB2 это табличное пространство). Различные логические структуры данных, такие как таблицы и индексы, временные таблицы и словарь данных размещены в табличных пространствах. В DB2 и Informix дополнительно можно устанавливать размер страницы отдельно для каждой из этих структур. Группировка хранимых данных по пространствам производится по ряду признаков: частота изменения данных, характер работы с данными (преимущественно чтение или запись и т.п.), скорость роста объема данных, важность и т.п. Таким образом, например, только читаемые таблицы помещаются в одно пространство, для которого установлены одни параметры хранения, таблицы транзакций размещаются в пространстве с другими параметрами и т.д. (рис. 3).
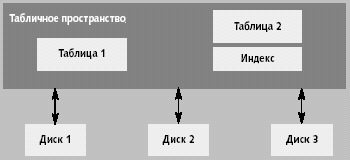 |
| Рис. 3. Физическое размещение данных по устройствам |
Одна логическая единица данных (таблица или индекс) размещается точно в одном пространстве, которое может быть отображено на несколько физических устройств или файлов. При этом физически разнесены (располагаться на разных дисках) могут не только логические единицы данных (таблицы отдельно от индексов), но и данные одной логической структуры (таблица на нескольких дисках). Такой способ хранения называется горизонтальной фрагментацией: таблица делится на фрагменты по строкам. В Oracle вместо термина «фрагментация» используется «секционирование» (partitioning). Фрагментация — один из способов повышения производительности.
Могут применяться различные схемы записи данных во фрагментированные таблицы. Одна из них — круговая (round-robin), когда некоторая часть вставляемых в таблицу строк записывается в первый фрагмент, другая часть — в следующий и так далее по кругу. В данном случае за счет распараллеливания может быть увеличена производительность операций модификации данных и запросов. Существует и другая схема, включающая логическое разделение строк таблицы по ключу («кластеризация»). Данная схема позволяет избежать перерасхода процессорного времени и уменьшить общий объем операций ввода/вывода. Ее суть в том, что при создании таблицы все пространство значений ключа таблицы разбивается на несколько интервалов, а строкам с ключами, принадлежащими разным интервалам, назначаются различные месторасположения. Впоследствии, при обработке запроса, данная информация учитывается оптимизатором. Если производится поиск по ключу, то оптимизатор может удалять из рассмотрения фрагменты таблицы, не удовлетворяющие условию выборки. Например, создание кластеризованной таблицы будет выглядеть следующим образом (этот и все остальные SQL-скрипты приведены для Oracle):
CREATE TABLE person ( num INTEGER, fio VARCHAR2 (30) ) PARTITION BY RANGE (num) ( PARTITION part1 VALUES LESS THAN ( 500 ) TABLESPACE tblspace1, PARTITION part2 VALUES LESS THAN ( 1000 ) TABLESPACE tblspace2 )
Здесь создаются два раздела part1 и part2, каждый из которых размещен в своем табличном пространстве (tblspace1 и tblspace2). Записи со значением поля num от 1 до 499 будут располагаться в первом разделе, а записи с номерами от 500 до 1000 — во втором (рис. 4).
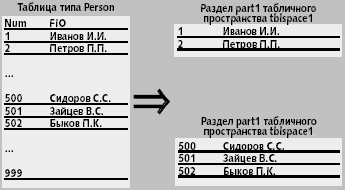 |
| Рис. 4. Пример кластеризации записей |
Тогда при запросе:
SELECT fio FROM person WHERE num BETWEEN 10 AND 40
оптимизатор будет производить поиск только в разделе part1, что может дать ощутимый выигрыш в производительности в таблице с десятками тысяч строк.
Подобные механизмы фрагментации данных поддерживают практически все современные СУБД, что часто используется при создании систем высокой производительности.
Методы доступа
Современные СУБД предоставляют достаточно широкий набор различных методов доступа, которые чаще всего являются теми или иными видами индексирования — способа отображения ключа индексирования в адрес хранимой записи. Используются следующие типы индексных структур: на основе B-дерева (B-tree); на основе хэш-функции или хеширование (hashing); на базе битовых шкал или индексов (bitmap). Индекс может служить различным целям: для ускорения доступа к записям одной таблицы и для ускорения операций соединения, тогда он называется индексом соединения. Если в качестве ключа индексирования используется некоторая функция атрибутов таблицы, такой индекс называют «основанным на функции» (function-based). Скажем, можно создать такой индекс для ускорения поиска с учетом регистра символов для таблицы Famous (таблица 1):
CREATE INDEX uc_fullname ON famous (UPPER(fullname)); Таблица 1. Famous FULLNAME SEX MARRIED BIRTH Mercury F. М NO 5-09-1949 Тэтчер М. Ж YES Ленин В.И. М YES 22-04-1870 ... ... ... ...
Отличают также «кластеризованный» (clustered) индекс. При его использовании все записи таблицы упорядочиваются по его ключу; поэтому кластеризованный индекс более экономно расходует память и обычно быстрее опрашивается. Для таблицы, таким образом, можно создать лишь один такой индекс.
B-деревья универсальны и обеспечивают хорошую скорость доступа как при просмотрах по диапазонам, так и при выборке единичной записи по значению ключа, однако характеризуются относительно большим объемом памяти для хранения и затратами на поддержание в актуальном состоянии, включающими обычно балансировку дерева. Такой индекс имеет один существенный недостаток — он может быть использован только в запросах по ведущим столбцам. Например, если в таблице Famous создан составной индекс по столбцам fullname, birth и sex:
CREATE INDEX emp_ind_01 ON famous (fullname, birth, sex)
то запросы
SELECT * FROM famous WHERE fullname > "Иван" SELECT * FROM famous WHERE fullname = "Васисуалий Лоханкин" AND birth BETWEEN '10.09.1880' AND '10.10.1880' SELECT * FROM famous WHERE fullname = "Скалидзе" AND birth BETWEEN '10.09.1880' AND '10.10.1880' and sex='M'
смогут использовать этот индекс, а в следующих запросах:
SELECT * FROM famous WHERE birth BETWEEN '10.09.2000' AND '10.10.2000' SELECT * FROM famous WHERE fullname="Скалидзе" AND sex="M"
оптимизатор не сможет им воспользоваться, что связано с архитектурными особенностями данного типа индексирования. В данном примере индекс может быть использован при запросах по fullname, birth, sex либо fullname, birth либо только fullname. Несмотря на этот недостаток, индексы B-деревьев наиболее распространены и используются во всех рассматриваемых СУБД. Для B-дерева можно задать «степень использования страницы индекса» (fillfactor); так, в Oracle используются параметры PCTUSED и PCTFREE для блоков базы данных в том числе и индексных. При создании индекса его страницы заполняются только на указанный процент (рис. 5). При увеличении процента использования страницы увеличится скорость операций изменения индекса, однако возрастут также расходы на хранение и может увеличиться время выполнения запросов.
 |
| Рис. 5. Внутренняя организация блоков индекса |
Каждая СУБД может иметь ряд дополнительных параметров, предоставляющих разработчику расширенные возможности конфигурирования В-деревьев.
Хэш-индекс имеет небольшие накладные расходы на хранение, однако требует, чтобы распределение значений ключа индексирования было относительно постоянно, в противном случае потребуется частая переделка индекса на основе новой хэш-функции. Индексы на основе хэш-функций хорошо подходят для различного рода справочных таблиц. При этом не требуется, чтобы индексируемый столбец имел много повторяющихся значений, как того требуют битовые индексы.
Битовые индексы также очень компактны и полезны для столбцов с большим процентом повторения значений ключа. Обычно используют следующее правило: если количество повторяющихся значений столбца более 99% от общего количества строк таблицы, тогда целесообразно рассмотреть использование битового индекса. Так, таблица Famous могла бы выиграть от использования двух битовых индексов — по столбцам SEX и MARRIED.
CREATE BITMAP INDEX emp_ind_02 ON famous (sex) CREATE BITMAP INDEX emp_ind_03 ON famous (married)
Битовые индексы обладают очень важным свойством: если производится запрос, включающий сложное условие выборки, которое составлено из предикатов OR, AND, NOT и «=», то оптимизатор может использовать имеющиеся по конкретным столбцам битовые индексы, объединяя их. B-деревья этого делать не позволяют (для этого потребовалось бы построить составной индекс по этим столбцам, специально для ускорения данного запроса). В рассматриваемом примере запрос вида:
SELECT * FROM famous WHERE sex=«М» AND married=«YES»
может использовать оба битовых индекса emp_ind_02 и emp_ind_03. Однако тот же запрос не сможет использовать два отдельных индекса по этим же столбцам. Битовые карты полезны в хранилищах, где преобладают длинные транзакции и данные читаются чаще чем записываются, однако они неэффективны в приложениях с короткими транзакциями, характерными для OLTP-систем.
В DB2 используется оптимизированный вариант B-дерева с двунаправленными указателями и «упреждающей регистрацией обновлений» (write-ahead logging), что позволяет ускорить вставку данных. При создании индекса можно также использовать некоторые опции, например, указать серверу о необходимости хранить в структуре индекса дополнительные часто запрашиваемые значения атрибутов.
В СУБД Oracle помимо многочисленных индексов используются «индексно-упорядоченные» (index-organized) таблицы и кластеры. В первом случае вся таблица индексирована по первичному ключу и организована в виде B-дерева.
CREATE TABLE person (num INTEGER, fio VARCHAR2(30) CONSTRAINT pk_person PRIMARY KEY (num)) ORGANIZATION INDEX;
Подобный метод организации хранения хорошо подходит для часто опрашиваемых больших (более 5 тыс. строк) и очень больших таблиц с небольшим объемом операций, для которых критично время выполнения запроса на точное совпадение по первичному ключу, например:
SELECT * FROM person WHERE num=12 OR num=1000
Экономия времени при выполнении таких запросов может составлять от 15 до 400% в зависимости от длины строки [1].
Кластер Oracle — это структура для хранения одной или нескольких таблиц, главным образом служащая для ускорения операций их соединения, в которой строки таблиц, удовлетворяющие условию соединения, хранятся вместе. Столбцы, используемые для соединения, называются кластерным ключом. Значения кластерного ключа сохраняются один раз (дубликаты исключаются). Для доступа по кластерному ключу могут использоваться как B-деревья, так и хэш-структуры, в этом случае кластер является хэш-кластером. Стоит также упомянуть битовый индекс соединения (bitmap join), ускоряющий операции объединения таблиц. В Sybase используются B-деревья, а индекс может быть как кластеризованным так и обычным. В Informix можно применять кластеризованные, битовые и индексы, основанные на функции.
Проблемы управления внешней памятью
Распространенной проблемой для администраторов при управлении физическим хранением является фрагментация различных структур внешней памяти, которая чаще обусловлена операциями удаления. В отличие от преднамеренной фрагментации, такая «фрагментация» обычно ухудшает производительность. Встречается фрагментация на уровне блоков, когда в блоке остается свободное пространство после удаления строк из таблицы, на уровне экстентов, когда заполненные экстенты чередуются с незаполненными, появившимися после операций удаления таблиц, и т.п. Укажем лишь часть из проблем, которые могут быть обусловлены фрагментацией.
- Выделение свободного пространства. При вставке строк в таблицу СУБД выдает сообщение о нехватке свободного пространства, хотя на первый взгляд пространства достаточно. Пространство выделяется экстентами и, если в базе данных нет непрерывного свободного блока нужного размера, то выдается это сообщение.
- Замедление операций вставки в таблицу. В [2] приводится пример с таблицей базы данных, в которую в ходе выполнения ночного пакетного задания происходит вставка большого количества строк. Для того чтобы уменьшить время его выполнения был в несколько раз увеличен размер вновь выделяемых экстентов, благодаря чему снизились накладные расходы на выделение экстентов, а скорость выполнения пакетного задания возросла на 30%.
- Расход свободного пространства и общее увеличение времени обработки данных. В случае сильной фрагментации обе величины могут вырасти вдвое.
Фрагментация неизбежна и поэтому является нормальным явлением, и не всегда ухудшает характеристики базы данных. Индексы также подвержены проблемам фрагментации пространства, и могут стать несбалансированными, поэтому SQL-оператор ALTER INDEX обычно имеет опцию REBUILD, позволяющую перестроить индекс. Индекс также можно удалить и создать заново даже в работающей базе данных.
Заключение
Эффективность использования любых методов доступа зависит от распределения данных в запрашиваемых таблицах, от стратегии работы оптимизатора СУБД и от возможностей диалекта SQL. Поэтому приведенные рекомендации носят достаточно общий характер — все определяется конкретной ситуацией. Решения, принимаемые на этапах физического проектирования и настройки, чаще всего представляют собой компромисс между достижением требуемых характеристик, которые часто противоречат друг другу. За выигрыш в скорости обработки запросов, которую дает индекс, приходится платить дополнительными ресурсами памяти на его размещение и процессорным временем для его поддержки в актуальном состоянии. К сожалению, трудно привести конкретные оценки: многое зависит от конфигурации сервера, настройки ОС и СУБД и т.п.
Рассмотренный перечень методов доступа не является полным. Описаны лишь распространенные технологии, которые можно назвать традиционными. Например, за кадром остались возможности современных СУБД, связанные с реализацией расширяемой системы типов данных. Сюда относят технологии расширителей (Extender) IBM, DataBlade (Informix) и картриджей (Oracle). Тем не менее, перечисленный арсенал средств достаточно богат сам по себе. Адекватное представление об этих средствах позволяет сделать проектируемые базы данных и их приложения менее зависимыми от конкретной СУБД.
Литература
- A. Peled, Index-organized tables - When should they be used? (www.orapub.com)
- К. Шаллахэмер, Все о фрагментации Oracle. (www.orapub.com)
Дмитрий Горохов (dgorohov@vladen.elcom.ru) — программист «Владимирэнерго»; Владимир Чернов — доцент Владимирского государственного университета.
