данного процессора, которую разработчики охарактеризовали как «пост-RISC». Появившиеся весной данные о разработке группой российских компаний «Эльбрус» МП E2K [1,2] представляют большой интерес, поскольку в них реализованы все основные особенности, позволившие Intel и HP заявлять о наступлении эры новых микропроцессорных архитектур. Анализу характеристик E2K и посвящена настоящая публикация.
К моменту объявления о разработке Мerced в развитии линии RISC-процессоров, по мнению части специалистов, стали проявляться некоторые «предкризисные явления». Среди все усложняющихся проблем можно отметить сложность логики, обеспечивающей загрузку функциональных исполнительных устройств (ФУ); проблемы пропускной способности и задержек при обращении к разным уровням иерархии памяти - от кэша до оперативной памяти (ОП); проблемы предсказания переходов и др. Нерешенность этих проблем грозит простоями ФУ современных суперскалярных микропроцессоров, т.е. понижением КПД их работы.
Предложенные в IA-64 архитектурные идеи близки к известной концепции VLIW (Very Large Instruction World - сверхбольшое командное слово). С точки зрения автора, из данных, представленных разработчиками IA-64, можно выделить два наиболее принципиальных нововведения по сравнению с процессорами RISC-архитектуры: применение технологии явного параллелизма на уровне команд (EPIC - Explicitly Parallel Instruction Computing) и применение предикатных вычислений [3]. В сочетании с новым уровнем спекулятивных вычислений это значительно уменьшает количество условных переходов и, соответственно, ошибочных предсказаний направления переходов. В свою очередь, применение EPIC как некоего, грубо говоря, модернизированного варианта VLIW, однозначно диктует появление в архитектуре большого числа ФУ и сверхбольших файлов регистров.
Между тем близкий к этому подход уже был реализован в России - в произведенном в единственном экземпляре суперкомпьютере Эльбрус-3 [1, 4], выпущенном в 1991 году. В целом, по мнению автора [1], архитектуры IA-64 и E2K весьма сходны. Это позволяет думать об определенном российском приоритете в этой области.
Прежде чем перейти собственно к обсуждению процессора E2K, следует сказать несколько слов по поводу VLIW. Хотя идеи VLIW сформулированы уже давно, до настоящего времени они были известны в основном специалистам в области компьютерных архитектур. Имеющиеся реализации, например, VLIW Multiflow, не получили широкого распространения. Пожалуй, единственными популярными процессорами, архитектура которых близка к VLIW, была линия AP-120B/FPS-164/FPS-264 компании Floating Point Systems, которые в 80-е годы активно применялись при проведении научно-технических расчетов.
Команда в этих системах содержала ряд полей, каждое из которых управляло работой отдельного блока процессора, так что все командное слово определяло поведение всех блоков процессора [5]. Однако длина команды в FPS-х64 была равна всего 64 разрядам, что по современным меркам никак нельзя отнести к сверхбольшим.
Выделение в архитектуре VLIW компонентов командного слова, управляющих отдельными блоками МП, вводит явный параллелизм на уровень команд. Задача обеспечения эффективного распараллеливания работы отдельных блоков возлагается при этом на компилятор, который должен сгенерировать машинные команды, содержащие явные указания на одновременное исполнение операций в разных блоках. Таким образом, достижение параллелизма, обеспечиваемое в современных суперскалярных RISC-процессоров их аппаратурой, в VLIW возлагается на компилятор. Очевидно, что это вызывает сложные проблемы разработки соответствующих компиляторов. При этом распараллеливание работы между ФУ в EPIC происходит статически при компиляции, в то время как современные суперскалярные RISC-процессоры осуществляют это динамически.
Архитектура E2K
Структура команд и регистры E2K
Обсуждение архитектуры E2K естественно начать с формата команды. В классическом варианте VLIW длина команды фиксирована. Это приводит к значительному дополнительному расходу памяти под коды программы и, как следствие, к неэффективному использованию программного кэша. Кроме того, это является ограничением на «масштабируемость» микропроцессора. Здесь под масштабируемостью мы имеем в виду возможность наращивать число ФУ (в новых поколениях микропроцессоров), не требующую изменения программных кодов.
В IA-64 по 3 команды объединяются в так называемые связки (bundle) длиной 128 разрядов. В формат команд вводятся специальные разряды маски (template bits), которые указывают на зависимости между командами [6]. Разряды маски указывают как на зависимости внутри одной связки, так и на зависимости между связками команд. Наличие такой зависимости подавляет возможность параллельного выполнения соответствующих операций. Как известно, в RISC-процессоре подобные взаимозависимости определяются аппаратно.
 |
| Рис.1. Структура команды E2k |
В E2K используется иной подход, базирующийся на применении команд переменной длины. Общий формат команд E2K представлен на рис. 1. Команда E2K состоит из слогов длиной 32 разряда каждый. Число этих слогов может меняться от 2 до 16, причем данную архитектуру можно еще расширить - до 32 слогов.
Любая команда всегда включает 1 слог заголовка и еще от 1 до 15 слогов, указывающих на операции, которые могут выполняться параллельно. Слог заголовка содержит информацию о структуре команды и ее длине, что облегчает дешифрацию команды переменной длины.
Таблица 1. Типы команды слогов E2K
| Содержание слога | Число слогов |
| Заголовок | 1 |
| Операции АЛУ | 6 |
| Управление подготовкой перехода | 3 |
| Дополнительные операции АЛУ при зацеплении | 2 |
| Загрузка из буфера предварительной выборки массивов в регистр | 4 |
| Литеральные константы для ФУ | 4 |
| Логические операции с предикатами | 3 |
| Предикаты и Маски для управления ФУ | 3 |
Если не считать заголовок, в архитектуре E2K имеется 7 типов слогов (табл. 1). В команде может быть представлено сразу несколько слогов одного типа, максимальное число которых указано в последнем столбце данной таблицы. Количество и типы слогов в команде E2K задаются в ее заголовке.
Применение заголовка позволяет не проводить предварительного декодирования команд перед их помещением в кэш команд. Отрицательной стороной введения поля заголовка является некоторое увеличение длины команды.
Слоги должны располагаться слева направо в определенном порядке, - в том, в котором они указаны в табл. 1 сверху вниз. Если какой-то тип слогов в команде отсутствует, последующие слоги в команде как бы занимают их место.
Естественно, в архитектуре E2K представлен сверхбольшой файл регистров. Все регистры E2K являются универсальными и могут содержать как целочисленные данные, так и числа с плавающей запятой. Всего имеется 256 регистров длиной по 64 разряда каждый. Это резко выделяет E2K среди практически всех современных микропроцессоров, в которых регистры общего назначения отделены от регистров с плавающей запятой. Для сравнения, в IA-64 имеется 128 целочисленных регистров и 128 регистров с плавающей запятой [6]. Динамическое выделение из общего пула регистров в соответствии с тем, какого типа данные требуются, позволяет более оптимально использовать емкость файла регистров.
Интересно сравнить характеристики E2K не только с Merced, подробные данные по которому отсутствуют, но и с ведущими по производительности RISC-процессорами Alpha 21264 [7]. Так, число целочисленных регистров в этом процессоре равно 80 (этот файл регистров продублирован, см. ниже), а число регистров с плавающей запятой - 72.
Здесь необходимо обратиться к одной общей особенности Alpha 21264 и E2K — наличию в их микроархитектуре понятия кластера. Оба процессора содержат по 2 кластера. Причиной введения кластеров является ориентация на высокие тактовые частоты -
1 ГГц и выше. В этом случае время распространения сигнала становится определяющей величиной, и возникает потребность размещать часто обменивающиеся информацией блоки процессора рядом друг с другом. Реализовать это на достижимом уровне плотности упаковки не удается, поэтому разработчики обоих процессоров выделили по две области (кластера), внутри которых логические блоки процессоров расположены достаточно близко друг к другу.
Кластеры обоих микропроцессоров содержат, в частности, по 1 копии файла регистров (в Alpha 21264 - только целочисленных) и ФУ, причем в отношении последних кластеры в Alpha 21264 не являются симметричными, а в E2K - почти симметричны. В E2K каждый кластер содержит по 256 регистров (рис. 2). Всего в этом процессоре имеется 30 регистровых портов: 20 портов чтения (по 10 портов на кластер) и 10 портов записи. Для сравнения, в Alpha 21264 у целочисленных регистров имеется 8 портов чтения (по 4 на кластер) и 6 портов записи.
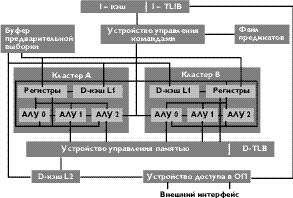 |
| Рис.2. Упрощенная схема E2K |
В Alpha 21264 применяется реализованное во многих суперскалярных процессорах динамическое переименование регистров. Этого механизма в E2K нет, так как в нем подобные задачи возлагаются на компилятор, однако в циклах с постоянным шагом применяется аналогичная схема циклической замены используемых регистров. А именно, набор используемых в цикле регистров можно представить в виде некоторого окна, накладываемого на регистровый файл. На начало этого окна указывает специальный регистр базы.
Когда происходит переход на следующую итерацию цикла, регистр базы увеличивается на размер окна, что эквивалентно продвижению окна вперед по файлу регистров на столько регистров, сколько их имеется в окне. Такой механизм позволяет, очевидно, производить одновременное выполнение команд из разных итераций цикла.
Любопытно, что Дифендорфф, автор первой подробной статьи об E2K, опубликованной в бюллетене Microprocessor Report [1], предположил, что в Merced будет использоваться раскрутка (unrolling) циклов с программным переименованием регистров, что должно увеличивать размер кодов программы. Однако в феврале 1999 года разработчики из Intel и HP сообщили, что в Merced будет применяться механизм, аналогичный описанному выше, который был ими назван «вращением регистров» [6].
С целью сохранения когерентности запись производится, естественно, в регистры обоих кластеров. В обоих микропроцессорах за введение кластеров приходится расплачиваться одним дополнительным тактом на передачу данных между кластерами. К рассмотрению кластеров мы еще вернемся ниже, а сейчас упомянем об еще одной интересной особенности E2K - регистровом окне для процедуры. Это решение является традиционным для машин серии «Эльбрус», однако особенно важным оно является для E2K, поскольку он содержит сверхбольшое количество регистров - 256.
Затраты на сохранение/восстановление регистров в данной ситуации становятся весьма значительными. Поэтому реализация в E2K аппаратного механизма переключения окон представляется актуальной. В отличие от архитектуры SPARC [8], в которой также используется этот подход, окно регистров в E2K имеет переменную длину (до 192 регистров). Адресация регистров внутри контекста происходит относительно текущей базы, и при вызове другой процедуры достаточно сменить значение базы.
Этот механизм - фактически такой же, как и рассмотренный выше механизм работы с итерациями цикла. Файл регистров рассматривается при этом как циклический буфер с окном переменного размера. При исчерпании файла регистров аппаратура E2K помещает часть регистров в стек оперативной памяти, освобождая место для нового окна. При возврате из процедуры в этом случае будет аппаратно проделана обратная операция. Минусом такого подхода являются накладные расходы - необходимость суммирования относительного регистрового адреса с базой, что потребовало в E2K введения дополнительной стадии в конвейер [1].
Кэш-память
Разработчики E2K приняли в недавние времена довольно малораспространенную схему с размещением на основной микросхеме двух уровней кэш-памяти. Сегодня такая схема уже не редкость: можно упомянуть Intel Сeleron, AMD K6-3 и DEC Alpha 21164. Лишь последний является высокопроизводительным 64-разрядным процессором. Поэтому двухуровневое строение кэша микропроцессора E2K, предполагающее применение еще и внешней кэш-памяти третьего уровня, естественно сопоставлять лишь с
Alpha 21164 [9]. C другой стороны, ввиду отсутствия достаточных данных о Merced полезно сопоставить E2K c Alpha 21264 (табл. 2).
Таблица 2. Сравнительные характеристики E2K и Alpha 21264
| E2K | Alpha 21264 | ||
| I-кэш L1 | Емкость, Кбайт | 64 | 64К |
| Тип | 4-канальный частично ассоц. | 2-канальный частично ассоц. | |
| Время доступа | 2 такта | 3 такта | |
| D-кэш L1 | Емкость, Кбайт | 8 + 8 | 64 |
| Тип | прямоадресуемый | 2-канальный частично ассоц. | |
| Время доступа | 2 такта | 3 такта | |
| D-кэш L2 | Емкость | 256 Кбайт | Кэш второго уровня является внешним |
| Тип | 2-канальный частично ассоц. | ||
| Время доступа | 8 тактов | ||
| I-TLB | Емкость | 64 строки | 128 строк |
| D-TLB | Емкость | 16 строк (ассоц.)+256 строк 4-канальн. частично ассоц. | 128 строк (ассоц.) |
| Регистры | Число | по 256 на кластер | 80x2 целоч., 72 веществ. |
| Число портов | 20 чтения, 10 записи | 8 чтения, 6 записи (целоч.) | |
| Тактовая частота, МГц | 1200 | 500-667 (*) | |
| Число транзисторов | 28 млн. | 15,2 млн. | |
| Площадь, кв. мм | 126 | 302 | |
| Рассеяние тепла, Вт | 35 | 60 | |
| Технология, мкм | 0,18 | 0,35(*) | |
| SPECint95 | 135 | 30 | |
| SPECfp95 | 350 | 60 | |
(*) При 0,18 мкм -технологии (EV68) частота - до 1 ГГц.
Кэш данных первого уровня в E2K имеет емкость всего 8 Кбайт (как у Alpha 21164) и продублирован в каждом из кластеров (рис. 2). Этот кэш, как и в Alpha 21164, является прямоадресуемым. Обе «половинки» кэша данных первого уровня в обоих кластерах содержат одинаковые данные и имеют по 2 порта. Данный кэш использует алгоритм сквозной записи данных, что, вероятно, вызвано наличием внутри кристалла кэша второго уровня, и является не блокирующим. Время доступа в кэш первого уровня равно «стандартным» для большинства процессоров
2 тактам, в отличие от Alpha 21264, где оно равно 3 тактам для загрузки целочисленного регистра и 4 тактам - для загрузки числа с плавающей запятой. Пропускная способность кэша первого уровня (при попадании) превышает 38 Гбайт/с, что можно сопоставить с пропускной способностью файла регистров - 288 Гбайт/с (данные для частоты 1,2 ГГц).
Интересно, что, как утверждают разработчики, непопадание в кэш данных первого уровня в E2K никогда не останавливает работу микропроцессора. Этот кэш имеет буфер адресов отсутствующих строк кэша. Обычно кэш данных второго уровня успевает заполнить кэш первого уровня до того, как этот буфер переполнится. Если же это все-таки произойдет, новые запросы к памяти будут направлены прямо в кэш второго уровня.
Кэш данных второго уровня в E2K имеет емкость 256 Кбайт при времени доступа в 8 тактов. Он является двухканальным частично-ассоциативным и имеет 4 банка, то есть обеспечивает
4-кратное расслоение кэш-памяти. В отличие от кэша первого уровня, в кэше данных второго уровня применяется алгоритм обратной записи. Кэш второго уровня также является неблокирующим.
Если входные буферы кэша второго уровня будут переполнены, то E2K остановится. При непопадании в кэш второго уровня будет происходить обращение к внешнему интерфейсу оперативной памяти, причем «системная шина» может управлять до 64 запросами для различных строк кэша второго уровня, что является очень высоким показателем.
По сравнению с Alpha 21164, при близких характеристиках кэша данных первого уровня, кэш данных второго уровня в E2K имеет гораздо большую емкость (в Alpha 21164 она равна
96 Кбайт, и этот кэш содержит команды и данные), а время доступа во вторичный кэш E2K (в тактах) меньше. Тем не менее автору остается неясным, почему разработчики E2K выбрали подобную «опасную» схему построения кэша данных. Известно, что Alpha 21164 из-за большого числа непопаданий в кэш данных первого уровня на широком классе приложений весьма часто «простаивает». Возможным ответом здесь является архитектурная поддержка в E2K команд спекулятивной загрузки, допускающая вынос вперед таких операций через границу базовых блоков с целью их предварительного выполнения. Спекулятивная загрузка представлена и в архитектуре IA-64 [6].
Разработчики Alpha 21264 отказались от двухуровневой схемы кэша в процессоре в пользу традиционной одноуровневой схемы. Емкость кэша первого уровня в этом процессоре меньше, чем кэша данных второго уровня в E2K. Хотя в Alpha 21264 кэш данных имеет трехтактный доступ, он может выдавать 2 результата за такт.
Разработчики E2K утверждают, что выбранная схема построения кэша не создает узких мест. Очевидно, что «полная» неблокируемость кэша данных первого уровня говорит в пользу выбранной схемы. Критерий истины, как известно, практика. Высокие оценочные характеристики, полученные разработками для тестов SPECint95/fp95 (табл. 2), являются определенным свидетельством эффективности принятого решения по строению кэша E2K.
Как и сама кэш-память, буфер быстрой переадресации (TLB) в E2K имеет двухуровневую иерархию: 16 строк полностью ассоциативной памяти плюс 512 строк TLB второго уровня (последний является 4-канальным частично-ассоциативным со временем доступа 2 такта). При этом поддерживается до 4 одновременных преобразований адресов при обращении в кэш второго уровня или к оперативной памяти.
При непопадании в TLB первого уровня процессор останавливается на 4 такта. В случае непопадания в TLB второго уровня время ожидания процессора составит от 10 до примерно 200 тактов в зависимости от числа требуемых просмотров в таблице страниц и ситуации с попаданием/непопаданием в кэши второго и третьего уровня. Емкость TLB второго уровня выглядит достаточно большой (так, в Alpha 21264 TLB имеет лишь 128 строк), поэтому более реальная опасность - непопадание в TLB первого уровня. Отметим, что при работе с кэшем первого уровня TLB вообще не нужен, так как этот кэш индексируется и тегируется виртуально (в отличие от кэша второго уровня).
Учитывая большую ширину команды, не удивительно, что разработчики E2K особо позаботились о пропускной способности кэша команд первого уровня, имеющего емкость 64 Кбайт при длине строки 256 байт. Этот кэш является 4-канальным частично ассоциативным. Ширина тракта, по которому команды из кэша команд поступают в устройство управления командами, составляет аж
256 байт. Однако максимальная скорость заполнения кэша команд cоставляет 32 байта за такт, что может создать узкое место в микроархитектуре E2K, если коды не будут почти линейными [1]. Буфер TLB для команд имеет емкость 64 строки и является полностью ассоциативным.
Кроме рассмотренных типов кэш-памяти в E2K представлен специализированный кэш предварительной выборки, который разработчики назвали буфером предварительной подкачки. Он является частью устройства доступа к массивам (этот блок на рис.2 не представлен) и задействуется только при работе с массивами в циклах. Его емкость составляет всего 4 Кбайт, и он состоит из 2 банков с 2 портами в каждом из них. За один такт в буфер можно считать, следовательно, до 4 слов длиной 8 байт. Буфер организован как очередь FIFO и имеет до 64 зон предварительной выборки.
Задача этого буфера - та же, что и у работающих с ним команд типа «prefetch», имеющихся у многих современных процессоров (SGI R10000, Intel Pentium III, AMD K6-3 и т.д.): обеспечить возможность предварительной выборки данных заранее, до того, как они реально понадобятся, а в данном случае - опережающей выборки в цикле. Такая выборка, происходящая одновременно с выполнением тела цикла, позволяет скрыть задержки при обращении к оперативной памяти. Важно, что эта особенность E2K позволяет ускорить работу с операциями типа «сборки» (gather), когда выбираются несмежные элементы массива.
Ясно, что для микропроцессора высшего уровня производительности кэша второго уровня емкостью
256 Кбайт мало, и необходимо комплектовать процессор еще и внешним кэшем третьего уровня. В Е2К предусматриваются два варианта подключения третьего уровня - кэш: непосредственно к процессору Е2К, что позволяет разгрузить «системную шину» - коммутатор, или через набор коммутаторных микросхем.
Как и у многих современных RISC-процессоров, в частности, Sun UltraSPARC и Alpha 21264, вместо системной шины в E2K будет применяться коммутатор. В наборе микросхем планируется обеспечить поддержку
600-мегагерцевой памяти, построенной по технологии RAMBUS. В Е2К предусмотрено два независимых порта по 32 байта каждый, работающие на частоте 400-600 МГц.
Функциональные устройства
ФУ E2K, как это уже было указано выше, разнесены по двум кластерам (рис. 2). В отличие от Alpha 21264, эти кластеры содержат по 3 одинаковых целочисленных конвейера - АЛУ (правда, один из кластеров имеет также ФУ деления - целочисленного и с плавающей запятой). Такая симметрия кластеров по АЛУ дает преимущество по сравнению с Alpha 21264, поскольку практически любая команда может быть направлена в любой кластер.
В каждом кластере представлены также адресные сумматоры (на рис. 2 не указаны), которые имеются для 2 из 3 путей («каналов») данных. В результате каждый кластер может одновременно выполнять до 2 операций загрузки регистров или 1 операцию записи в оперативную память; cоответственно 2 кластера - до 4 операций загрузки регистров или до 2 записей в оперативную память. Возможен и смешанный случай: 2 загрузки плюс одна запись.
Кроме того, имеется 4 канала для данных с плавающей запятой, по 2 на кластер. В каждом канале может выполняться команда типа MADD - «умножить-и-сложить», что дает темп 8 результатов с плавающей запятой за такт. Это вдвое больше, чем у наиболее «продвинутых» в этом смысле RISC-процессоров HP PA-8500 [10], и при тактовой частоте 1,2 ГГц дает пиковую производительность 9,6 GFLOPS. Эта величина уступает лишь векторным процессорам Hitachi S3800. Темп в 8 результатов за такт связан с особенностями реализации команды MADD: она осуществляется в форме последовательного выполнения умножения и сложения, причем результат первой части команды не помещается в регистр, а подается на вход второй части команды. Такое зацепление напоминает известную схему, реализованную еще в Cray-1. Аналогичная схема применяется также в SGI R10000, однако в нем в команде MADD задействуется сразу 2 ФУ, так что темп выдачи результатов равен числу ФУ.
Следует также отметить, что и сам набор команд E2K «богаче», чем у традиционных RISC-процессоров: в нем представлены четырехадресные команды, например, типа d=a+b+c. Такого нет и в IA-64 [6]. Что касается команд с плавающей запятой, то кроме полной поддержки IEEE754 в E2K реализована работа с 80-разрядным представлением Intel x86. При этом операнды хранятся в парах 64-разрядных регистров E2K. Правда, сложение/умножение таких чисел не полностью конвейеризовано. Кроме того, для приближения системы команд E2K к x86 в E2K реализованы также команды расширения ММХ.
Интересно сопоставить длины конвейеров E2K и Alpha 21264. В E2K целочисленный конвейер имеет длину
8 тактов (собственно выполнение идет на седьмом такте, а обратная запись - на восьмом) против 7 тактов в Alpha 21264. Длина «вещественных» конвейеров на этапе выполнения составляет
4 такта, как и в Alpha 21264. Конвейер загрузки регистров/записи в оперативную память в обоих процессорах имеет длину 9 тактов.
Таблица 3. Времена выполнения основных операций E2K (в тактах)
| Операции | Задержка | Темп |
| Целочисленное АЛУ | 1 | 1 |
| Загрузка/запись из/в кэш первого уровня | 2 | 1 |
| Загрузка/запись из/в кэш второго уровня | 8 | 1 |
| Вещественное сложение | 4 | 1 |
| Умножение | 4-5 | 1 |
| Веществ. умножение-и-сложение | 8-9 | 1 |
| Деление 32 разряда | 10-13 | 2 |
| Деление 64 разряда | 10-17 | 2 |
| Вещественное деление (32/64) | 11/14 | 2 |
| ММХ, сложение/вычитание | 1 | 1 |
| ММХ, умножение/деление | 2 | 1 |
Однако следует отметить два важных обстоятельства: 1) в 21264 команда в среднем находится 4-5 тактов в очереди команд перед тем, как она выдается в ФУ, что увеличивает фактическую длины конвейера; 2) благодаря наличию в Е2К команды подготовки перехода, «зазор» между командой, формирующей условие перехода и самим переходом составляет всего 3 такта, что в 2 раза меньше, чем в 21264. Поэтому разработчики имеют основания утверждать, что конвейер Е2К фактически гораздо более короткий, чем в 21264. Данные о временах выполнения команд приведены в табл. 3.
Что касается количества одновременно выполняемых операций, то Е2К обеспечивает очень высокий уровень: в команде их кодируется до 23 (сюда кроме арифметико-логических операций входят также доступ в оперативную память, приращение индекса массива и т.п.). Ясно, что эффективные показатели параллельной работы ФУ у E2K выше, чем у всех суперскалярных процессоров.
Переходы и предикаты
В архитектуре E2K, как и в IA-64, делается все, чтобы по возможности исключить обычные операции перехода. Для этого в E2K имеется 32 одноразрядных регистра-предиката, причем команда способна сформировать до 7 предикатов: 4 в операциях сравнения в АЛУ и еще 3 - в операциях логики с предикатами (в 3 предикатных слогах, табл. 1).
Хотя в IA-64 предикатных регистров формально в 2 раза больше, чем в E2K, реально их практически столько же, так как в IA-64 хранятся пары - предикат и его отрицание. В IA-64 поля предикатов всегда представлены в команде, а в E2K - могут отсутствовать. Предикаты могут использоваться в канале АЛУ или в канале доступа к массивам; для указания на это используются условные слоги, содержащие маски предикатов и ФУ. Всего в этих слогах может кодироваться до 6 предикатов, указывающих на то, нужно ли выполнять соответствующие операции из «широкой» команды.
Если условие перехода удается вычислить до выполнения этого перехода, компилятор стремится применять предикатные вычисления, чтобы обойтись без перехода вообще. Если же это не удается, компилятор порождает явные спекулятивные коды. Спекулятивные вычисления в более ограниченном масштабе применяются в суперскалярных микропроцессорах (Alpha 21264, R10000 и др.), но в них этим занимается исключительно аппаратура.
Компилятор E2K порождает коды для обоих ветвей программы, возникающих при условном переходе, и, пользуясь большим числом ФУ и регистров, заставляет процессоры выполнять обе ветви программы. Та же процедура применяется и в IA-64. До тех пор, пока условие перехода остается неизвестным, обе ветви выполняются спекулятивно. Когда, наконец, условие найдено, выбираются нужные результаты. Признак спекулятивного выполнения взводится при этом в специальном бите в коде операции в соответствующем слоге. При возникновении ситуации исключения (exception) результат снабжается тегом недействительного значения. По мнению [1], это обеспечивает такие же возможности, как команды спекулятивной загрузки регистров IA-64, но реализованные в более общем виде.
Если в процессе спекулятивного выполнения условие стало известным, ненужная ветвь программы должна быть «сброшена» подобно тому, как это делается в конвейерах современных процессорах при неудачных предсказаниях переходов. Накладные расходы в подобных случаях весьма высоки (11 тактов в Alpha 21264), и разработчики процессоров стремятся к их уменьшению и увеличению точности предсказания перехода. Последнего в E2K делать нет необходимости, а для сокращения накладных расходов в E2K применяется так называемая операция подготовки перехода.
Она считывает команды из кэша по адресу перехода (или помещает их в кэш, если их там еще нет), и выполняет первые 4 стадии общего конвейера. Такая подготовка не зависит от условия перехода и может быть выполнена заранее. Когда переход происходит, команды по новому адресу частично уже будут выполнены. E2K может выполнять одновременно до трех операций подготовки перехода.
В файле предикатов E2K, как и в регистровом файле, используются окна. Этот оконный механизм предикатов E2K, как и аналогичное вращение предикатных регистров в Merced, позволяет эффективным образом организовать прологи и эпилоги циклов.
К заоблачным высотам
Мы не остановились еще на целом ряде интересных особенностей архитектуры E2K, в первую очередь на тегировании данных, поддерживаемом во всей линейке процессоров ЭВМ «Эльбрус». Среди других особенностей E2K можно отметить сегментно-страничную организацию и поддержку мультипрограммирования в стиле x86. В сочетании с разработанными средствами двоичной компиляции и специальными аппаратными средствами ее поддержки [1] это позволяет выполнять x86-коды на E2K. Поддерживается также двоичная компиляция для SPARC-архитектуры. Очевидная близость IA-64 к E2K позволяет рассчитывать и на эффективную компиляцию кодов IA-64 в будущем. По сравнению с DEC FX!32 двоичная компиляция в E2K более эффективна и допускает статическое компилирование [1].
В настоящий момент разработка E2K еще не завершена. Имеется только исполняемое описание Verilog, а детализация до уровня транзисторов еще предстоит. Для достижения планируемых показателей необходима 0,18-микронная технология изготовления. Однако E2K может достигнуть более высокой производительности (SPECint95/fp95 = 135/350), чем Merced (SPECint95/fp95=45/70 при 800 МГц [1]), при меньшей площади кристалла и меньшем энергопотреблении (табл. 2).
Мы не пытаемся здесь оценить вероятность успешного завершения проекта разработки E2K (см. [1,2]). В любом случае она представляет огромный интерес и, помимо прочего, дает нам возможность предположить, какими свойствами сможет обладать Merced.
Михаил Кузьминский (kus@free.net)— старший научный сотрудник Центра компьютерного обеспечения химических исследований РАН (Москва).
Литература
1. К. Dieffendorf, Microprocessor Report, 1999, v.13, №. 2, p. 1.
2. М. Кузьминский, «Сomputerworld Россия», 1999, № 8.
3. М. Кузьминский, «Сomputerworld Росия», 1997, № 47.
4. B.A. Babajan e.a., Elbrus Software Methodology: Instrumentation-Experience, IFIP Conference, 1989.
5. Р. Хокни, К. Джессхоуп, Параллельные ЭВМ, М., Радио и связь, 1986.
6. IA-64 Application Instruction Set Architecture Guide, Rev. 1.0, Intel, Hewlett-Packard, 1999.
7. М. Кузьминский, «Открытые системы», 1998, № 1, cтр. 7.
8. В. Шнитман, «Открытые системы», 1996, № 2, cтр. 5.
9. М. Кузьминский, «Computerworld Россия», 1995, № 2.
10. М. Кузьминский, «Открытые системы», 1997, № 3, cтр. 6.
