В бесконечной гонке за мегагерцами не все так просто: то переход на новый техпроцесс трудноосуществим, то тепловыделение не позволяет поднимать частоту, то бешеные цифры мегагерц не гарантируют столь же сумасшедшей производительности.
Однако специалисты находят решения, и часто самое эффективное — повышение производительности процессора интенсивным способом, при котором желаемые результаты достигаются не за счет увеличения тактовой частоты, а благодаря применению новых технологий. О кристаллах AMD Athlon XP с технологией QuantiSpeed мы уже писали («Мир ПК», №12/01, c. 12). Пришла пора сообщить и о наработках компании Intel, в основе ее технологии Hyper-Threading лежит иной принцип, и предназначена она для использования в серверах.
Высокотехнологичные фокусы
Процессоры, выполненные по технологии Hyper-Threading, могут одновременно обрабатывать две нити процессов, состоящие из потоков данных и команд двух разных приложений или различных частей одного. Эта новация позволяет максимально загрузить имеющиеся процессорные ресурсы: например, если один поток данных использует не все вычислительные блоки, то оставшиеся будут заняты второй нитью процессов. В результате повышается общее быстродействие системы. По данным компании, сейчас прирост производительности составляет 18—30% для двухпроцессорных систем (в зависимости от типа приложения). Однако в дальнейшем при оптимизации ПО под Hyper-Threading этот показатель будет увеличиваться.
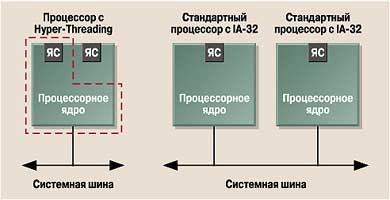
На рисунке схематично представлены система с двумя обычными процессорами IA-32 (32-разрядная архитектура) и ЦП, построенный по технологии Hyper-Threading. Если при использовании двухпроцессорной системы имеются два отдельных физических устройства, то в случае с Hyper-Threading фактически процессор один, но для ПО он виден как два логических.
В общем, ничего нового — классический фокус с вытаскиванием двух платков из кармана, в который положили один, — но всегда любопытно, как удается фокуснику удвоить количество предметов и не случится ли так, что интересная идея не принесет практических плодов?
Клонирование регистров
При «двухпотоковой» обработке данных процессор вынужден сохранять информацию обоих потоков (например, блок с плавающей запятой в ЦП Xeon один, и если он занят выполнением одной из нитей, то вторая вынуждена где-то ожидать освобождения блока). Для «временного поселения» команд и данных простаивающих нитей дублируются некоторые внутренние регистры процессора и добавляются схемы обеспечения корректной работы с двумя нитями. В результате площадь кристалла пришлось увеличить на 5%. Вполне разумная плата за прирост производительности в 10%. Естественно, двум процессам придется делить и кэши всех уровней. Для большей эффективности объемы, отданные разным потокам, могут варьироваться процессором, хотя технически реализовать это несколько сложнее, чем просто отвести каждой нити половину кэша. Впрочем, организация кэша может быть изменена в будущих моделях ЦП, если иной метод деления кэша на практике окажется эффективнее.
Интересно, что, возможно, дополнительные регистры, необходимые для реализации Hyper-Threading, были включены в состав еще предыдущих Xeon. Прямых подтверждений этому получить не удалось, но опровержений также нет, а по заявлению Intel единственное (!) отличие новых ЦП — увеличенный вдвое кэш. Вероятно, по расчетам Intel, теперь его как раз хватит на хранение данных двух задач. Ускорить продвижение технологии должна возможность устанавливать новые процессоры в существующие двухпроцессорные системы после некоторой модификации BIOS. Естественно, предусмотрено отключение технологии Hyper-Threading в BIOS для случаев, когда ее использование нецелесообразно.
А домой забрать можно?
Конечно, большой интерес вызывает возможность переноса технологии Hyper-Threading на процессоры для настольных компьютеров, ведь кэш второго уровня в Pentium 4, созданных по 0,13-мкм технологии, тоже увеличен до 512 Кбайт. Но на этом пути еще много препятствий, и случится это, очевидно, не скоро. Пока явный выигрыш от Hyper-Threading заметен только на серверных приложениях. К тому же использование этой технологии потребует некоторой доработки наборов микросхем, так как их надо «обучить» назначать прерывания для двух процессоров. Заметим, что системная логика подавляющего большинства настольных ПК не рассчитана на работу в многопроцессорной конфигурации. Можно, конечно, устанавливать процессоры с Hyper-Threading на системные платы с наборами микросхем, поддерживающими двухпроцессорные конфигурации, но такие решения получатся неоправданно дорогими.
|
| Рис. 1. ЯС — ячейки состояния, хранящие данные обрабатываемого потока. Пунктирной линией обведены компоненты, составляющие логический процессор |
Еще одна проблема касается и серверных систем. ОС и приложения видят физический процессор с Hyper-Threading как два логических (см. рис.1). Если для программ оптимизация под мультипроцессорность в данном случае не критична (можно просто запустить две параллельно), то для операционной системы она обязательна. Однако большинство пользователей работают с ОС компании Microsoft, а версии Windows, выпускаемые для домашних ПК, не поддерживают многопроцессорность. К сожалению, в России способ решения этой проблемы — пиратский — известен. Цивилизованному пользователю интересно, почему это надо платить за лицензию на ОС, поддерживающую вдвое большее количество ЦП, чем установлено в системе? Более того, при использовании суперсерверов с большим количеством ЦП разница в цене ОС для реально установленного и поддерживаемого числа процессоров может быть сравнима со стоимостью аппаратных средств. Intel ведет переговоры с производителями операционных систем, и можно рассчитывать, что новые версии будущих ОС научатся различать физически разные процессоры и ЦП с поддержкой Hyper-Threading.
Обманутая ОС
Отвлечемся от финансовых вопросов. Загрузка ОС на ЦП с поддержкой Hyper-Threading происходит так же, как и в случае двух (или более) процессоров. Аппаратно процессор устроен так, что операционная система при загрузке видит один логический процессор (это аналог нулевого в двухпроцессорной системе). На нем происходят все операции до того момента, как становится возможно опознать другие присутствующие на плате процессоры. После этого момента ОС по своему усмотрению (естественно, в зависимости от выполняемых программ) выбирает, какие ЦП должны работать: нулевой, все (Hyper-Threading в действии) или первый (нулевой тогда будет приостановлен).
|
|
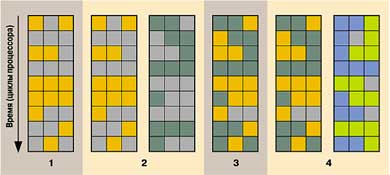
Рис.2. Загрузка процессоров
Прямоугольники — исполняющие блоки гипотетического процессора. Оранжевые и зеленые работают, серые простаивают. 1 — выполнение одной нити (блоки, занятые ее исполнением, закрашены оранжевым) на обычном процессоре; 2 — выполнение двух нитей (оранжевый и зеленый цвета) на двух разных процессорах стандартной двухпроцессорной системой; 3 — одновременное выполнение двух нитей на одном процессоре с технологией Hyper-Threading; 4 — выполнение четырех нитей на двух процессорах (четыре разных цвета) двухпроцессорной системы с технологией Hyper-Threading |
На рис.2 схематически показана реализация технологии Hyper-Threading. Условно отображено три исполняющих процессорных блока. Мы видим, что в среднем у процессора в каждый момент времени загружена только половина блоков. Однако если не изменить тип задачи (скажем, не перейти от работы в Word к вычислению экспоненты с точностью до сотого знака), то повысить эффективность использования ресурсов на обычном процессоре невозможно. Такая же ситуация может сложиться и в двухпроцессорной системе. Хотя выполняются две цепочки задач, вычислительные блоки загружены только наполовину (ну не требуется пользователю в данный момент проводить ресурсоемкие вычисления, ему всего лишь письмо надо написать и файл из Интернета скопировать). В такой ситуации разумно применение процессора с технологией Hyper-Threading: одновременно запускаются две задачи на одном процессоре (рис.2, столбец 3), в результате простаивающих блоков практически нет. Двухпроцессорная система тоже не останется без дела — параллельно будут обрабатываться четыре потока (аналогичные рассуждения можно привести для любого количества процессоров).
Запутавшийся Hyper-Threading
Выполнение каждой отдельно взятой задачи при использовании Hyper-Threading в принципе может замедлиться: уменьшенный объем доступной кэш-памяти увеличит число обращений к медленному ОЗУ, к тому же иногда один поток будет занимать блоки, необходимые второму. Но даже и в этом случае параллельное выполнение двух цепочек займет меньше времени, чем поочередное. К тому же при выборе исполняемого потока приоритет отдается тому, который требует больших процессорных ресурсов. Ведь главная цель применения Hyper-Threading — не выполнение двух задач одновременно, а максимально возможная загрузка процессорных ресурсов.
|
|
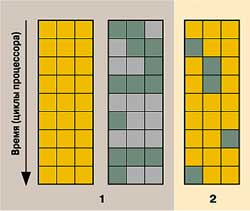
Рис.3. Задумчивый Hyper-Threading
Прямоугольники — исполняющие блоки гипотетического процессора. Оранжевые и зеленые работают, серые простаивают. 1 — выполнение двух нитей на стандартной двухпроцессорной системе; 2 — одновременное выполнение двух нитей на одном процессоре с технологией Hyper-Threading |
Однако принцип передачи процессорных вычислительных мощностей более ресурсоемкой нити таит подводные камни. На рис.3 показана ситуация, когда одна нить занимает практически все вычислительные мощности процессора и не оставляет ресурсов для выполнения второй. В таком случае ЦП с технологией Hyper-Threading работает практически как обычный. Плохо то, что вся работа первой нити может заключаться в ожидании конца пустого цикла: происходит загрузка, сравнение и переход данных будущего, текущего и предыдущего витков цикла соответственно, т. е. полезных вычислений не происходит, но системные ресурсы заняты. Двухпроцессорная система в этом случае эффективно использует хотя бы часть своих ресурсов: первый процессор крутит пустой цикл, а второй работает со второй нитью.
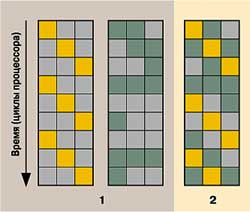
|
|
Рис. 4. Тише едешь — дальше будешь
Прямоугольники — исполняющие блоки гипотетического процессора. Оранжевые и зеленые работают, серые простаивают. Для нити, отмеченной оранжевым цветом, использована команда Pause 1 — выполнение двух нитей на стандартной двухпроцессорной системе; 2 — одновременное выполнение двух нитей на одном процессоре с технологией Hyper-Threading |
Чтобы избежать пустой траты ресурсов, Intel предлагает использовать в программах директиву Pause. Она разрешает нити выполнять только одну операцию за такт, тогда на нашей схеме поток будет занимать не больше одного квадратика (схематично представленного вычислительного блока) и всегда найдутся свободные вычислительные ресурсы для выполнения второго потока. Но если в циклах происходят «результативные» вычисления, введение Pause снизит скорость решения задачи. И все же эффективность работы системы в целом сильно упасть не должна: часть ресурсов будет использована для операций над данными второй нити, к тому же в общем случае даже при интенсивных вычислениях необходимы перерывы для подкачки данных. Вообще-то при решении задач, полностью мобилизующих ресурсы процессора, использование Hyper-Threading может оказаться неэффективным (например, выполнение сложных математических операций над массивом, умещающимся в кэш) и при загрузке ПК ее следует отключить.
Еще один способ избежать пустых циклов — использование директивы HALT, по которой ОС приостанавливает работу процессора. Ее применение имеет смысл при ожидании циклом события, которое произойдет не ранее определенного момента (например, при посылке запроса на печать ответ с принтера не может прийти мгновенно). В этом случае все ресурсы процессора будут некоторое время полностью освобождены для выполнения другой нити.
Когда?
Иногда технологии выглядят очень привлекательными, но трудно пробиваются на рынок .Bluetooth, например, широко рекламировалась год назад, но и по сей день ее глобальное распространение под вопросом. В данном случае, похоже, этого не произойдет, Hyper-Threading на серверном рынке должна появиться в начале этого года. 9 января вышел процессор Xeon c 512-Кбайт кэшем, он официально поддерживает эту технологию. Современные платы на системной логике i860 смогут полностью поддерживать работу кристаллов в двухцепочечном режиме (для этого ОС также должна будет поддерживать работу двух или четырех ЦП), после модернизации BIOS. Некоторое время может потребоваться на отладку систем, но в феврале мы надеемся увидеть первые законченные решения, в которых будет реализован Hyper-Threading.
Xeon 1,8 ГГц; 2А ГГц; 2,2 ГГц
Оценка: выполнен по 0,13-мкм технологии. Модель 2А ГГц имеет реальную частоту 2 ГГц, литера «А» прибавлена, чтобы отличать продукт от 2-ГГц, выполненного по старой технологии.
Цена: 251, 417 и 615 долл. соответственно.
Intel
Школьный курс по Hyper-Threading
Возможно, легче понять принцип технологии Hyper-Threading на примере школы. Количество комнат для семилетних первоклассников определяется исходя из средней численности учащихся за последние несколько лет. Скажем, им отведено три помещения. Однако в случае недобора возникает переизбыток комнат. Чтобы не сокращать штаты и заполнить школу, можно организовать прием шестилетних детей, хотя придется несколько перестроить процесс обучения и пригласить специального методиста. Так и в случае применения Hyper-Threading те данные, которые поступили бы в обычный процессор только в следующем цикле (как и дети шести лет в нашем примере), обрабатываются одновременно с предыдущими (детьми-семилетками) на простаивающих блоках (шестилетние дети учатся в комнате, которая иначе пустовала бы). Продолжая сравнение, можно поставить в соответствие применению двухпроцессорной системы без Hyper-Threading открытие еще одной школы, что производительнее (там целых три комнаты для шестилетних первоклассников), но дороже.