 Не исключено, что уже через десять-пятнадцать лет суперкомпьютеры в их нынешнем, преимущественно кластером облике, вымрут – уйдут в небытие популярные и простые HPC-кластеры, на тестах обеспечивающие тера- и петафлопы, но неэффективные при выполнении реальных приложений. Скоро низкий КПД этих монстров, разбросанных ныне по многочисленным университетам и лабораториям России и всего мира, будут сравнивать даже не с паровозами, а с домашними печами для выплавки железа, стоявшими во времена «большого скачка» (1958-1960 годы) в каждом китайском крестьянском дворе.
Не исключено, что уже через десять-пятнадцать лет суперкомпьютеры в их нынешнем, преимущественно кластером облике, вымрут – уйдут в небытие популярные и простые HPC-кластеры, на тестах обеспечивающие тера- и петафлопы, но неэффективные при выполнении реальных приложений. Скоро низкий КПД этих монстров, разбросанных ныне по многочисленным университетам и лабораториям России и всего мира, будут сравнивать даже не с паровозами, а с домашними печами для выплавки железа, стоявшими во времена «большого скачка» (1958-1960 годы) в каждом китайском крестьянском дворе.
Возможно также, что технологию их преемников будут называть On-Demand HPC или HPC as a Service, но в любом случае современные кластеры будут заменены разнообразными вычислительными облаками, предоставляющими вычислительные мощности по требованию. Сказанное вовсе не означает, что прогресс остановится и не будут создаваться еще более мощные уникальные суперкомпьютеры (начав с печей во дворе, Китай создал суперкластер Shuguang-6000 с относительно неплохими показателями производительности). Безусловно будут, но на других началах, а вовсе не путем суммирования производительности отдельных узлов, однако это особая история.
В реальности именно такого развития событий убеждает родство облачных архитектур и кластеров – многое уже готово, осталось сделать один естественный эволюционный шаг. Если смотреть только на «железо», то и HPC-кластеры, и существующие сегодня облака представляют собой не что иное, как серверные пулы, но пока на этом сходство ограничивается, поскольку кластеры и облака создавались для разных типов приложений и внимание разработчиков было сосредоточено на разных проблемах. Кластеры типа Beowulf строились как дешевая альтернатива существовавшим тогда машинам для расчетных задач и задач моделирования, а облака появились в другую эпоху, когда потребовалось в массовом порядке решать не слишком ответственные задачи, не предполагающие значительных вычислений, но связанные с большими объемами данных. Отсюда отличия в архитектурах кластеров и облаков.
Во-первых, разные требования к межузловым соединениям – в кластерах конфигурация неизменна, и требуется более высокая производительность, чем в облаках. Во-вторых, в облаках изначально предполагается, что производительность узла выше, чем требования отдельной, работающей на нем задачи, отсюда вывод – чтобы использовать все ресурсы узла, необходима виртуализация, а в HPC-кластерах каждый узел работает с максимальной производительностью и виртуализации не требуется. Наконец, в кластерах не мыслится какая-либо миграция задач.
Но потенциал облаков не дает покоя потенциальным потребителям HPC. Например, ИТ-подразделению New York Times удалось средствами Amazon Elastic Cloud всего за сутки перевести весь свой архив, содержащий 11 млн статей (4 Тбайт), из формата TIFF – чем не суперкомпьютерная скорость, правда, в приложении к гигантским объемам данных? Поэтому, несмотря на вроде бы очевидную непригодность стандартных облаков для целей HPC, сохраняется соблазн как-то использовать их для параллельных вычислений, что стимулирует желание оценить производительность облаков на HPC-задачах, и такого рода попытки были предприняты.
Самый простой эксперимент провели Джеффри Наппер и Паоло Биеинести (Can Cloud Computing Reach The TOP 500?). Они запускали тест LINPACK на облаке Amazon Elastic Compute Cloud (EC2), заказывая сверхбольшие (extra-large) узлы стандартной (standard) и повышенной (high-CPU) производительности. На одном узле быстродействие составляло 80% максимального, при двух узлах производительность каждого из них падала до 20%, а при увеличении числа узлов до восьми удельная производительность оказалась меньше 10%. При возрастании числа узлов резко увеличивается удельная стоимость вычислений, поэтому нет ничего удивительного, что итогом исследований стало простое утверждение о неготовности нынешних облаков к задачам HPC.
Более взвешенную оценку результатов, полученных в ходе прямого сравнения EC2 с кластерами, дал Эдвард Уолкер из Техасского университета в Остине: «Возможность использования коммерческих облаков для HPC-приложений выглядит привлекательной. Она освобождает исследователей от необходимости быть привязанными к определенным вычислительным системам, открывает возможность выбора из наиболее приемлемых по цене и качеству предложений и в конечном итоге стимулирует рыночную конкуренцию. Однако показатели производительности Amazon EC2 еще довольно низки, и для того, чтобы облако стало реальной альтернативой кластеру, производителям необходимо проделать дополнительную работу».
Еще более оптимистична точка зрения отца grid Яна Фостера. Его рассуждения строятся на том, что нужно сравнивать не время выполнения теста, а общее время, необходимое для решения задачи. Он повторил свой эксперимент дважды, выполнив тест LU пакета NASA NPB 2.3 по решению уравнения Навье-Стокса сначала на 32 узлах, арендованных в Amazon EC2, а затем на кластере с таким же количеством узлов. Разница во времени счета выполнения была четырехкратна, но суммарное время решения задачи складывается не только из времени счета, но еще и из времени ожидания доступности ресурсов.
Для EC2 это время включало 5 минут ожидания и 100 секунд полезной работы, причем оказалось, что время ожидания практически не зависит от загрузки ЦОД Amazon. С другой стороны, время ожидания на кластере, работающем в пакетном режиме, является случайной величиной, существенно зависящей от того, как организовано прохождения задач, и от степени загруженности – каждый кластер характеризуется показателем прогнозирования очереди QBETS (queue prediction service). В частности на сайте, где выполнял свое сравнение Уолкер, вероятность получения 32 узлов за время менее 5 минут равна всего лишь 34%, а для получения 97% ресурсов надо было ожидать около 100 часов. Вывод не сложен: да, время счета на кластере меньше, но вероятность выполнить задачу с привлечением запрошенных ресурсов всего одна треть. Такова расплата за несовершенство пакетного режима.
Выводы этих и других исследователей сходятся в том, что существующие облачные инфраструктуры страдают еще заметной деградацией производительности по мере роста числа используемых узлов – в отдельных случаях с этим можно смириться, но в большинстве – нет. Как преодолеть эту слабость облаков? Этот вопрос поставила перед собой общественная организация HPC Advisory Council, объединившая крупных производителей оборудования, сборщиков кластеров, включая отечественную компанию «Т-платформы», поставщиков ПО и наиболее влиятельных пользователей HPC. Цель деятельности этого объединения состоит в создании нового подхода к проведению высокопроизводительных вычислений на базе принципов Supercomputing as a-Service или High Performance Computing as a Service. Если такой подход получит распространение, то широкая научная общественность сможет выполнять большие объемы вычислений с той же легкостью, с какой нынешние облака, использующие технологии MapReduce, справляются с колоссальными объемами данных.
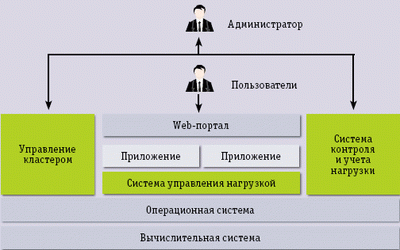
Цель HPC Advisory Council достижима, но необходимы специализированные HPC-облака с высокосортной системой межсоединений типа InfiniBand, управляющим ПО и виртуализацией. Иначе говоря, тот же кластер, но работающий по облачной схеме с доступом через Web. На первых порах можно отказаться от виртуализации с учетом того, что счетные задачи, в отличие от большинства других, полностью загружают ядра процессоров и оптимизация нагрузки не важна, но интерфейс через Web обязателен. Прототип такого решения показан на схеме.
В одной из университетских лабораторий под патронажем HPC Advisory Council по этой схеме были собраны вместе традиционная вычислительная система и современное ПО. Аппаратная основа состоит из 24 узлов – серверов Dell PowerEdge SC 1435 высотой 1U на двух четырехъядерных процессорах Quad-Core AMD Opteron 2382, объединенных через межсоединение Mellanox MT25408 ConnectX DDR InfiniBand и работающих под управлением операционной системы Red Hat Enterprise Linux. Отличительные облачные черты этой конфигурации придают: система управления кластером Penguin Computing Scyld, система управления нагрузкой Platform LSF HPC, а также система контроля и учета нагрузки Platform RTM. Продукты компаний Platform Computing и Penguin Computing взаимно дополняют друг друга, первые обеспечивают масштабируемость, вторые – сервисы.
Penguin Computing была создана в 1998 году и имеет достаточной широкий спектр предложений в области виртуализации кластеров. Ее продукт Scyld ClusterWare, полученный после приобретения в 2003 году компании Scyld, приближает кластеры по удобству управления к SMP-системам. Компанию Scyld основал Дональд Беккер, соавтор Томаса Стерлинга по изобретению Beowulf, сейчас он работает техническим директором Penguin Computing. Беккер в 2005 году одним из первых заговорил о виртуализации как о способе представления множества разрозненных ИТ-ресурсов в виде одного, в то время как VMware, Xen и другие сосредоточили свое внимание только на одной стороне виртуализации – на возможности предоставления одного физического ресурса в виде множества независимых логических.
В Scyld ClusterWare имеется одна точка управления – мастер-узел, с помощью которого можно за считанные секунды собрать из имеющихся ресурсов требуемую конфигурацию. Если обычная установка ОС на узел кластера занимает от четверти часа до получаса и еще требует дополнительной настройки, то с использованием подхода, реализованного в Scyld ClusterWare, эта процедура автоматизирована и время сокращается до 20 секунд. Важно, что виртуализация распространяется на ядра, поэтому администратор «видит», скажем, не 100 четырехпроцессорных узлов, а один 400-процессорный SMP-сервер, причем вся работа с пользователями, паролями и другие служебные операции полностью сосредоточены на «мастере».
Канадская компания Platform Computing была создана участниками проекта Utopia Университета Торонто, целью которого было изучение средств балансировки нагрузки для больших гетерогенных распределенных компьютерных систем. По итогам этой работы Сонянг Джоу, Джиньвен Ванг и Бинг Ву создали компанию, основным продуктом которой до последнего времени остается Load Sharing Facility (LSF) – средство для управления работами, позволяющее выполнять задания в пакетном режиме в распределенной гетерогенной сети компьютеров, управляемых Unix, Windows и другими ОС. Система LSF состоит из трех компонентов: подсистемы управления распределенными ресурсами DRMAA (Distributed Resource Management Application API), подсистемы управления заданиями HPC Profile Basic и подсистемы LSF Perl API, служащей для поддержки API на языке Perl.
Долгое время Platform Computing оставалась нишевым игроком, но с появлением облаков ситуация стала меняться, и компания выпустила адаптированную под задачи IaaS (Infrastructure as a Service) версию продукта Platform Infrastructure Sharing Service. Эта версия задумана как инструмент создания внутренних облаков предприятий из имеющихся собственных ресурсов, то есть область ее применения шире, чем HPC. На сегодняшний день это единственное нейтральное по отношению к используемым аппаратным и программным технологиям решение, обеспечивающее вызов существующих приложений по требованию.
Во время испытаний, проведенных Advisory Council, собранная конфигурация сопоставлялась с двумя специализированными кластерами, на которых решались задачи гидродинамики с использованием пакета ANSYS FLUENT и моделирования механических задач методом конечных элементов средствами пакета LSTC LS-DYNA. Каждый из этих кластеров имеет по 48 ядер на процессорах Quad-Core AMD Opteron, и им ставилась в соответствие половина облака, собранного по проекту HPC Advisory Council – те же 48 ядер. Время выполнения тестов FLUENT и LS-DYNA на выделенных кластерах и в облаке практически совпало.
В конце прошлого и в начале нынешнего года отдельные компании стали предлагать не только технологии для создания частных облаков на принципах HPCaaS, но и услуги, распространяемые через Web. Одной из первых по этому пути пошла Penguin Computing, предоставившая HPC-сервисы Penguin on Demand (POD). Облако построено примерно по уже описанной схеме, но с добавлением графических процессоров nVidia Tesla. От обычных облаков оно отличается отсутствием виртуализации на уровне серверов, не требуемой для HPC, а также наличием дополнительного ПО и межсоединений InfiniBand. Пользователи получают не только вычислительную мощность, но и необходимую консультационную помощь. Для оценки производительности POD была использована реальная задача из области биоинженерии – на Amazon EC2 она решалась 18 часов, а на POD менее получаса.
В феврале 2010 года в роли провайдера HPCaaS выступила компания SGI со своим проектом Cyclone, включающим три платформы от SGI: кластеры x86 (Altix ICE) с горизонтальным масштабированием на базе InfiniBand, гибридные серверы с CPU и GPU (Altix XE с опцией GPU) и классические SMP-системы Altix 4700 на процессорах Itanium. В этом году к ним прибавятся Altix UltraViolet на базе Nehalem-EX. В гибридных платформах будут использоваться оба известных типа GPU nVidia Tesla и AMD/ATI. Точный размер облака пока не оглашается, но, по оценкам руководства SGI, речь идет о тысячах процессоров.
В качестве операционной системы служит Linux (SUSE либо Red Hat), для управления кластерами используется менеджер SGI ISLE Cluster Manager и Altair PBS Pro для управления потоком работ. С учетом полного задействования процессоров задачами HPC, технологии виртуализации не используются. В роли провайдера SaaS на нынешний день Cyclone предлагает программы для решения 18 задач из пяти прикладных областей: биология, химия, динамика жидкостей, конечный элемент и разработка данных.
Будем надеяться на то, что судьба POD, Cyclone и других аналогичных начинаний окажется счастливее, чем судьба Sun Grid Compute Utility. По оценкам аналитической компании InterSect360 Research, рынок услуг в области HPC находится в том младенческом состоянии, когда выживание зависит от множества факторов и ни для кого нет никаких гарантий, хотя общий тренд – «по требованию» – очевиден.
Суперкомпьютеры и парадоксы неэффективности
Тема суперкомпьютерных технологий сейчас на слуху: суперкомпьютеры какой мощности необходимы России, в каком количестве и, главное, зачем? Потенциал современных высокопроизводительных систем огромен, но каков их реальный коэффициент полезного действия?
Направления развития отечественных высокопроизводительных систем
Государственная поддержка работ по созданию современных отечественных высокопроизводительных многопроцессорных вычислительных систем позволила получить некоторые результаты, однако предстоит сделать еще много, в частности в сфере получения адекватных оценок производительности.
MapReduce – будущее баз данных
Реляционные базы данных не могут вечно оставаться образцами совершенства – за сорок лет, прошедшие после их создания, изменился мир и хранимые данные, и есть все основания полагать, что наряду с другими технологиями в недалеком будущем свое место займут параллельные СУБД, использующие программную конструкцию MapReduce.
