Компьютерно-лингвистический подход позволяет организовать диалог пользователя с сетевой поисковой системой на естественном языке с учетом контекста, обратной связи и результатов предыдущего поиска.

Активный рост Всемирной паутины превратил Internet в огромное информационное пространство с разнообразным и зачастую плохо организованным содержимым. Пользователи сталкиваются с быстрым ростом объемов информации, нашедшим отражение в термине «информационная перегрузка». И если для просмотра отдельных Web-страниц достаточно минимального набора навыков, то поиск по запросам и навигация в Web-пространстве требуют большего [1].
Исследования поискового поведения опытных и начинающих пользователей Сети позволяют сделать несколько практических выводов. В частности, модель поискового поведения может послужить основой для улучшения интерфейсов и расширения функциональности существующих поисковых систем. В будущем они смогут полнее удовлетворять разнообразные потребности как экспертов, так и новичков. Кроме того, глубокое понимание трудностей, с которыми сталкиваются потребители в процессе поиска, необходимо при построении справочных систем [2].
Поведение Web-пользователей привлекает к себе внимание исследовательского сообщества. Теза Лоу и Эрик Хорвиц, например, предложили задействовать байесовские сети для моделирования последовательных запросов, с которыми пользователи обращаются к поисковой машине [3]. Эти сети могут дополнить поисковую машину назначенными вручную категориями предполагаемых информационных целей, позволяющими предсказывать модификации запросов. Ингрид Цукерман с коллегами говорят о возможности применять Марковские модели для предугадывания следующего запроса потребителя на основе предыдущих [4]. Однако в этих исследованиях не принимаются во внимание персональные характеристики пользователя и его опыт.
Разумеется, традиционные информационно-поисковые системы, основанные на использовании ключевых слов, могут обеспечить первый шаг в процессе поиска. Однако проблема состоит в том, чтобы выполнять поиск более точно и интеллектуально на основе знаний о пользователе, его намерениях, целях и т.п., чтобы улучшать результаты поиска, обходясь минимумом уточнений.
Наше исследование предполагает, что обратная связь с потребителем при таком общении может сыграть ключевую роль в уменьшении информационной перегрузки и получении искомой информации. Базовая лингвистическая эрудиция сделает поисковую систему более точной благодаря сужению запросов и идентификации намерений пользователя. Соответственно, мы исследуем генерацию интерактивных диалогов на естественном языке для библиографического поиска в Сети с целью улучшения процессов поиска и отбора информации при минимальном взаимодействии с потребителем. Основное внимание в нашем подходе уделяется совершенствованию парадигмы поиска с помощью методов компьютерной лингвистики и применения более подходящего поискового агента.
ПОИСК ИНФОРМАЦИИ
Многие поисковые машины, такие как Google и AltaVista, просматривают содержимое каждого Web-сервера, создавая индексированные базы данных по мере обнаружения документов. Однако при обращении к этим огромным БД пользователи встречаются с хорошо известными проблемами. В том числе они вынуждены тратить много времени на проверку того, содержат ли полученные результаты именно необходимые сведения. Кроме того, они часто получают столь значительное количество информации, охватывающей весьма широкую область, что отказываются от большей ее части и ограничиваются лишь небольшим набором документов.
|
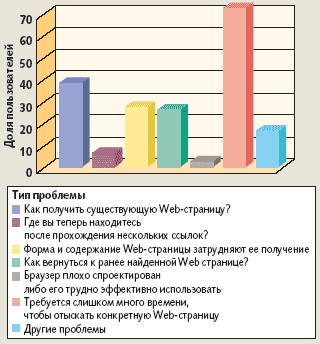
| Рис. 1. Препятствия к поиску в Web-пространстве могут иметь самую разную природу — от недостатка опыта до проблем дизайна |
Недавние исследования поведения Web-пользователей и связанных с ним практических проблем показывают, что для эффективного поиска информации в Сети требуется преодолеть множество препятствий [2]. Как показано на рис. 1, они могут иметь самую разную природу — от недостатка опыта (неумения получать существующие страницы) до проблем дизайна (браузер плохо спроектирован либо его трудно эффективно применять). Значительной части Web-пользователей требуется слишком много времени, чтобы найти конкретный документ или Web-страницу. Другие проблемы связаны с трудностями получения полезной и понятной информации. Анализ этих препятствий позволяет выявить две конкретные проблемы:
- современные поисковые системы не могут исследовать поведение пользователя, его намерения или профиль, чтобы собрать информацию, которая была бы полезной, например, для автоматизации рутинных задач;
- представление на базе ключевых слов, которое используют поисковые машины и информационно-поисковые системы, накладывает слишком много ограничений.
Действительно, многие поисковые системы не могут собрать базовые сведения о пользователе — отчасти потому, что для них не характерно получение неявной информации на уровне языкового общения, к которому часто прибегают потребители. Например, если в запросе на естественном языке используются неявные предположения или местоимения («Найти документы, которые содержат ...» или «Каковы планы путешествий Ее Величества на следующий год?»), то поисковая машина не найдет нужной информации. Что же касается точности и полноты поиска, система пропустит тысячи относящихся к делу документов, если запросы не содержат достаточного количества ключевых слов, позволяющих судить о подобии. Первая проблема относится к интеллекту поисковой машины и ее способностям адаптации, а вторая связана с представлением запроса, взаимодействием с пользователем и способностью системы воспринимать основообразующую (в том числе неявную) информацию, выраженную на естественном языке.
Чтобы справиться с этими проблемами, исследователи обратились к разработке интеллектуальных поисковых агентов [5]. Такие агенты по-новому применяют традиционную «паучью» технологию поиска и обычно являются «роботами», которых можно обучить поиску в Сети определенных типов информационных ресурсов. Владелец интеллектуального агента способен персонализировать его так, чтобы тот создавал индивидуальные профили или удовлетворял конкретные информационные потребности. Агент может быть автономным, т.е. самостоятельно судить о вероятной уместности материала. И чем чаще он служит инструментом поиска, тем выше становится его «мастерство» — агент учится на прошлом опыте. Потребителю предоставлены возможности пересмотра результатов поиска и отклонения любых информационных источников, не относящихся к делу или бесполезных. Агент хранит эту информацию в пользовательском профиле, чтобы задействовать ее при обучении и поиске.
Но даже современные подходы не позволяют устранить ряд проблем, включая информационную перегрузку, затраты времени на поиск и получение необходимых сведений. Некоторые поисковые системы не могут выполнить углубленный лингвистический анализ запроса и контекста, помогающий качественно осуществить поиск информации, которую пользователь действительно хочет найти. Для того чтобы справиться с этими ограничениями, отдельные системы теперь включают в процесс поиска как статистические переменные, так и лингвистические параметры. Однако данный подход все еще остается на стадии опытных разработок и базируется преимущественно на документах, представленных в рамках парадигмы «мешка слов», которая является базисной для многих информационно-поисковых систем.
В отличие от поиска, фильтрация подразумевает отбор документов на основании их содержимого. В качестве примера можно указать предложенную в [6] когнитивную систему фильтрации сведений со скрытой семантической индексацией для отбора новостных статей. Другой пример — система Infoscope [7], которая задействует агентов на основе правил, чтобы следить за поведением пользователя и предлагать варианты.
Преодолевая трудности создания подходящих профилей в ходе диалога, некоторые современные системы фильтрации позволяют пользователям выбирать в качестве типовых один или несколько релевантных документов [8], вместо того чтобы требовать прямого и явного определения области интересов. Другие системы пытаются построить профили по поведению потребителя. Однако этот подход недостаточно практичен, поскольку пользователи не всегда фокусируются на реальных целях и порой путешествуют по Сети без явного направления, что может привести поискового агента к неверным выводам об их предпочтениях.
С точки зрения языка эти проблемы можно в какой-то мере преодолеть, либо извлекая больше знаний из того, что ищут пользователи, либо генерируя в интерактивном режиме более внятные запросы, побуждающие потребителя сосредоточиться на своих интересах. Некоторые исследователи для построения пользовательских профилей применяют технологию обработки естественного языка (natural-language processing, NLP), но лишь в ограниченных областях, в случае привлечения WordNet или более простых ресурсов. Их усилия сосредоточены на проблемах доступа и обобщения концепций, решение которых позволит с упреждением отвечать на нужды пользователей [9].
К задачам NLG относятся [10]:
- определение содержания высказывания, влияющее как на макроуровень (определение содержания высказывания или реплики в диалоге), так и на микроуровень (определение содержания соответствующих ссылочных выражений);
- структурирование текста — идентификация наиболее подходящих структур для использования при конкретных обстоятельствах;
- внешняя реализация — отображение содержания предложения в морфологически и грамматически правильно построенные слова и предложения.
Конструкция системы NLG предполагает генерацию текста на естественном языке на уровне диалога [10], причем сложные задачи типа планирования беседы играют ключевую роль в синтезе эффективного текста. Эти усилия позволяют ввести теорию речевых актов в компьютерные системы, планирующие речевые последовательности [11]. Если обработка беседы включает в себя управление диалоговыми взаимодействиями с пользователем, системы NLG могут получать базовые сведения о коммуникативных шагах, чтобы синтезировать ответы в соответствии со знаниями и целями потребителя, реагировать на его ошибки или справляться с его неожиданной реакцией [12].
ПОИСК С ОБРАТНОЙ СВЯЗЬЮ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
Большинство подходов к поиску в Сети с использованием технологии NLP воплощены в виде систем, отвечающих на вопросы. Они используют лингвистическую обработку и дополнительные средства (такие как специальная разметка и устранение смысловой неоднозначности) для поиска документов, которые содержат абзацы с ответами на вопросы, сформулированные на естественном языке. Однако в них отсутствует диалог, а потому усилия сосредоточены на получении подходящих абзацев в пределах документа, а не на выявлении потребности пользователя. В некоторых случаях недостаточно совершенные лингвистические методы могут оказаться бесполезными, а поисковые запросы трудно сформулировать. Однако ориентация диалогов и запросов на определенные задачи и области применения поможет справиться с этими трудностями.
Наш подход к интеллектуальному поиску и фильтрации в Сети включает в себя технологию интеллектуальных агентов и методы NLP. Благодаря этому в адаптивном диалоге можно применять знание как контекста, так и интересов, целей и поведения пользователя. Основу модели интерактивной системы поиска составляют зависящие от задачи средства построения беседы и анализа диалога. Вместо предоставления образцов или обследования Сети для выявления нужной информации поиск на основе диалога позволяет сосредоточиться на требованиях пользователя путем изучения его конкретных интересов. Благодаря этому поисковая система может получать неявные знания и задействовать их для уточнения и фильтрации результатов поиска в ходе диалога. Такая система должна быть способна быстро определять нужды пользователя на основе предоставленной им информации и обратной связи при взаимодействии на естественном языке.
На рис. 2 проиллюстрирован общий подход к поиску и фильтрации с использованием обратной связи на естественном языке. Действие начинается с запроса на естественном языке, который формулируется пользователем. Запросы проходят обработку, при которой осуществляются диалоговые взаимодействия в форме высказываний на естественном языке, направленные на доработку и уточнение поискового запроса. В ходе диалога система уточняет запрос, а затем направляет его поисковому агенту.
Для разработки и проверки моделей диалога была выбрана экспериментальная технология Wizard of Oz [12]. Используя WoZ для сбора лингвистических данных, мы получили объемный свод диалогов. Мы записали его, проаннотировали и проанализировали, чтобы создать структурную модель, поддерживающую планирование и генерацию интерактивной объяснительной и описательной беседы [13]. Система моделирует человеко-машинное взаимодействие на естественном языке, причем интерактивный процесс продолжается до тех пор, пока модель не достигнет ожидаемых результатов.
Группа из 22 испытуемых-неспециалистов использовала имитатор WoZ для поиска информации в Web-пространстве. Ее разделили на четыре подгруппы: три были укомплектованы случайным образом, а четвертая состояла из аспирантов. Чтобы определить, возникают ли различия при проведении бесед (объяснения, описания и т.д.) в зависимости от текущей коммуникативной ситуации, нескольких «продвинутых» студентов попросили выполнить разные задания в одном и том же сеансе [13]. Взаимодействия пользователей с системой (точнее со скрытым экспертом, который играл ее роль) были записаны и послужили для лингвистического анализа. Процесс уточнения продолжался до полного удовлетворения потребностей пользователя (был установлен 20-минутный порог для проверки достижения пользователем коммуникативной цели). После поиска испытуемых просили описать, что именно они получили в результате поиска в Web. Это было сделано для создания компьютерной модели, которая применяет извлеченные из Сети документы для генерации описаний и объяснений на естественном языке.
Интерактивный генератор диалогов
Генератор диалогов на естественном языке состоит из нескольких компонентов, в том числе контекста, сведений об участниках (пользователь и система) и ситуации, к которой относится анализируемый диалог (например, взаимодействие для поиска информации в Web).
На рис. 3 предложенная модель NLG «ведет беседу» по результатам библиографического поиска в Web [14]. Процесс начинается с ввода пользователем запроса на естественном языке, продолжается в виде обмена сообщениями для его уточнения, а в заключительной фазе диалога создается поисковый запрос для передачи поисковому агенту.
Модель контекста имеет дело с информацией, которая касается участников диалога, — «пользователя», нуждающегося в информации из Сети, и «системы», выполняющей поиск. Модель определяет вид социальной ситуации («Библиографические запросы в Web») и цели участников: «Найти информацию по некоторой теме» (для пользователя) и «Помочь пользователю в достижении заявленной цели путем поиска и диалога» (для поисковой системы). Модель пользователя учитывает знания о нем.
Модель ситуации определяет характеристики коммуникативной ситуации, в которой происходит диалог. Поскольку данная модель допускает взаимодействие, беседы должны удовлетворять требованиям и ограничениям, определяемым ситуацией. Это подразумевает использование для представления модели как записей состояния диалога, так и структуры высказываний (лексической, синтаксической, семантической и прагматической).
Модуль взаимодействия на естественном языке базируется на максимах сотрудничества и включает в себя двухшаговые структуры обмена, такие как «вопрос—ответ», «приветствие—приветствие» и т.д. Эти структуры подчинены ограничениям, относящимся к взаимной способности передавать уместные и понятные сообщения как акты подтверждения. Поддерживается согласованность диалога между системой и пользователем и хранится вся информация, связанная с взаимодействиями в ходе диалога.
Анализатор диалога получает запрос пользователя и анализирует содержащуюся в нем информацию, чтобы определить условия, влияющие на генерацию ответа системы. Результатом работы этого модуля является запрос, который распознается и анализируется системой. Модули семантического и прагматического анализа, обрабатывающие лингвистическую составляющую, управляют распознаванием и интерпретацией.
Встроенный прагматический анализатор устанавливает вид речевого акта, соответствующего структурному компоненту диалога и удовлетворяющего установленным ограничениям и условиям. Анализатор использует информацию из модели ситуации и модели контекста. С учетом содержания, предлагаемого семантическим анализатором, и связности беседы, основанной на управлении взаимодействием, результатом работы анализатора является предварительно определенный речевой акт, который соответствует текущей коммуникативной цели.
Генератор диалога использует информацию, полученную от поискового агента, и состояние диалога, чтобы сгенерировать очередное высказывание в текущей диалоговой последовательности. Диалог начинается путем генерации весьма общего вопроса об информации, которая требуется пользователю. Затем система рассматривает два возможных продолжения: конкретный вопрос коммуникативной ситуации («Какова тема Вашего поиска?») или общий вопрос в контексте разных видов информации, доступной в Сети («Какая информация Вас интересует?»). Запросы пользователя могут быть разделены на четыре общие группы: запрос информации, положительный/отрицательный ответ, спецификация деталей и спецификация темы.
Анализатор диалога обрабатывает пользовательский ввод, чтобы получить информацию для поискового агента. В свою очередь, агент самостоятельно выполняет заданный поиск. Генератор естественного языка может использовать полученную информацию, например ссылки на документы, чтобы сгенерировать объяснения на естественном языке согласно основным критериям, идентифицированным в предварительных экспериментах.
Генератор диалога выдает предложения на естественном языке, основанные на результатах поиска, информации о контексте и обратной связи с пользователем. Для установления отправной точки процесса генерации высказываний на естественном языке были идентифицированы высокоуровневые цели. Однако процесс генерации полностью неструктурирован и имеет множество степеней свободы, поэтому должны быть приняты решения, направляющие генератор с прагматического уровня «вниз», к лексическому уровню.
На основе нескольких образцов, полученных в наших исследованиях процесса поиска в Сети, мы получили основные начальные критерии, которые регламентируют процесс генерации высказываний на естественном языке. Пусть R означает число ссылок, полученных поисковым агентом. Мы идентифицировали следующие случаи: R > 100 (запрос является слишком общим), 30 < R < 100 (рассматриваются другие проблемы, например документы созданы на разных языках), R < 30 (приемлемая величина для отображения результатов поиска).
Генератор диалогов на естественном языке может выдавать два вида ответов, поясняющих результаты поиска: направленный на уточнение вопроса пользователя («Ваш вопрос является слишком общим. Не могли бы Вы сформулировать его более определенно?») и содержащий предложение указать особенность исследуемой темы («Найдены ссылки на N документов по этой теме. Какой из них Вас больше всего интересует?»).
Анализатор диалога использует конкретный ответ пользователя, чтобы выполнить уточненный поиск. Поисковый агент решает задачу снова, отыскивая определенную информацию по теме поиска. Генератор диалога выдает три вида описательных высказываний, предоставляющих пользователю три варианта выбора: выбор языка; показ всех ссылок на документы, полученных при поиске в Web; показ результатов в соответствии с некоторым распространенным параметром.
Модуль генерации действий выполняет соответствующее действие поиска. Для поддержания согласованности диалога данный модуль получает информацию, обрабатываемую анализатором диалога, а модуль регистрации сохраняет ответ пользователя о выполнении этого действия. Анализатор диалога обрабатывает ответ пользователя, а генератор выдает запрос на подтверждение выполненного действия, например «Вы нашли то, что искали?». Чтобы проверить достижение коммуникативной цели, анализатор обрабатывает пользовательский ввод. Если он получает положительный ответ, система выдает предложение, позволяющее пользователю выбрать тему для нового поиска. В противном случае генератор предлагает поиск по другой теме, связанной с предыдущей, — начиная с прагматического уровня.
Процесс в целом начинается с установки главной цели, что позволяет создать законченную структуру на уровне предложения. В общем случае последующие цели разделены на соответствующие лингвистические функции: нацеленные на инициацию диалога, ответ на вопрос, вопрос о достижении цели беседы, запрос новой темы и т.д.
Адаптивный поисковый агент
В отличие от традиционных поисковых машин или информационно-поисковых систем разработанный нами поисковый агент не доставляет пользователю сразу всю информацию, полученную в результате поиска в Web. Сначала агент накапливает знания о реакции пользователя, целях и т.д., что положительно влияет на снижение уровня информационной перегрузки. В ходе взаимодействия агент уточняет запросы и фильтрует исходную информацию, полученную от пользователя в процессе поиска, пока не сможет отобрать разумное количество сведений.
Генератор естественного языка использует полученные агентом результаты, чтобы синтезировать адаптивные высказывания, соответствующие текущим ограничениям и состоянию беседы. В данном случае термин «критерии» означает основообразующее представление для документов и профиля пользователя. Они подобны критериям, используемым в информационно-поисковых системах, но дополнены специальными векторными функциями для поддержки необходимой выразительности.
Документы и запросы пользователя представлены в многомерном пространстве. После их обработки процессором естественного языка они преобразуются в шаблон, определяющий вектор критериев. Поисковый агент использует метрику расстояния и некоторые существующие машины, чтобы найти соответствующие документы.
На рис. 4 показана общая стратегия выбора следующего действия, основанная на уровнях уверенности. Фактически, генератор естественного языка преобразует эти действия в высокоуровневые прагматические ограничения, которые заставляют агента генерировать определенный вид диалога на естественном языке.
ОСНОВНЫЕ ВЫВОДЫ
Опытная система позволила сделать два главных вывода:
- беседа на естественном языке с автоматической системой в ходе поиска вполне возможна;
- такое взаимодействие уменьшает информационную перегрузку и, таким образом, время, которое пользователи тратят на поиск.
Для реализации дискурса генератор диалога использует структуру семантической сети, которая обеспечивает средства обслуживания естественного языка и формы представления знаний в виде семантической сети. Анализ результатов базировался на генерации 1 тыс. образцов структуры диалога, полученных от выполняемой системой задачи обработки дискурса (исходные диалоги велись по-испански).
Производительность системы была проанализирована с точки зрения фильтрации, чтобы оценить число коммуникативных шагов, необходимое для уточнения требований и получения отфильтрованной информации. Первоначально набор возможных документов включал в себя более 30 тыс. ссылок, но потом область поиска была сужена и составила менее 1 тыс. ссылок. Мы провели два эксперимента (рис. 5), в одном из которых искали информацию по тематике Java, а во втором — мультфильмы. Каждое взаимодействие состояло из одного или нескольких диалогов (обменов) между пользователем и системой.
Взаимодействия в диалоге по Java показали рост числа подходящих документов более чем за три обмена (рис. 5а). Это не случайно: и контекст, и вид вопросов изменяются в зависимости от ситуации и содержания документа. Схожие результаты были получены и во втором эксперименте (рис. 5б). Даже в диалогах с тремя обменами наблюдались внезапные приращения от одной до почти 35 ссылок. Это связано с тем, что агент пришел к определенным выводам, но пользователь наложил ограничение, связанное с характером документа.
Экспериментальная проверка влияния обратной связи с пользователем на способность поискового агента делать выводы показывает, что взвешенные функции поиска информации в зависимости от ее важности или полезности помогают сэкономить время. В любом случае взаимодействия (их форма и содержание) существенным образом зависят от этих факторов. Однако следует учитывать вклад пользователя в решения, принимаемые системой. Несмотря на умеренную сложность экспериментов и ограниченность времени их проведения, идентифицированные в нашем исследовании проблемы не должны радикально измениться при расширении требований к реализации (например, разные языки, возможности поиска и т.д.).
Использование модели диалогового взаимодействия кажется многообещающей стратегией. Она позволяет справиться с более специфическими требованиями к поиску информации, в которых проектирование и реализация системы NLG могут быть легко адаптированы к особым коммуникативным ситуациям. В отличие от других подходов, подразумевающих использование NLP для решения сходных проблем, наша модель идентифицирует интересы и цели потребителя в ходе интерактивного диалога. В иных подходах предпринимается попытка заранее установить критерии (вроде интересности и уместности). В некоторых моделях поиска с применением NLP рабочее предположение состоит в том, что при интеллектуальном поиске должен анализироваться профиль потребителя для сокращения пути к заключительному результату.
ЛИТЕРАТУРА
- В. Jansen, A. Spink. Real Life, Real Users, and Real Needs: A Study and Analysis of User Queries on the Web. Information Processing and Management. 2000, Vol. 36, no. 2.
- C. Holscher, G. Strube. Web Search Behavior of Internet Experts andNewbies. Proc. 9th Int?l World Wide Web Conf. Computer Networks, North-Holland Publishing, 2000.
- T. Lau, E. Horvitz. Patterns of Search: Analyzing and Modeling Web Query Refinement. Proc. 7th Int?l Conf. User Modeling, Springer, 1999.
- I. Zukerman et al, Trading Off Granularity against Complexity in Predictive Models for Complex Domains. Proc. 6th Int?l Pacific Rim Conf. Artificial Intelligence (PRICAI 2000). Springer-Verlag, 2000.
- A. Levy, D. Weld, Intelligent Internet Systems. Artificial Intelligence, 2000, Vol. 11, no. 8.
- P. Foltz, Using Latent Semantic Indexing for Information Filtering. Proc. Conf. Office Information Systems, ACM Press, 1990.
- G. Fischer, C. Stevens, Information Access in Complex, Poorly Structured Information Spaces. Proc. Human Factors in Computing Systems (CHI 91), Addison-Wesley, 1991.
- L. Tong, Changjie, Z. Jie, Web Document Filtering Technique Based on Natural Language Understanding. Int?l J. Computer Processing of Oriental Languages, 2001, Vol. 14, no. 3.
- E. Bloedorn, I. Mani. Using NLP for Machine Learning of User Profiles. Intelligent Data Analysis, 1998. Vol. 3, no. 2.
- E. Reiter, R. Dale. Building Natural Language Generation Systems. Cambridge University Press, 2000.
- P. Cohen, H. Levesque, Performatives in a Rationally Based Speech Act Theory, tech. note 486. SRI Int?l, 1990.
- D. Jurafsky, J. Martin, An Introduction to Natural Language Processing. Computational Linguistics and Speech Recognition. Prentice Hall, 2000.
- J. Moore, Participating in Explanatory Dialogues: Interpreting and Responding to Questions in Context. MIT Press, 1994.
- A. Ferreira, Generating Descriptive and Explanatory Discourse Based on a Computational Linguistics Model (in Spanish), doctoral dissertation. Catholic Univ. of Valparaiso, Chile, 1998.
Анита Феррейра (aferreir@udec.cl) — доцент факультета лингвистики, а Джон Аткинсон (atkinson@inf.udec.cl) — доцент факультета информатики в университете Universidad de Concepcion (Чили).
Anita Ferreira, John Atkinson, Intelligent Search Agents Using Web-Driven Natural-Language Explanatory Dialogs, IEEE Computer, October 2005. IEEE Computer Society, 2005, All rights reserved. Reprinted with permission.
