Полноценно перевести словосочетание Business Intelligence (BI) невозможно. Со словом business и без того в русском языке есть очевидные сложности; не меньшие проблемы возникают при попытке подобрать соответствие слову intelligence в данном контексте. В период кризиса, охватившего практически все компьютерные технологии, область BI оказалась одним из немногих островов процветания в нынешнем далеком от благополучия мире. Более того, аналитики Gartner Group считают, что в области BI предстоят настоящие прорывы. Серьезные перспективы они связывают с новым направлением — New Business Intelligence (NBI).
Компания Intelliseek стала одной из первых, кто проложил мост между KM и BI, назвав свой подход New Business Intelligence. Стимулами к появлению NBI, как сказал Каджам [4], стали рост размещенных в Internet данных и эволюция технологий для агрегирования, анализа и подготовки отчетов на основании разнородных источников.
В словарях приведены десятки соответствующих ему значений; некоторые из них, на первый взгляд, кажутся далекими друг от друга. А уж в сочетании business и intelligence дают нечто невообразимое. Разбираться в фундаментальных различиях между русским и английским языками, являющихся причинами такого рода сложностей, — удел лингвистов, точнее социолингвистов. Поэтому прекратим терминологические рассуждения, и будем в дальнейшем понимать под BI — информационное обеспечение бизнеса, причем в самом широком смысле. Не забудем, впрочем, две прописные истины. Первая: «Бизнес — это война». Вторая: «Информирован — значит вооружен». Другими словами, BI — это и интеллект, и разведка, в общем, все то, что нужно для приятия решений. Любопытно еще одно обстоятельство. В период кризиса, охватившего практически все компьютерные технологии, область BI оказалась одним из немногих островов процветания в нынешнем далеком от благополучия мире [1]. Более того, пришедшие к такому выводу аналитики Gartner Group считают, что в области BI предстоят настоящие прорывы. Серьезные перспективы они связывают с новым направлением — New Business Intelligence (NBI).
Данные, информация и технологии
Еще совсем недавно шутники предрекали, что конец развитию ИТ-решений наступит тогда, когда будут исчерпаны все возможные трехбуквенные названия. Впрочем, по понятным причинам прогресс не остановился: появились четырех и более буквенные аббревиатуры. Но, как известно, «в каждой шутке есть только доля шутки». Действительно, количество названий и соответственно разнообразных технологий для работы с информацией, а точнее говоря с данными, превосходит все мыслимые пределы. Если рост числа собственно технологий (а не их названий) продолжится, то конец и в самом деле возможен — прежде всего, по причине сложности. Технологий действительно море, но стройной карты для них, своего рода новой таблицы Менделеева, где каждой технологии было бы отведено свое место, и были бы обозначены связи между ними, пока нет. И отнюдь не случайно: причина в недостаточной определенности предмета, с которым работают технологии, называемые информационными. Эта неопределенность выражается, прежде всего, в смешении двух ключевых понятий — данные и информация.
Надо признать, что отдельные фрагменты будущей систематизирующей таблицы все таки складываются, причем, как это ни странно, раньше других не в областях, ставших классическими, а в совершенно новой области, такой как интеграция приложений на основе Web-служб. Еще совсем недавно, буквально пару лет назад Web-службы называли плохо определенной областью (ill-defined) компьютинга. Но неожиданно прозрачность в этой сфере наступает раньше, чем в других.
Происходит это, скорее всего, потому, что в данном случае решается задача обмена данными между приложениями. Подчеркнем: обмен ДАННЫМИ между ПРИЛОЖЕНИЯМИ. В этом фрагменте цепочки технологий нет человека, что в каком-то смысле приближает корпоративные системы к техническим системам управления или коммуникационным системам. Основной пафос происходящего в области с совпадающей аббревиатурой BI, (в данном случае обозначающей Business Integration) сводится к тому, что логика бизнес-процессов новыми средствами (прежде всего, серверами приложений) отделяется от логики процессов обработки данных — другими словами, «мухи отдельно, варенье отдельно». Таким образом, в инфраструктуре корпоративной системы в явном виде оформляются коммуникационные качества. Приложения ведут между собой обмен данными посредством сообщений примерно так же, как в технических системах данные передаются от датчиков (обратите внимание на однокоренные слова: «датчик» и «данные»). Система становится в большей степени инфраструктурой для передачи данных (т.е. инфраструктурой в подлинном смысле этого слова), а поверх нее работают приложения, предоставляющие доступ к источникам информации. На смену компьютингу идет коММпьютинг («коммуникации + компьютеры»).
Итак, если отбросить детали, нужно подчеркнуть, что современные технологии интеграции на основе стандартов SOAP, UDDI, WDSL и других позволяют сепарировать данные и информацию. Соответственно можно разделить и сами технологии — на те, которые работают в чистом виде с данными, и те, которые обеспечивают работу с информацией.
С появлением J2ЕЕ был сделан первый существенный шаг и теперь силами Sun Microsystems, тройственного союза BEA Systems, Intel, HP, корпорации IBM, а также целого ряда других заинтересованных сторон формируются платформы для обмена данными, между приложениями, образующими корпоративную систему. Но создание платформы для взаимодействия приложений не решает главной задачи — обеспечение ЧЕЛОВЕКА, также являющегося частью системы, средствами для получения ИНФОРМАЦИИИ (ведь, в конечном счете, для принятия решений нужна именно информация). Задачу создания средств для выделения информации из данных, лежащую поверх платформы, решают многие, в том числе и крупные, но по большей части мелкие компании. Они выступают в роли сателлитов, сопровождающих ведущих вендоров; особенно роль свиты бывает хорошо видна на всевозможных выставках, устраиваемых в рамках конференций, которые организуют крупные компании.
У задачи обеспечения человека возможностью работы с информацией есть две стороны. Одна в большей степени техническая; ее можно сравнить с полиграфическими услугами. С технической точки зрения на первый план выходят портальные технологии. Корпоративный портал играет роль интерфейсного устройства; его можно воспринимать как инструмент, посредством которого данные представляются в форме, доступной для превращения их человеком в информацию. Традиционные определения порталов (например: «единственная точка персонализированного доступа к источникам бизнес-информации и знания», Delphi Group [2]) выглядят наивно. Что такое источник в данном случае? Более корректное введение в портальные технологии можно найти в [3]. Определению портала в этом документе предшествует определение того, что авторы понимают под KM (knowledge management) и BI, поскольку посредством этих технологий человек реально получает доступ к данным. Подчеркивается, что управление знаниями и информационное обеспечение бизнеса поддерживаются различными технологиями, в том числе и порталами.
Информационные системы для управляющих (executive information system, EIS), системы поддержки принятия решений (decision support), раскопка текстов и данных (text mining и data mining), операционные хранилища данных (operational data store), многомерная аналитическая обработка данных (multidimensional online analytical processing, MOLAP), реляционная аналитическая обработка данных (relational online analytical processing, ROLAP), а теперь еще и business intelligence — все эти и им подобные многочисленные термины могут лишь ввести в заблуждение любого. На самом же деле главный смысл тех глобальных изменений, которые происходят сегодня, заключается в том, что сейчас, прежде всего, требуется выбирать ДАННЫЕ из традиционных приложений и превращать их в ИНФОРМАЦИЮ, в информацию, которая может быть использована для эффективного управления бизнесом. На основе такого подхода дается следующее определение портала: «Портал — это единая точка входа в корпоративной системе, которая позволяет обнаруживать и высвобождать (identify и unlock) структурированную и неструктурированную информацию из различных источников с тем, чтобы превратить ее в корпоративное знание, необходимое для принятия решений».
В число приложений, которые обеспечивают превращение данных в информацию входят перечисленные выше и еще многие другие, все вместе это и можно назвать информационным обеспечением бизнеса — или BI.
 |
| Рис. 1. Происхождение Business Intelligence |
BI по-новому
Неспособность специалистов по компьютингу с достаточной точностью определить предмет своей деятельности привела к тому, что появился монстр, многоголовая гидра «информационных технологий», каждая из которых по большей части занимается чем угодно, но только не работой с информацией. В России еще хуже, у нас есть наука информатика, ее происхождение — предмет отдельного разговора.
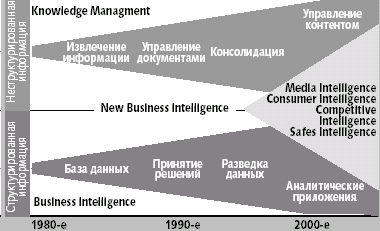
По существу, 99% средств ИТ работают с данными. Именно информацией, а не данными занимались очень немногие. Среди них те, кто работал в областях Business Intelligence и Knowledge Management; долгое время это были две близкие, но совершенно не пересекающиеся между собой области. Если продолжить сравнение с геофизикой и геологией, то методы BI можно уподобить геофизическим методам (не случайна схожесть названий, например data mining и text mining). Вторая область, KM и особенно ее прикладная часть, управление контентом предприятия (Enterprise Content Management), ближе к геологии. Аналогия между BI и науками о Земле состоит в том, что прежде по формальным признакам, на основе анализа данных выявляются внутренние закономерности, а потом им даются интерпретации с привлечением более широкого круга знаний.
Теперь можно ответить на вопрос, почему на фоне общего спада процветает BI. Чем сильнее аналитика, тем эффективнее использование данных. И в науках о Земле, и в бизнесе аналитика обходится на порядки дешевле накопления данных. Поэтому в условиях кризиса взоры специалистов и обратились в сторону BI: бизнес стремится повысить эффективность, уровень возврата инвестиций в систему с минимальными дополнительными вложениями. Именно в этом ключ в понимании причин феномена локального успеха BI на фоне спада в остальных технологических направления. В условиях кризиса всегда оказываются более востребованными продукты с меньшим сроком возврата инвестиций, в данном случае — средства работы с информацией. Возросший спрос на средства BI вызывает и новое предложение, получившее название New Business Intelligence (NBI). Данное направление сложилось в результате партнерства компаний Inxight Software и Intelliseek, известных в качестве поставщиков решений для доступа к неструктурированным данным. Это две похожие небольшие, насчитывающие порядка сотни сотрудников, наукоемкие компании, но с разными корнями.
Inxight была основана в 1996 году корпорацией Xerox в рамках инициативы Xerox New Enterprises с целью дальнейшего развития технологий, созданных в исследовательских центрах Xerox Palo Alto Research Center (PARC) и Xerox Research Center Europe. Лучше родословную придумать сложно. В комплекс решаемых в Inxight проблем входят задачи работы с неструктурированными данными. Важность этого типа задач определяется тем, что свыше 85% корпоративных данных хранятся не в СУБД, а текстовых документах и файлах, Web-страницах, электронных письмах и аналогичных документах. Но поле это еще не пахано. По данным аналитиков IDC, большинство компаний не имеют адекватных средств для поиска и анализа информации в таких источниках.
Компания Intelliseek была создана Махендрой Вора и Сандаром Каджамом, которые стали соответственно ее генеральным директором и директором по технологиям. Основной программный продукт компании нацелен на выборку данных из разнообразных динамических источников и поиск данных в ресурсах разных типов. В Intelliseek вложили свои средства крупные промышленные компании, такие как Ford, Procter&Gamble и другие. Сведения еще об одном из источников финансирования Intelliseek, склоняющем к интерпретации термина Intelligence как разведка, можно найти во врезке «Защита информации vs. Информационная безопасность». В качестве примера ее практической деятельности можно назвать «анализ состояния брэндов» (brand pulse). Крупные компании с мировыми именами должны постоянно отслеживать состояние своего имени на рынке; в последние годы предназначенное для этой цели программное обеспечение активно развивается.
Появление NBI символизирует начало эпохи конвергенции двух направлений, которые до сих пор существовали независимо. Динамика этого процесса показана на рис. 1. Классическое направление BI основывается на более традиционных для бизнеса инструментах, предназначенных для обнаружения информации в хорошо организованных и структурированных данных. За два десятилетия своего существования BI оформилось как направление, где есть известные технические и алгоритмические принципы, существует сообщество специалистов. Важно и то, что сложились подходы, позволяющие оценить рациональность инвестиций (return on investment, ROI). В то же время управление знаниями до сих пор остается аморфной областью, с довольно большой прослойкой специалистов, как у нас, так и за рубежом, имеющих спекулятивную ориентацию в своей «проповеднической» активности. Методы KM простираются от организационных мероприятий до полнотекстового поиска и фильтрации данных, представленных на естественных языках. При том, что многим специалистам на интуитивном уровне понятна необходимость использования технологий KM, практических инструментов, имеющих экономическую оценку, пока не было.
Компания Intelliseek стала одной из первых, кто проложил мост между KM и BI, назвав свой подход New Business Intelligence. Стимулами к появлению NBI, как сказал Каджам [4], стали рост размещенных в Internet данных и эволюция технологий для агрегирования, анализа и подготовки отчетов на основании разнородных источников. Традиционные методы BI, предлагаемые компаниями Business Objects, MicroStrategy, Cognos, Informatica, Oracle, Microsoft и другими позволяют использовать не более 20% от общего количества доступных данных. Хороший обзор можно найти в [5]. C использованием NBI эта доля может быть увеличена от 50 до 60% за счет использования таких документов, как документация на изделия, исследовательские отчеты, записи о работниках. Сандар Каджам утверждает, что использование качественно иных, нежели СУБД, источников данных, позволяет существенно расширить кругозор и перейти от обработки статистики к выявлению тенденций. Свое видение проблем конвергенции KM и BI, а также их решение, в Intelliseek воплотили в двух программных продуктах — Enterprise Search Server (ESS) и BrandPulse.
Сильная сторона подхода, на котором построена идеология работы с данными предприятиями, которую предлагает Intelliseek, принципиально отличающая его от других известных, состоит в том, что в качестве исходной точки выбрано объединение KM и BI. Если отбросить маркетинговую шелуху, то легко обнаружить, что за этим лозунгом скрывается систематическое отношение к данным. На рис. 2 представлена схема, вполне справедливо названная «Информационным ландшафтом» (information landscape), где общая картина данных представлена во всей своей полноте. Несмотря на очевидность, она оригинальна — подобного обобщения всех разнородных источников данных прежде видеть не удавалось. В информационном ландшафте, предложенном Intelliseek, все потенциальные источники данных разделены на две основные группы: собственные данные предприятия и данные, источником которых является Internet. Далее корпоративные данные делятся на структурированные и неструктурированные. К структурированным данным относятся те, которыми чаще всего оперируют в информационных системах, их собирают и обрабатывают в рамках приложений категорий EID (enterprise information data), CRM (customer relationship management), SCM (supply chain management), ERP (enterprise recourse planning) и др. Эти данные хранятся в базах данных, они подвергаются оперативной аналитической обработке (online analytical processing, OLTP), сохраняются и архивируются в хранилищах данных для того, чтобы можно было в дальнейшем выполнять аналитическую обработку средствами BI и DSS и получать в итоге проанализированные данные, отчеты и выполнять дальнейшую раскопку данных. К неструктурированным данным относятся зафиксированные результаты взаимодействия (collaboration), потоков работ (workflow), управления документооборотом и другие авторские материалы. Они существуют в виде электронных писем, контрактов и предложений, аудио- и видеофайлов, руководств, чертежей, маркетинговых материалов, описаний продуктов. Эти данные по совокупности образуют внутреннее знание организации.
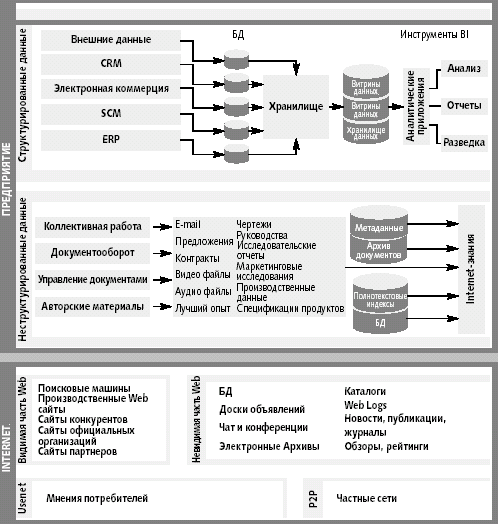
Рис. 2. Информационный ландшафт
Данные из Internet можно разделить на четыре подмножества. Основную их часть составляют данные из видимой и невидимой частей Web. В видимой части находится все то, что можно найти поисковыми машинами, т. е. собственно поисковые машины и сайты партнеров, конкурентов, государственные и т.д. Состав невидимой части Web шире, там находятся базы данных, чаты и доски объявлений, «веблоги», подписные журналы, обзоры и т.д. Меньшую часть представляют собственные сети Usenet и peer-to-peer (P2P).
Сведение вместе структурированных и неструктурированных данных — первый и наиважнейший шаг к объединению KM и BI. После того как создана объединенная картина информационного пространства, возникает естественный вопрос, как ею пользоваться? Очевидно, что точка входа должна быть построена на основе портальных технологий. На начальном этапе количество различных корпоративных порталов в пределах даже одного предприятия измерялось десятками. Сейчас наблюдается процесс консолидации порталов; например, совсем недавно компания Sun Microsystems сообщила, что количество используемых в ней порталов сокращено с 56 до 2. На самом деле нужна единственная точка входа ко всем виртуализированным корпоративным данным.
Пока реально ничего другого для доступа к данным кроме поисковых машин не существует. Массовое использование Сети наглядно это доказало. Решение этой задачи предложено Intelliseek в форме «корпоративной поисковой структуры» (Enterprise Search Framework, ESF) и «корпоративного поискового сервера» (Enterprise Search Server, ESS). Совместно они образуют информационную систему, которая имеет фирменное название — «настоящий корпоративный поиск» (True Enterprise Search).
ESF представляет собой многоуровневую систему.
Нижний уровень — интегрированный поиск (Federated Search, FS), иногда называемый также распределенным, обеспечивает поиск по разным источникам данных и упорядочивание полученных результатов. Работу FS поддерживают четыре типа технологий:
- Brokering - передача запросов в поисковые машины и получение результатов;
- Bridging - установление связей с базами данных;
- Full-Text Indexing - полнотекстовая индексация;
- Catalog Building - создание каталогов для полуструктурированного и неструктурированного контента.
Следующие уровни FS:
- адаптивное обучение (Adaptive Learning), реализующее настройку маршрутизации запросов по содержанию запросов и типам источников данных;
- анализ результатов (Result Analysis) обеспечивает фильтрацию и отсеивания ошибочных, несоответствующих запросам результатов;
- отслеживание и установка контрольных точек (Tracking & Alerts)дает пользователю возможность самому корректировать процедуры поиска;
- упорядочивание (Categorization) - средство для организации полученных результатов;
- публикация знаний (Knowledge Publishing)- фиксация результатов работы пользователей;
- моделирование интересов пользователя (User Interest Modeling);
- адаптивная персонализация (Adaptive Personalization);
- представление (Presentation), технология построена на стандартных методах XML/XSLT;
- портальные адаптеры (EIP/Portal Adapters);
- администрирование.
Компания Intelliseek в настоящее время предлагает три программных продукта:
- Enterprise Search Server (ESS) - основной продукт, обеспечивающий настоящий корпоративный поиск" и управление корпоративными знаниями;
- BrandPulse - продукт, построенный на платформе ESS и служащий для анализа состояния торговой марки;
- ExpressFeedback - новое предложение Intelliseek, служащее в качестве средства обратной связи для анализа отношений с покупателями.
NBI вполне можно рассматривать как одно из первых проявлений наметившегося процесса разделения корпоративных систем на два взаимодополняющих компонента: платформа, выполняющая все функции работы с данными, и надстройка, обеспечивающая перевод этих данных в информацию, воспринимаемую человеком.
Литература
- Kevin Strange, Business Intelligence in 2003: Year of the "Shake-Up". Gartner Group, 2002, December.
- Business Portals: A Definition, TRIP REPORT Delphi Group Portals Seminar. The Fairmont, San Francisco, 2002, February 12-13.
- Oracle9i Application Server Portal Handbook, Overview of Enterprise Information Portals.
- Sundar Kadayam, The Promise of Knowledge Management, the ROI of Business Intelligence. KMWorld, 2002, January.
- Jennings, Defining The Document and Content Management Ecosystem. Butler Group, September 2002.
- Leveraging Knowledge From the Extended Enterprise, Intelliseek.
Данные vs. Информация
В компьютинге до сих пор нет точного определения того, что такое данные, что такое информация и чем данные отличаются от информации. Более пятидесяти лет назад с легкой руки Клода Шеннона и Джона фон Неймана, которым нужно было придать больше наукообразия теории передачи сигналов, была введена теория информации. С тех пор словом «информация» пользуются совершенно произвольно, не проводя разделение на данные и информацию, хотя это явно не одно и тоже. Даже не углубляясь в суть, доказать это совсем просто. Возьмем две книги формально равные по объему, содержащихся в них данных (т.е. с равным числом знаков); пусть одна будет доброкачественным детективом, а вторая — серьезным литературным произведением. Сравним повествования Бориса Акунина, исключая триптих о Пелагие, и «Мастера и Маргариту» Михаила Булгакова. (Это вовсе не критика, Акунина следует признать мастером своего жанра — дело в жанре, как таковом.) Детективы читаются легко, а процесс чтения очень похож на перекачку данных, он может идти непрерывно, поскольку в процессе чтения совсем не нужно привлекать дополнительную информацию и вызывать воображение. За читателя все сделано, в этом особая прелесть детектива. К тому же процесс конечен — трудно представить себе читателя, за исключением группы преданных фанатов, который со временем возвратится к прочитанному и будет вдумчиво перечитывать приключения Эрнеста Фандорина — достаточно один раз перекачать данные. Но едва ли найдется такой читатель, который, прочитав первый раз «Мастера», сочтет, что все понял и не захочет вернуться к нему. У любого возникает естественное желание прочитать по отдельности каждую из сюжетных линий, эпизоды и т.п. Читающий может понять это произведение в меру своей подготовленности, в отличие от детектива оно не является самодостаточным для понимания.
У литературоведов, кажется, есть такое понятие «материал», при формально равенстве по числу знаков произведения различаются материалом, в одном его мало, в другом больше. Иногда его так много, что понять произведение до последней точки невозможно, кто скажет, что он до конца понимает «Имя Розы» Умберто Эко или «Хазарский словарь» Панича. Или другой пример: японское трехстишие содержит вообще считанное число знаков, а как оно богато информационно, эмоционально и т.д.
Итак, информация — это то, что открывается при взаимодействии человека с данными с привлечением знания, которым он обладает. Запись на незнакомом языке — просто данные, а на известном — информация. Полиграфия на протяжении всей своей истории стремилась облегчить процесс превращения данных в информацию, поэтому разрабатывались шрифты, книги иллюстрировались, снабжались оглавлениями и т.д. Поэтому книга в примитивном издании уступает хорошо оформленному и иллюстрированному изданию. Собственно, иллюстрации и появились, чтобы помочь понять и интерпретировать данные. Современные корпоративные порталы — это аналоги книг, они служат интерфейсом между данными и человеком, но им до культуры книгоиздания еще далеко.
Еще один промер корректного соотношения между данными и информацией можно обнаружить в обработке результатов геофизической разведки. Здесь не приходится гадать, что является данными, что информацией, а что знанием. Для наглядности упростим реальный процесс, начинающийся с получения первичных данных и завершающийся созданием отчетов и карт расположения ресурсов. Вначале теми или иными геофизическими методами (сейсмика, аэрогеофизика, дистанционное зондирование и т.д.) набираются самые разнообразные данные (поля распределения различных элементов, электропроводность, сейсмические данные, изменение ускорения свободного падения и т.д.). Эти данные так и называют — «сейсмика, электроразведка, гравика», подчеркивая тем самым их принадлежность к способу получения; никому и в голову не придет назвать их информацией. Затем данные проходят первичную обработку, в которой участвует эксперт-геофизик, интерпретирующий эти данные, его инструментами являются самые разнообразные системы и средства для трансформации этих данных, в том числе экспертные системы, средства визуализации и многое другое, но главное — его знания геофизики. На выходе он передает геологам, осмысленную им геофизическую ИНФОРМАЦИОННУЮ картину исследуемой площади. Следующий за ним эксперт-геолог дает полученной информации свою интерпретацию, основанную на геологическом знании и, могут быть использованы дополнительные методы исследования. На каждом этапе данные обогащаются экспертизой, из данных формируется осмысливаемая информация, а в конечном итоге знание. Таким образом, в геофизике успешно реализована мучающая многих ИТ-специалистов триада «Данные — Информация - Знание»; здесь все произошло просто и вполне естественным путем, без использования каких-либо не слишком понятных терминов и технологий.
Защита информации vs. информационная безопасность
Разделение представления об информации и данных критически важно и в такой, казалось бы, неожиданной области, которую обобщенно называют информационной безопасностью. Его отсутствие в явном виде приводит к явной путанице части технических, аналитических и организационных мер в этой сфере. Совсем недавно понимание смыслового различия между данными и информацией стало осознаваться и специалистами, работающим в области безопасности. На первых порах (пока, в основном, в академической среде) начинают говорить о двух связанных направлениях. Первое — это собственно классическая защита данных в ее традиционном понимании (Information System Security Data). Второе исследует информационные принципы безопасности информационных систем (Information Principles of Information System Security). Защита данных техническими средствами по существу ближе к обеспечению физической безопасности, а защита информации в информационных системах гораздо более широкое понятие и оно не сводится к тривиальному закрытию источников информации от посторонних. Хорошо известно, основную часть сведений разведывательные службы получают из открытых источников с применением аналитических инструментов. Прекрасная иллюстрация того, как самые охраняемые секреты могут быть вскрыты посредством анализа публикаций в прессе, приведена в старом фильме «Три дня Кондора» с Робертом Редфордом в главной роли. В нашей стране недавно получило громкую огласку дело по обвинению в шпионаже одного ученого из Обнинска. В банальном смысле он не разведчик, хотя, возможно, и предатель, хотя занимался всего-навсего аналитикой открытых публикаций, однако столь эффективно, что вызвал заметную обеспокоенность спецслужб своими действиями. Далеко не случайно, что вопросами анализа открытых источников давно и серьезно занимается все спецслужбы. В условиях глобализации и развития электронных средств распространения данных задачи анализа приобрели особое значение.
По понятным причинам становится доступным больше сведений о деятельности Центрального разведывательного управления США, чем о географически более близких их коллегах. Сегодня деятельность ЦРУ по защите информации приобретает в определенной степени коммерческий характер, по этой причине в 1999 году было организовано «полуоткрытое» подразделение ЦРУ, названное In-Q-Tel. Своеобразный венчурный специалист от разведки в лице In-Q-Tel был для привлечения частных компаний к разработке технологий для сбора и анализа информации. Такой шаг сделан, по-видимому, для привлечения новых идей. Задачи, стоящие перед этой организацией, сформулированы следующим образом: «In-Q-Tel проявляет особую заинтересованность к новейшим технологиям извлечения ЗНАНИЙ из различных репозиториев и потоков данных, включая структурированные и неструктурированные ДАННЫЕ и представления релевантной ИНФОРМАЦИИ». В этой не слишком афишируемой программе ЦРУ выступает в роли инвестора в компании-«стартапы» и специальные программы. Первым начинанием стала поддержка компании Systems Research & Development, где методы анализа, разработанные для казино, перерабатывались в разведывательных целях. Отнюдь не случайно, что штаб-квартира SRD находится в Лас-Вегасе, очень нетипичном месте для софтверных компаний. Всего под патронажем In-Q-Tel находится менее десятка компаний.
Показательно, что одной из компаний, куда вложены средства In-Q-Tel, оказалась Intelliseek, разрабатывающая интеллектуальные Web-агенты и технологии вскрытия знаний. Вот что сказано по этому поводу на сайте In-Q-Tel: «За последние четыре года Intelliseek смогла изменить представления о том, что такое корпоративный интеллект, решения в области управления знаниями, поиска и открытия позволили решить фундаментальную проблему информационной перегрузки путем идентификации, релевантного поиска, постановки целей и создания персонализированного контента из Internet, и из сетей intranet и extranet».
Что такое Невидимая Паутина
Видимая часть Глобальной паутины (Visible Web) доступна через обычные поисковые машины, невидимая часть, очевидно, — это все остальное. Надо учесть, что распределение между частями меняется (раньше к числу невидимых относились файлы в формате pdf), но все же невидимым остается объем данных, который на порядок больше того, что можно увидеть простыми средствами. Это, прежде всего, — базы данных, допускающие доступ для поиска. В этих базах данных нет готовых страниц, которые предъявляются посредством браузера. Гораздо эффективнее и экономичнее оказывается формировать ответы в динамическом режиме, он обеспечивает возможность формирование страницы соответствующей конкретному запросу, естественно, что формируемую страницу ни один браузер найти не может. Вторая часть — исключенные страницы. Любая поисковая машина имеет определенную политику выбора индексируемых страниц. Если она обнаруживает, что по каким-то определенным признакам включение страницы в базу поисковой машины данных нецелесообразно, она ее исключает.
