Одним из примеров проектов объединения всех простаивающих компьютеров служит экспериментальная программа SETIhome, объединяющая около 2 млн. пользователей компьютеров, предоставивших свои системы для решения крупных задач типа моделирования структуры вируса рака или расшифровки генома человека. Только за первые месяцы своего существования в рамках программы SETIhome удалось суммарно получить терафлопную производительность. Правда, несмотря на успех этой программы, существует скепсис по поводу практической применимости распределенной вычислительной модели в бизнесе. Тем не менее, имеется множество организаций и компаний, которым требуются суперкомпьютерные мощности, но которые не имеют средств на их приобретение. Например, ряду банков требуется проводить комплексный финансовый анализ, а компаниям, работающим на индустрию развлечения необходимо выполнять интенсивные графические вычисления для создания фильмов.
Другой пример успешного применения сообщества временно простаивающих компьютеров продемонстрировал национальный вычислительный альянс, объединяющий партнеров университета шт. Айова и Арагонской Национальной лаборатории. В рамках структуры PACI (Advanced Computational Infrastructure) удалось решить проблему «nug30» из группы задач QAP (quadratic assignment problem) типа известной проблемы коммивояжера, возникшей еще в 1968 году при решении задачи тестирования в прикладной теории размещений. Имеется множество точек куда должно быть доставлено какое-либо воздействие и требуется определить стоимость передачи этих воздействий для каждой пары точек. Поток воздействий между каждой парой умножается на расстояние между точками и так для всех пар. В задаче «nug30» имеется 30 воздействий, каждое из которых должно быть доставлено в 30 фиксированных точек. Требуется минимизировать стоимость передачи воздействий между точками, иначе говоря, найти оптимальный маршрут. Задача имеет массу практических применений от планирования сети госпиталей или заводов до проектирования микропроцессоров. Однако несмотря на простоту постановки ее оптимальное решение весьма нетривиально.
В рамках проекта PACI над решением задачи «nug30» работало в среднем 650 процессоров (в пиковые периоды их число составляло 1009), установленных на компьютерах пяти различных платформ, физически расположенных в восьми разных местах по всему миру (несколько штатов США плюс компьютерный центр в Италии). Счет шел в течение семи дней, что составило 96 тыс. часов процессорного времени. Без использования метакомпьютера процесс решения затянулся бы на многие годы. Инструментальным средством, позволившим выполнить такой огромный объем работ был тандем из системы Condor и Globus [1].
Основные возможности Condor
Кластерная система Condor была создана группой разработчиков Университета Wisconsin-Madison где и была более 10 лет назад развернута первая конфигурация. На сегодняшний день в университете имеется 350 настольных UNIX станций, которые включены в сеть Condor и предоставляют доступ для работы пользователям со всего мира. Система свободно распространяется в загрузочных модулях для следующих платформ:
- HP PA-RISC (PA7000 и PA8000) HPUX 10.20;
- Sun SPARC Sun4m,c, Sun UltraSPARC Solaris 2.5.x, 2.6, Solaris 2.7 («с ограничениями»);
- Silicon Graphics MIPS (R4400, R4600, R8000, R10000) IRIX 6.2, 6.3, 6.4, 6.5;
- Intel x86, Pentium Linux 2.0.x, 2.2.x, glibc20, glibc21, libc5, Solaris 2.5.x, 2.6, Windows NT 4.0 («с ограничениями»);
- Digital ALPHA OSF/1 (Digital Unix) 4.x, Linux 2.0.x, Linux 2.2.x («с ограничениями»).
Для некоторых платформ Condor имеет ограничения - не поддерживает контрольные точки (checkpoint) и удаленные системные вызовы (работа только в режиме «Vanilla»).
Во многих случаях, особенно если речь идет о расчетных задачах, пользователям намного важнее не быстрота выполнения одного задания, а число заданий, которые можно выполнить за достаточно продолжительное время. Иначе говоря, число операций в месяц или год. Такой постулат лежит в основе технологии эффективного использования имеющихся компьютерных ресурсов - High Throughput Computing (HTC). Система Condor - это ПО для поддержки среды HTC, образованной станциями на платформе UNIX и NT. Несмотря на то, что Condor может управлять специализированными кластерами из рабочих станций, его ключевое преимущество - способность распределять обычные компьютерные ресурсы, доступные в любой лаборатории или офисе. Иногда еще Condor называют «охотник за свободными станциями» - вместо того чтобы запускать задания на своей машине, пользователь обращается к системе, которая ищет временно свободные машины в сети и запускает на них задания. Когда машина перестанет быть свободной (вернувшийся с обеда пользователь нажал клавишу или кнопку мыши, либо машина получила команду выгрузки ОС), Condor прерывает выполнение заданий, осуществляет миграцию на другую свободную машину и перезапускает задание на ней с прерванного места. Если нет свободных машин, то задание помещается в очередь и ждет свободных ресурсов. Предусмотренный в Condor механизм управления заданиями, предполагает ведение очередей, составление расписаний, схему приоритетов и классификацию ресурсов позволяет пользователю быть в курсе дел о состоянии своих заданий, не заботясь об их дальнейшей судьбе.
Предложенная в Condor дисциплина работы ориентирована на выполнение продолжительных заданий, время счета которых исчисляется часами. Например, если необходимо 5 часов счета, то задание может начать работу на машине «A» и после 3 часов мигрировать на машину «B» где, через два часа задание завершится, о чем пользователь будет оповещен. Возможно и более глубокое деление общего времени выполнения, например на 250 различных квантов. При этом Condor не требует включения машин в состав сетевых файловых систем, таких как NFS или AFS, а все станции могут размещаться на разных доменах. Кроме обычного режима обработки контрольных точек с запоминанием состояния Condor может периодически сохранять текущее состояние, что особенно полезно для обеспечения надежности работы в случае сбоя компьютеров из пула или страховки от более прозаических вещей типа непроизвольного выключения станции без операции «shutdown».
Кроме выполнения миграции на свободные машины Condor обеспечивает управление распределенными ресурсами. В отличие от других систем СУПО, в которых администратору или пользователю требуется вручную редактировать реквизиты задания в очереди, чтобы удовлетворить требованиям выполняющего компьютера и протолкнуть задание на счет, Condor полностью автоматизирует процесс распределения заданий, используя для этого объектную технологию ClassAds. Данная технология работает подобно газетному рекламному классификатору. Все машины, доступные пулу Condor объявляют (рекламируют) свои возможности в рубрике «Предложение»: объем памяти на диске, тип и быстродействие процессора, объем виртуальной памяти, средняя загрузка и т.п. С другой стороны, пользователь описывает потребности своего задания в рубрике «Запрос ресурсов». Condor работает в роли брокера, удовлетворяющего заявки из рубрики «Запрос ресурсов» ресурсами, представленными в рубрике «Предложение». Одновременно система обеспечивает ведение дисциплины нескольких уровней приоритетов рассмотрения заявок: приоритет назначения ресурсов, приоритет использования и приоритет среди машин, удовлетворяющих одинаковым заявкам.
При работе Condor от пользователя не требуется специальной регистрации (account или login) на машинах где будет выполняться его задание - система сама выполняет регистрацию с помощью технологии удаленного вызова RSC (Remote System Call), позволяющей перехватывать вызовы ОС при выполнении операций чтения/записи файлов и пересылать их на машину откуда было запущено задание. Таким образом, пользователь может не волноваться о доступности файлов на удаленной машине или получении для себя account. Система не требует использовать какой-либо специальный ПО и способна выполнять обычные UNIX и NT программы, а пользователю нужно только пересобрать свою задачу с библиотеками Condor. Права хозяев рабочих станций, включенных в пул Condor ни в коей мере не ущемляются - они могут использовать свои машины без каких-либо ограничений и при этом с их стороны не требуется специальных усилий по дополнительному администрированию.
Архитектура Condor
Аппаратная структура
Аппаратная архитектура системы включает три типа компьютеров (рис. 1), объединенных в единый пул Condor: центральный менеджер (Central Manager), выполняющие машины (Execute Machine), запускающие машины (Submit Machine).
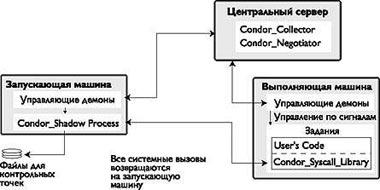 |
| Рис. 1. Архитектура Condor |
Центральный сервер. Один компьютер в пуле должен выполнять функции менеджера, собирающего информацию о всех машинах и выступающего в роли брокера между имеющимися ресурсами и пользователем. Сбой в работе компьютера, на котором установлен центральный менеджер приведет к остановке всего комплекса.
Выполняющая машина. Любая машина в пуле, в том числе центральный сервер и запускающая машина, может быть сконфигурирована для выполнения заданий Condor.
Запускающая машина. Любая машина из пула, с которой осуществляется запуск задания. Желательно, чтобы на данной машине было достаточно ресурсов для выполнения управляющих демонов. Каждое прерываемое для обработки контрольной точки задание имеет ассоциированный файл размером с файл задания, поэтому на диске запускающей машины должно быть достаточно свободного места для сохранения этого файла.
Кроме этих машин в пуле может быть «Сервер контрольных точек» (Checkpoint Server), на котором хранятся все рабочие файлы для обработки контрольных точек прерванных заданий.
Программная архитектура
Condor_master. Демон, контролирующий работу всех демонов Condor, запущенных на каждой машине пула и выполняющий административные команды системы. Данный демон должен быть запушен на каждой машине из пула.
Condor_startd. Демон для представления ресурсов в пуле. Работает на каждой выполняющей машине и в случае ее готовности к выполнению задания запускает демон condor_starter.
Condor_starter. Демон для запуска заданий и мониторинга процесса его выполнения на конкретной машине. После завершения задания демон посылает уведомление запускающей машине и прекращает свою работу.
Condor_schedd. Демон управления ресурсами, необходимыми для пула Condor и должен работать на каждой запускающей машине. При запуске задания происходит обращение к schedd, который размещает задание в очереди заданий. При сбое демона schedd никакая дальнейшая работа невозможна.
Condor_shadow. Демон, работающий на запускающей машине и выполняющий функции менеджера ресурсов. Все системные вызовы с удаленных машин пересылаются демону condor_shadow, где выполняются, а результаты отправляются обратно удаленной машине и заданию.
Condor_collector. Сбор информации о состоянии пула Condor. Все другие демоны периодически посылают этому демону данные о своем состоянии.
Condor_negotiator. Демон управления состоянием Condor. Периодически демон запускает цикл согласования, в течение которого собираются данные о состоянии ресурсов, текущем положении каждого демона condor_schedd с целью изменения приоритетов и т.п.
Condor_ckpt_server. Демон, реализующий функции сервера обработки контрольных точек. В его задачу входит сохранение текущего состояния задания.
Для инсталляции Condor требуется прежде всего развернуть Центральный сервер, на котором будут выполняться демоны condor_collector и condor_negotiator, выполняющие функции связного между всеми имеющимися машинами и заданиями, ожидающими выполнения. В случае сбоя этого сервера все активные задания будут выполняться вплоть до завершения, но новые задачи запускаться не будут. Более того, большинство инструментов Condor станет недоступно.
Все демоны Condor рекомендуется с правами root, в противном случае, система не гарантирует безопасной работы. Полезно также создать пользователя с именем ?condor? на всех машинах пула - демоны будут создавать файлы (например log-файл), владельцем которых будет этот пользователь, а каталог home будет применяться для указания местоположения файлов Condor. На каждой машине пула должны быть подкаталоги ?spool?, ?log?и ?execute? каталога указанного в параметре LOCAL DIR файла конфигурации. Каталог execute используется для хранения заданий Condor, выполняемых на данной машине, spool необходим для хранения очередей и файлов истории, а также файлов контрольных точек для всех заданий от запускающей машины, log - место размещения log-файлов каждого демона Condor.
Управление ресурсами
Как уже говорилось, система Condor работает по типу брокера между продавцами - пулом свободных машин и покупателями - пользователями, запускающими свои задания. Покупатель, например, готов потратить на покупку не более чем X рублей, а продавец будет работать, если ему светит доход не менее чем Y руб. Кроме этого, оба субъекта сделки задают диапазоны своих пожеланий и скидки (премии). Таким образом, кроме имеющихся ресурсов, машины сообщают при каких условиях они буду выполнять задания от Condor и какой тип задач предпочтителен. Например, машина с именем «dec8400» будет обрабатывать задания только ночью при физическом отсутствии пользователей. Кроме того, предпочтительное право занимать своими заданиями эту машину будет, например, принадлежать сотрудникам подразделения №666.
Со стороны покупателя также выставляются требования к товару (машине), например наличие процессоров, хорошо работающих с вещественной арифметикой, либо имеющих память не менее 128 Мбайт. Все эти требования помещаются в ClassAd и доводятся до сведения Condor. Информацию из ClassAd можно вывести на экран станции пользователя с помощью статусных команд.
Подготовка задания
Процесс подготовки задания предусматривает описание системного окружения (Universe) системы и, возможно, сборку задачи вместе с библиотеками Condor, с помощью специальных команд компиляции.
Прежде всего, надо учесть, что Condor выполняет задание в автоматическом режиме на фоне работы вычислительного комплекса, поэтому надо убедиться, что программа способна работать без вмешательства пользователя. Здесь же надо подумать о переназначении потоков stdout и stderr, stdin. В Соndor очень просто организовать многократное выполнение задания на разных входных данных - для этого надо специальным образом оформить задание, так, чтобы для каждого запуска было предусмотрено свое множество входных и выходных файлов (см. пример 3 на врезке).
При запуске заданий в Condor (версия 6.1.12) можно использовать пять различных режимов работы: «Standard», «Vanilla», «PVM», «MPI» и «Globus». Режим «Standard» обеспечивает максимально возможные средства миграции и надежности выполнения задания, однако, при его использовании имеются некоторые ограничения на тип запускаемых программ. Режим «Vanilla» предоставляет более бедные возможности, но и не накладывает на программы существенных ограничений. Режим «PVM» предназначен для программ, использующих интерфейс Parallel Virtual Machine, а «MPI» нужен для программ, работающих под MPICH. Режим «Globus» позволяет пользователям вызывать систему Globus через интерфейс Condor.
Standard. В этом режиме осуществляется поддержка контрольных точек и вызов удаленных системных функций (RSC), что позволяет использовать ресурсы из всего компьютерного пула Condor через унифицированный интерфейс. Однако для этого необходимо собрать задание с библиотеками Condor при помощи, например, команды
% condor_compile cc main.o tools.o -o program
Возможно также использование любого другого компилятора gcc, g++, g77, cc, acc, c89, CC, f77, fort77 and загрузчика.
Вызов удаленных системных функций позволяет создать для задания максимально комфортное окружение, как если бы речь шла о его выполнении на машине пользователя. При выполнении задания на другой машине на запускающей стартует второй процесс condor_shadow, который перехватывает каждую попытку задания обратиться к системным функциям и выполняет все сам, возвращая заданию соответствующий результат. Таким образом, если заданию надо, например, открыть файл, который имеется только на запускающей машине демон condor_shadow найдет этот файл и переадресует обращение к нему на выполняющую машину, на которой в данный момент идет счет задания.
Vanilla. Данный режим предназначен для программ, которые нельзя пересобрать заново с библиотеками Condor (например, по причине отсутствия исходных текстов). В этом режиме невозможно использование контрольных точек и RSC. В случае сбоя или выключения выполняющей машины задание будет либо ожидать возможности возобновления ее работы, либо будет заново запущено на другой. Передача данных возможна через NFS или AFS.
Режим Globus. Режим необходим для подключения к стандартному интерфейсу Globus путем трансляции очереди в строку на языке Globus RSL и помещается в качесвте аргумента для команды globusrun.
Обращение к Condor
С помощью команды «submit» пользователь размещает свое задание в Condor, указывая выполняемый файл, имена файлов потокового ввода/вывода для клавиатуры и экрана (stdin и stdout) и адрес email для оповещения о завершении задания. Можно также указать сколько раз надо выполнять программу, какие данные при этом надо использовать, какой тип машины требуется для запуска задания, имя выполняемой задачи, исходные рабочие каталоги, командную строку. На основе данной информации создается новый объект ClassAd, который передается демону condor_schedd, выполняемому на запускающей машине.
Если требуется получить описание всех возможных атрибутов для конкретной машины из пула Condor можно вызвать команду «status -l «имя машины»», например, «status -l alfred»:
MyType = «Machine» TargetType = «Job» Name = «dmitrii.cs.wisc.org» Machine = «dmitrii.cs.wisc.org» StartdIpAddr = «<128.105.83.11:32780>» Arch = «INTEL» OpSys = «SOLARIS251» UidDomain = «cs.wisc.org» FileSystemDomain = «cs.wisc.org» State = «Unclaimed» EnteredCurrentState = 892191963 Activity = «Idle» EnteredCurrentActivity = 892191062 VirtualMemory = 185264 Disk = 35259 KFlops = 19992 Mips = 201 LoadAvg = 0.019531 CondorLoadAvg = 0.000000 KeyboardIdle = 5124 ConsoleIdle = 27592 Cpus = 1 Memory = 64 AFSCell = «cs.wisc.org» START = LoadAvg - CondorLoadAvg <= 0.300000 && KeyboardIdle > 15 * 60 Requirements = TRUE
Поле «Activity» обозначает состояние: Idle - машина свободна, Busy : занята, Suspended : задание приостановлено, Vacating : задание в контрольной точке, Killing - задание прервано. Поле «Arch» - архитекура машины: «INTEL», «ALPHA», «SGI», «SUN4u» (Sun ULTRASPARC), «HPPA1» (PA-RISC 1.x PA-RISC 7000), «HPPA2» (PA-RISC 2.x PA-RISC 8000) и т.п. Кроме этого указывается средняя загрузка машины, количество процессоров, объем памяти на диске, объем оперативной памяти, производительность в KFLOPS (по тесту Linpack) и MIPS (по тесут Dhrystone), имя машины, тип ОС, IP адрес, состояние: «Owner» недоступна для Condor, «Unclaimed»: доступно с низким приоритетом, «Matched» : машина подходит для работы, но пока Condor планировщик не включил ее в список ресурсов; «Claimed» - машина взята в пул; «Preempting»: задание выгружено (возможно после контрольной точки) с другой машины.
Система Condor не обеспечивает автоматическую конвертацию на другие архитектуры и по умолчанию предполагается запуск задания на выполняющей машине, имеющей ту же архитектуру, что и запускающая машина. Если имеет место различие архитектур, например задание было запущено с Intel LINUX, а в пуле Condor большинство станций SPARC Solaris, то организуется компиляция и сборка задания для выполнения на другой архитектуре. Для изменения нужно включить в описание строку: Arch = «SUN4x» && OpSys== «SOLARIS251».
Управление процессом выполнения задания
В процессе выполнения задания пользователь может наблюдать за ходом работы с помощью команд «q» и «status» и, возможно, модифицировать задание. Если потребуется Condor может также посылать уведомления о всех изменениях состояния задания: обработка контрольной точки, миграция на другую машину, размещение в очередь ожидания и т.п. Полный список доступных машин можно получить по команде «status -submitters»:
% condor_status -submitters Name Machine Running IdleJobs MaxJobsRunning ashoks@jules.ncsa.ui jules.ncsa 74 54 200 breach@cs.wisc.edu neufchatel 23 0 500 d.vlk@raven.cs.wisc raven.cs.w 1 48 200 ashoks@jules.ncsa.ui 74 54 jbasney@cs.wisc.edu 0 1 Total 109 103
Для идентификации выполняемых работ можно использовать команду «% condor_q»:
— Submitter: froth.cs.wisc.edu : <128.105.73.44:33847> : froth.cs.wisc.edu ID OWNER SUBMITTED CPU_USAGE ST PRI SIZE CMD 125.0 jbasney 4/10 15:35 0+00:00:00 U -10 1.2 hello.remote 127.0 raman 4/11 15:35 0+00:00:00 R 0 1.4 hello 128.0 raman 4/11 15:35 0+00:02:33 I 0 1.4 hello 3 jobs; 1 unexpanded, 1 idle, 1 running, 0 malformed
Колонка ST (status) показывает состояние задания в очереди: «U» - выполнение без контрольных точек; «R» - выполнение в данный момент; «I» - выполнялось ранее, а сейчас в контрольной точке и ожидания свободной машины. Эту же информацию можно получить в файле состояния «log».
Можно посмотреть все машины, выполняющие конкретное задание с указанной машины, например «d.vlk@cs.wisc.org»:
% condor_status -constraint ?RemoteUser == «d.vlk@cs.wisc.org»? Name Arch OpSys State Activity LoadAv Mem ActvtyTime biron.cs.w INTEL SOLARIS251 Claimed Busy 1.000 128 0+01:10:00 cambridge. INTEL LINUX Claimed Busy 0.988 64 0+00:15:00 falcons.cs INTEL SOLARIS251 Claimed Busy 0.996 32 0+02:05:03 istat03.st INTEL SOLARIS27 Claimed Busy 0.883 64 0+06:45:01
При выполнении задания пользователю назначается определенный приоритет, который может быть изменен командой «userprio». Чем меньше значение приоритета, тем лучше и тем больше машин будет доступно для выполнения. Первоначально приоритет равен 0.5 и изменяется в зависимости от запрашиваемых ресурсов. Чем меньше подходящих машин в пуле, тем выше значение приоритета. Изменение происходит автоматически, однако при конфигурации можно задавать периодичность коррекции приоритетов. При появлении в пуле пользователей с большим приоритетом (меньшим его значением) задания пользователя с меньшим приоритетом (большим его значением) будут немедленно выгружены с освобождением ресурсов для нового пользователя. В дополнении к приоритету пользователя можно изменить приоритет задания внутри своего пакета задач. Кроме того, при запуске задания могут быть помечены как «nice» - выполнят на машинах, на которых нет других Condor заданий.
После завершения работы Condor уведомляет пользователя через email, сообщая ему число процессоров, задействованных при счете и общее время нахождения задания в пуле. Можно удалить задание не дожидаясь завершения (команда «rm»).
Выполнение параллельных приложений
Система Condor может быть использована для автоматического создания среды выполнения параллельных заданий по технологии PVM путем динамического предоставления свободных в данный момент машин. При этом Condor-PVM действует в роли менеджера ресурсов для демона PVM и как только PVM - программе потребуется дополнительные узлы будет сформирован запрос для Condor на поиск свободных машин из пула и их размещение в виртуальную машину PVM версии 3.3.11.
Среди наиболее общих парадигм параллельных программ в системе Condor реализована наиболее общая - «мастер - рабочий». Один узел выполняет роль мастера, контролирующего процесс выполнения параллельных приложений и распределяющего наряды на работу другим узлам (рабочим). Рабочие выполняют вычисления и отсылают результат обратно мастеру. Роль мастера выполняет запускающая машина, а рабочих - все остальные машины из пула. Если рабочий не в состоянии выполнить работу по причине отключения или занятости, то мастер передает ее другому. Если мастер замечает, что число рабочих недостаточно для выполнения всего объема работ, он (через вызов pvm addhosts()) запрашивает новых рабочих данной квалификации (нужной архитектуры), либо пытается перераспределить работы между имеющимися рабочими, каждый из которых обладает своей производительностью и «навыками».
Для работы в режиме Condor-PVM не требуется изменений программы - используется существующий стандартный интерфейс вызовов PVM, таких как pvm addhosts() и pvm notify(). При описании задания пользователь указывает режим «universe = PVM», а система сама создает программу - «мастер» и условия для запуска рабочих с помощью команды pvm spawn. Фактически, обычные PVM-программы имеют двоичную совместимость с Condor.
Кроме PVM система Condor поддерживает выполнение параллельных приложений, использующих MPI в версии от Аrgonne National Labs для устройства (способа, который MPICH применяет для выполнения коммуникаций между процессами) «ch p4» - кластер рабочих станций.
В отличие от PVM текущие реализации MPICH не допускают динамического распределения ресурсов, поэтому, если задание запущено, например, на четырех узлах, то ни один из них не может быть выгружен другими заданиями Condоr. Кроме этого, пока в реализации Condor MPICH не существует диспечеризации, поэтому возможна ситуация когда ни одна из задач не сможет выполняться (deadlock). Создание такого диспетчера - основная задача следующей версии Condor.
Машины, предназначенные для выполнения заданий MPI, должны иметь разделяемую файловую систему - нельзя использовать RSC, как это предусмотрено в режиме Standard.
Ограничения Condor
Изначально разработка Condor носила исследовательский характер и только совсем недавно, под влиянием возрастающего интереса к распределенным вычислениям (метакомпьютингу) разработчики получили достаточное финансирование, позволяющее существенно развить функциональность системы и повысить ее надежность. А пока в текущих версиях имеется ряд существенных ограничений.
На платформах HP UX и Digital Unix (OSF/1) не поддерживаются разделяемые библиотеки, поэтому возможны только статические задания (на платформах IRIX, Solaris и LINUX работа с контрольными точками поддерживается для разделяемых библиотек).
В задании нельзя указывать вызовы fork(), exec(), system() - допускается работа только одного процесса. Нельзя организовать взаимодействие процессов через семафоры, конвейеры и разделяемую память. Не поддерживаются такие функции как таймеры, будильники и ждущие процессы: alarm(), getitimer() и sleep(). Несмотря на то, что в Condor поддерживаются сигналы и их дескрипторы имеются зарезервированные сигналы SIGUSR2 и SIGT-STP, которые нельзя использовать в коде пользовательских программ.
В системе не поддерживаются команды межпроцессорного взаимодействия (IPC): socket(), send(), recv(). Не допускается использовать множественные потоки на уровне ядра и применять функции отображения файлов в память mmap() и munmap(). Не допускается блокировка файлов, а все файловые операции должны быть идемпотентными - «только чтение» и «только запись», поэтому программы, которые одновременно читают и пишут в один файл могут работать некорректно.
Если текущий рабочий каталог на запускающей машине доступен через NFS, то у системы могут быть проблемы с автоматическим монтированием дисков (automounter) если потребуется размонтировать каталог до завершения задания.
По умолчанию, система Condor конфигурируется так, чтобы позволить любому желающему видеть состояние работы в пуле, однако, при необходимости этот режим можно изменить, предусмотрев, например, различные уровни доступа. В системе можно установить следующие уровни доступа: READ, WRITE, ADMINISTRATOR, OWNER, NEGOTIATOR.
READ. Машины с таким доступом могут только читать информацию из Condor, например: статус пула, очередь заданий и т.п., ничего не меняя. WRITE - доступ для записи, что означает возможность обновления ClassAd и инициацию других машин на выполнение задания. Кроме того, машины с уровнем WRITE могут запрашивать демон startd для периодического выполнения записи по контрольной точке любого задания. ADMINISTRATOR - изменение приоритетов пользователя, активация или исключение машины из пула, запрос на реконфигурацию, рестарт и т.п. OWNER - уровень пользователя-владельца машины. NEGOTIATOR - специальный уровень доступа, означающий, что специальные команды работы с пулом (например опрос состояния) будут обрабатывать только если они пришли от центрального сервера. Можно указать перечень команд, разрешенных для исполнения. Уровень NEGOTIATOR автоматически назначается системой, остальные четыре уровня обычно прописываются в файле конфигурации. Права ADMINISTRATOR по умолчанию принадлежат только центральному менеджеру, OWNER - выполняющей машине.
Condor в когтях у NT
Прежде всего следует отметить, что текущая версия Condor Preview 6.1.8 - это еще не окончательный вариант, способный полноценно работать под управлением NT. Пока не реализованы режимы Standard, PVM и Globus. Работает только режим Vanilla, что означает отсутствие возможностей работы с контрольными точками, миграции и RSC. Доступ к разделяемым файлам по сети возможен только средствами NT Server, Novell Netware и AFS. Все файлы, необходимые для работы задания должны размещаться только на локальных дисках запускающей машины - Condor NT автоматически передает файлы на выполняющий компьютер. Имеются определенные ограничения на передачу данных между запускающей и выполняющей машиной, например можно передавать только файлы, а не каталоги, поэтому, если в рабочем каталоге выполняющей машины задание создает дерево с результатами, то их нельзя будет передать на запускающую машину. Кроме того, если задание удалило файлы из рабочего каталога они не будут удалены из соответствующего каталога на запускающей машине.
Нельзя также выполнять задания с теми же правами как и у пользователя, работающего на запускающей машине. Вместо этого Condor динамически создает и запускает задания в специальном разделе, имеющем минимальные права доступа.
Запуск заданий в Condor NT
Для запуска задания демон startd на выполняющей машине вызывает процесс запуска, который:
1. создает на выполняющей машине временный рабочий каталог для пользователя с именем «condor-run-dir XXX», где XXX идентификатор ID процесса starter. Этот account добавляется в группу Users и Everyone;
2. для нового задания на выполняющей машине создается подкаталог с именем «dir XXX», где XXX - ID демона starter;
3. для задания создается новая скрытая Window Station и Desktop.
Затем демон starter связывается с демоном shadow, работающим на запускающей машине, выбирает само задание и файлы к нему, которые, с помощью специально разработанного для версии NT механизма Condor File Transfer, размещаются во временном каталоге на выполняющей машине. Затем задание запускается и начинается его мониторинг. Каждые 20 минут демон starter шлет информацию на демону shadow, который включает ее в ClassAd для динамического управления.
После успешного завершения задания starter сбрасывает все процессы от этого задания, ищет в рабочем каталоге файлы, созданные заданием и пересылает их демону shadow, который размещает их на запускающей машине. После этого задание исключается из очереди, а рабочий каталог удаляется. Если задание завершилось (было удалено) до того как все выходные файлы были переданы, то задание из очереди не удаляется, а изменяет свой статус на «Idle».
Совместимость между Condor Unix и Condor NT
В одном пуле Condor могут сосуществовать одновременно Unix и NT машины. Единственное ограничение - задания, запущенные с NT-машины должны выполняться только на NT, аналогично и для Unix машин. При этом в гетерогенной среде может быть только один центральный менеджер Condor, работающий на любой из двух платформ.
Разделяемая файловая система в версии для NT пока не реализована, поэтому для передачи файлов используется механизм Condor File Transfer. Имеются определенные различия в размещении файлов, например описание конфигурации для Unix версии Condor располагается в каталоге /etc, а для версии NT адрес config указывается в реестре HKEY_LOCAL_MACHINE/Software/Condor. Имеются также различия и в содержимом Log-файла, создаваемом в случае сбоя задания - вместо дампа памяти в NT версии создается небольшой ASCII текст с указанием причины нарушения работы.
Установка Condor NT
Для установки Condor NT требуется Windows NT 4.0 Service Pack 5 и 30 Мбайт пространства на диске с файловой системой NTFS или FAT для размещения собственно файлов Condor на локальном диске С:. После установки системы на центральный сервер и создания файла конфигурации требуется задать политику обработки запросов. Имеется несколько вариантов: выполнять задание независимо от состояния машины; только если пользователь не работает за консолью (клавиатура или мышь) в течении последних 15 минут; запускать при низкой загрузке СPU (менее 30% на процессор); выполнять независимо от загрузки, но после 15 минут неактивности с консоли. Можно также описать порядок обработки задания после активации консоли: здание выгружается и через 5 минут продолжения активности консоли Condor решает, что делать с частично выполненным заданием. Можно завершить задание через пять минут после активации и завершить немедленно. Учитывая, что в версии для NT нет контрольных точек, то задание будет просто запущено заново на этой же машине если образуется окно неактивности размером 10 минут.
Работа выполнена при финансовой поддержке Российского фонда фундаментальных исследований (проект N 99-01-00389) и Министерства промышленности, науки и технологий РФ (гос. контракт № 203-3(00)-П).
Дмитрий Владимиров (osmag@sp.ru) -- независимый автор, (Москва).
Литература
1. Виктор Коваленко, Дмитрий Корягин. Вычислительная инфраструктура будущего. // «Открытые системы.СУБД», 1999, №11-12, с.45-52.
| Name | Arch | ОС | State | Load | Mem | Actvty-Time |
| adriana.cs | INTEL | SOLA-RIS251 | Claimed Busy | 1.000 | 64 | 0+01: 10:00 |
| alfred.cs. | INTEL | SOLA-RIS251 | Claimed Busy | 1.000 | 64 | 0+00: 40:00 |
| amul.cs.wi | SUN4 | SOLA-RIS251 | Owner Idle | 1.000 | 128 | 0+06: 20:04 |
| anthrax.cs | INTEL | SOLA-RIS251 | Claimed Busy | 0.285 | 64 | 0+00: 00:00 |
Примеры файлов описания задания
Пример 1. Выполнение одной копии программы «f_r30».
Система будет пытаться выполнить задание на машине с той-же архитектурой и ОС, что и запускающая машина.
Executable = f_r30 Queue
Пример. 2. Создание очереди для двух копий программы «mathematica». Первая копия выполняется в каталоге «run 1», вторая в «run 2». В обоих случаях задаются имена файлов для обработки stdin, stdout и stderr.
Executable = mathematica Universe = vanilla input = test.data output = loop.out error = loop.error Initialdir = run_1 Queue Initialdir = run_2 Queue
Пример 3. Запуск программы «irbis» 150 раз. Программа должна быть компилирована и собрана на станции Silicon Graphics под ОС IRIX 6.x с памятью не менее 32 Мбайт и запушена на машине с памятью не менее 64 Мбайт. Заданы файлы stdin, stdout и stderr: «in.ххх», «out.ххх» и «err.ххх» где ххх - номер запуска. Файл состояния «irbis.log» будет содержать данные о миграциях и прерываниях задания.
Executable = irbis Requirements = Memory >= 32 && OpSys == «IRIX6» && Arch ==»SGI» Rank = Memory >= 64 Image_Size = 28 Meg Error = err.$(Process) Input = in.$(Process) Output = out.$(Process) Log = irbis.log Queue 150
