Распределенные вычислительные системы — основное направление развития программного обеспечения. Совершенствование сетевых технологий и процессорных систем позволяет реализовать давнюю мечту программистов — объединить несколько независимых компьютеров в единый вычислительный комплекс. При создании таких вычислительных систем у их разработчиков часто возникает необходимость в передаче данных между приложениями и в их синхронизации. Для этого обычно используют мониторы транзакций. Однако для создания небольших распределенных систем использовать монитор транзакций слишком расточительно.
В некоторых случаях достаточно иметь центральное хранилище информации, через которое можно организовать передачу данных между частями приложений или их синхронизацию. Использовать для этого систему управления базами данных сложно, так как СУБД требует значительных компьютерных ресурсов и кропотливого программирования. Применение более простых систем позволило бы разработчикам упростить работу распределенных приложений. Для синхронизации распределенных вычислительных комплексов предназначена технология T-Space, которая разработана в Алмаденском центре исследований корпорации IBM. Эта технология для организации взаимодействия элементов системы использует язык программирования Java и модель хранения данных, которую можно назвать хранилищем кортежей (tuplespace).
«Хранилище кортежей»
Прежде чем приступать к описанию технологии T-Space, необходимо несколько слов сказать о системе хранения данных в виде хранилища кортежей. Понятие такого хранилища было введено в рамках известного исследовательского проекта Linda. Целью этого проекта была разработка языка параллельных вычислений с помощью добавления в стандартные последовательные языки (такие как, Си и Фортран) элементов взаимодействия с помощью таких структур данных как кортежи. В результате этого проекта должны были появиться такие языки, как C-Linda или Fortran-Linda.
Основной единицей информации в хранилище кортежей является кортеж — последовательность полей, для которых определены значение и тип. Хранилище кортежей представляет собой доступный всем процессам одинаковый набор кортежей, которые любой процесс может получить с помощью определенного шаблона. Шаблон — это кортеж, у которого есть одно или более формальных полей, то есть такое поле, у которого значение не определено, но имеет определенный тип. Выборка кортежей из хранилища выполняется с помощью механизма соответствия хранимых кортежей заданному шаблону. Кортеж соответствует шаблону, если он имеет одинаковое с шаблоном количество полей, значения всех неформальных полей соответствуют значениям соответствующих полей шаблона, а тип всех формальных полей соответствует типу формальных полей шаблона.
Шаблоны (float, «hello», int)
(float, String, 345.0)
Кортежи
<2.24, «hello», 345> Да Нет
<2.24, «hello», 345.0> Нет Да
<> Нет Нет
Принцип соответствия кортежа шаблону проиллюстрирован в примере. В нем первый кортеж не соответствует второму шаблону потому, что целое значение 345 кортежа не равно действительному — 345.0, указанному в шаблоне. Второй же кортеж не соответствует первому шаблону потому, что типы последних значений кортежа и шаблона не совпадают. Пустой кортеж не соответствует ни одному шаблону.
Принципы работы с хранилищем кортежей следующие. Запись кортежей в хранилище выполняется с помощью простой операцией write, которой передается кортеж в качестве аргумента. Чтение выполняется с помощью операции read или take с помощью принципа соответствия — из хранилища выбирается первый кортеж, который соответствует заданному в аргументе шаблону. Операция чтения может быть как с удалением прочитанного кортежа (take), так и без удаления (read). Поскольку модель хранилища не определяет его структуры, то последовательность получения кортежей из хранилища зависит от его реализации. При этом если есть несколько кортежей, соответствующих шаблону, то заранее не определено, какой из них будет выбран первым. Предусмотрены два варианта операций чтения — блокирующее и неблокирующее. В первом случае, при отсутствии кортежа в хранилище, операция чтения будет блокирована до тех пор, пока соответствующий шаблон не будет в него записан. Во втором случае, при тех же условиях операция чтения выдаст сообщение «кортеж не найден».
Хранилище кортежей предполагалось использовать для организации взаимодействия и синхронизации различных процессов. Процесс, которому нужно передать данные другим процессам, просто записывает их в хранилище, а процесс-потребитель может их оттуда получить в любой момент. Причем так можно организовать не только передачу данных от одного процесса другому, но и синхронизовать два или более процессов. Для этого можно использовать механизм блокирующего чтения, при котором функция чтения блокирует выполнение процесса до тех пор, пока другой процесс не запишет в хранилище «разрешающий» кортеж.
Использование хранилища кортежей имеет следующие преимущества по сравнению с передачей сообщений:
- Анонимность получателя. При отправлении сообщений, процесс-отправитель должен определить получателя сообщения. Использование же в хранилище кортежей ассоциативного чтения позволяет отправителю не указывать получателя сообщения — он просто помещает данные в хранилище, а кто ими воспользуется — уже не имеет значения.
- Масштабируемость. Поскольку при взаимодействии через хранилище кортежей не требуется явная адресация, то оно может быть неограниченно большим: работать на одной машине, кластере или на нескольких отдельных машинах. Использование ассоциативной выборки позволяет избежать проблемы глобальных имен в распределенной системе.
- Независимость от времени. Поскольку кортеж внутри хранилища живет своей жизнью, которая не зависит от процесса-отправителя, то через хранилище можно организовать взаимодействие даже между разнесенными во времени процессами.
Фактически, хранилище кортежей является системой передачи сообщений, которая дополнена репозиторием и ассоциативной адресацией. Таким образом, Пространство представляет собой нечто среднее между системой передачи сообщений и СУБД. При этом от системы передачи сообщений наследуется простота составления запроса к системе, а от СУБД — более широкая функциональность.
Несмотря на определенные достоинства, хранилище кортежей имеет и некоторые недостатки. Одним из них является то, что алгоритм соответствия может работать только на одной платформе, поскольку в различных платформах приняты различные способы определения типа объектов. Кроме того, наличие только простых операций чтения и записи не позволяет решать многие проблемы управления накопленными в хранилище данными. Отсутствие определенной структуры хранения кортежей усложняет обработку и анализ большого объема данных, который может содержаться в хранилище кортежей. Попытка решить эти недостатки с помощью языка Java и современных технологий баз данных привели к возникновению T-Space.
T-Space
В качестве платформы в T-Space выбрана Java, которая позволяет работать в различных операционных системах, сохраняя при этом одинаковую типизацию объектов. Кроме того, сетевые возможности Java позволяют реализовать с ее помощью распределенное хранилище кортежей, которое уже будет работать не только как среда передачи данных между процессами или компьютерами, но и частично сможет заменить сервер СУБД. Таким образом, можно будет существенно расширить возможности, заложенные в архитектуре хранилища картежей, объединив в T-Space универсального посредника между распределенными элементами приложений и систему хранения данных. Кроме того, в T-Space предусмотрены различные дополнения, которые позволяют решать с ее помощью более сложные задачи.
Технология T-Space имеет следующие характерные особенности:- Расширенный набор операторов. Кроме стандартных для хранилища кортежей операторов write и read (с различными вариантами исполнения), добавляются и некоторые дополнительные операторы для управления данными, такие как scan и consumingscan.
- Динамическое изменение поведения. Кроме дополнительных операторов, технология T-Space предусматривает возможность определять новые операторы, которые можно динамически загружать на сервер T-Space.
- Целостность репозитория. В T-Space используется более современный механизм управления хранимыми данными, который похож на аналогичные механизмы в СУБД. Он позволяет выполнять занесение новых данных в репозиторий с сохранением контекста и целостности транзакций.
- Индексация и выборка данных, аналогичная СУБД. В T-Space предусмотрены механизмы индексации хранимых данных для более эффективного доступа к ним. Кроме того, выборка данных из репозитория T-Space производиться с помощью запросов, что позволяет улучшить пользовательский интерфейс.
- Контроль доступа. Разработчики системы на T-Space могут определять свою политику безопасности для доступа пользователей к данным. Для этого в системе предусмотрены идентификаторы пользователей, их группы, разрешения для каждой операции и иерархия хранилищ.
T-Space может быть использована в тех приложениях, для которых необходимо распространение данных между различными машинами или их хранение на различных машинах, а также в качестве наиболее простой СУБД. Фактически, T-Space можно использовать как базу данных, с неограниченным количеством типов, удобным пользовательским интерфейсом и простым языком составления запросов. Однако, поскольку технология находиться только на начальном этапе развития, то в ней нет механизмов распределенных транзакций, ограничен набор способов хранения информации, а также нет механизмов координации работы нескольких серверов T-Space. Если потребности приложения по использованию элементов базы данных не очень большие, то T-Space дает программистам хорошую возможность обойтись в разработке системы небольшим объемом памяти и упрощенными запросами. При этом сохраняются возможности распределенных вычислений и межплатформенного взаимодействия.
Реализация T-Space
T-Space представляет собой хранилище кортежей, работающее по схеме «клиент-сервер». Клиент в T-Space может послать на сервер любой кортеж, сопроводив его указанием о том, какую именно операцию сервер должен с ним сделать. Определение кортежа в T-Space стандартное — упорядоченная последовательность полей, для каждого из которых определены значение и его тип. Технологию T-Space разделить на три части: интерфейс с приложениями на клиенте, сам клиент и сервер.
Интерфейс к клиентской части T-Space
Давайте рассмотрим более подробно программный интерфейс клиента, через который приложение взаимодействует с клиентом T-Space. Большинство функций этого интерфейса — это чтение и запись кортежей в хранилища сервера T-Space. Этих операций, в принципе, достаточно для большинства возможных применений T-Space, но разработчики этой технологии дополнили их более удобными функциями управления данных, с помощью которых программисты могут составлять сложные запросы к серверу, определять политику безопасности и механизмы авторизации, а также динамически определять свои собственные операции. Прежде чем рассказывать о этих дополнительных возможностях, рассмотрим сначала базовый набор функций, который реализует модель хранилища кортежей.
Базовые операции в T-Space реализуют операции хранилища кортежей. Так для записи кортежа используется операция write. С ее помощью кортеж, который указан в аргументе операции, записывается в одно из хранилищ на сервере T-Space. Найти нужный кортеж можно с помощью операции чтения (read) и получения (take) кортежа. При исполнении этих операций в хранилище сервера ищутся кортежи, которые соответствуют аргументу-шаблону, и из них выбирается первый найденный кортеж. При этом операция take удаляет выбранный кортеж из хранилища, а read — нет. Если не найдено ни одного кортежа, который соответствовал бы шаблону-аргументу, то операции возвращают значение null, а содержимое сервера не изменяется. Приложение также может воспользоваться и блокирующими вариантами операций чтения и получения кортежей, которые называются waittoread и waittotake соответственно. Эти операции останавливают выполнение вызвавшего их процесса до тех пор, пока другой процесс не запишет в хранилище соответствующий этим запросам кортеж.
Кроме стандартных для хранилища кортежей операций чтения можно воспользоваться и дополнительными — scan, consumingscan и count, которые позволяют более удобно организовать перебор найденных на сервере кортежей. Операции scan и consumingscan — это варианты чтения и получения кортежей, которые возвращают сразу все найденные кортежи, и позволяют последовательно перебрать их. Операция count возвращает количество кортежей на сервере, которые соответствуют шаблону-аргументу. Эти операции позволяют программистам легко организовывать циклы для обработки всех полученных из хранилища данных.
В T-Space реализована еще одна базовая операция rhonda, которая предназначена для обмена значений между двумя процессами. В качестве аргументов этой операции передается кортеж и шаблон. Если два процесса вызвали операцию rhonda, для аргументов которых выполняется следующее: кортеж одной операции соответствует шаблону другой и наоборот, то процессы обменяются кортежами. Для иллюстрации работы этой операции, рассмотрим следующий пример. Два процесса вызывают операцию rhonda со следующими аргументами: первый — rhonda(<"A">, ), а второй — rhonda(<"B">, String). В результате выполнения этих операций первый процесс получит кортеж <"A">, а второй — <"B">. Таким образом, можно организовать обмен значениями между двумя процессами с синхронизацией их между собой.
Алгоритм проверки соответствия кортежа шаблону, который используется в T-Space, аналогичен тому, который определен для хранилища кортежей. Для операций чтения (read, take и аналогичных) используется шаблон, который является кортежем с одним или более формальными полями. Причем для формальных полей определен их тип, но неопределенно значение. Кортеж соответствует шаблону, если для него выполняются следующие три условия:
- И у кортежа и у шаблона должно быть одинаковое количество полей;
- Каждое поле кортежа является экземпляром того же типы, что и у соответствующего поля шаблона;
- Если поле шаблона не является формальным, то значение соответствующего поля кортежа должно быть равно значению поля шаблона.
Второе условие является расширением правил проверки соответствия кортежа шаблону для объектно-ориентированного языка программирования. В T-Space используется и более сложные механизмы проверки соответствия объектов, а также добавлена возможность составления сложных запросов, которые более похожи на механизмы выборки данных в СУБД. Дело в том, что при сопоставлении объектов в T-Space можно учитывать также и иерархия Java-классов. То есть тип поля в кортеже может быть не только экземпляром класса, указанного в шаблоне, но и экземпляром его наследника. Для наиболее простых приложений, которые не пользуются сложной иерархией классов, в T-Space предусмотрен класс Tuple, который не может иметь наследников.
Существенным отличием T-Space от хранилища кортежей, предложенного авторами Линды, является возможность поиска по именованным полям. Кроме типа, поле кортежа может иметь также и еще одну характеристику — имя. Такая организация кортежа позволяет использовать более простые операции выборки кортежей. Для выборки кортежа по именам полей в T-Space предусмотрена операция, которая имеет, например, следующую форму («foo», 8). В результате выполнения этой операции произойдет выбор из хранилища тех кортежей, у которых поле с именем foo имеет значение 8. Кроме того, можно указывать не только конкретное значение именованного поля, но и диапазон его значений.
В T-Space также предусмотрена возможность исполнения запросов различных типов. На данный момент реализованы четыре типа запросов: Match, Index, And и Or. Запрос Match используется для поиска кортежей с помощью механизма соответствия его полей по структуре или по иерархии типов. Для поиска кортежей по именам полей используется запрос Index. Два оставшихся запроса — And и Or — служит для составления комбинации запросов любого другого типа. Язык запросов, который используется в T-Space, приближает эту технологию к реляционным базам данных. Примеры различных запросов можно найти во врезке «Примеры запросов».
Для иллюстрации передачи данных в распределенных приложениях с использованием сервера T-Space рассмотрим пример взаимодействия двух клиентов T-Space через сервер. Первый клиент посылает на сервер кортеж с требованием выполнить для него операцию записи (write), и сервер сохраняет полученный кортеж в хранилище. Затем другой клиент может послать запрос на чтение (операция read) кортежа по соответствующему шаблону, и сервер выполнит операцию выборки соответствующих кортежей. Поскольку второй клиент использовал операцию чтения, а не изъятия значения, то копия кортежа также осталась в базе данных сервера.
Как работает клиент T-Space
Мы рассматривали ситуацию, когда клиент T-Space общается только с одним сервером. Однако, технология позволяет одному клиенту обращаться к различным серверам T-Space, хотя пока не реализована возможность организации многосерверных транзакций. Причем, коммуникационная библиотека клиента реализована так, что она не блокирует стек протоколов TCP/IP. Даже если процесс вызывает операцию блокирующего чтения, то приостанавливается работа только этого отдельного процесса, в то время как все остальные процессы, запущенные в клиентской Java-машине, продолжают работать независимо.
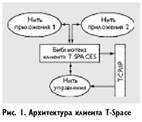
Клиентская часть T-Space состоит из двух основных классов — Tuplespace, который реализует интерфейс работы с процессами, и ResponseProcessor, распределяющего полученные ответы между различными процессами в Java-машине (см. Рис. 1). Процесс управляет экземпляром класса Tuplespace, с помощью которого подготавливаются все необходимые данные для передачи их на сервер через стандартную коммуникационную библиотеку Java. При этом результаты запроса процесс получает от класса ResponseProcessor.
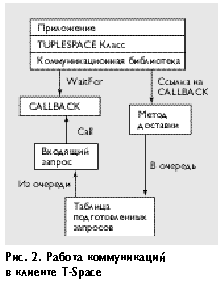
Коммуникационная библиотека снабжает каждый запрос уникальным идентификационным номером, который используется экземпляром ResponseProcessor для последующего распределения полученных ответов с сервера. Этот идентификатор сохраняется в специальной таблице запросов-ответов (экземпляр класса OutstandingRequestTable), которая используется классом Callback для синхронизации процессов. Класс Callback содержит два метода: waitForResponse, который устанавливает семафор, блокирующий исполнение процесса, пославшего запрос серверу, и call, убирающий блокировку, когда результаты получены. Таким образом, класс Callback используется для синхронизации приложения и экземпляра ResponseProcessor, причем все ответы сервера обрабатываются одинаково. Организация коммуникационной библиотеки со стороны клиента изображена на рисунке 2. Процесс не имеет прямой связи с коммуникационной библиотекой, а все операции выполняются через соответствующий экземпляр класса Tuplespace.
Как работает сервер T-Space
Как уже было сказано, для работы с сервером T-Space клиент должен создать экземпляр класса Tuplespace, с помощью которого приложением общается с сервером через коммуникационную библиотеку. Все операции, которые приложение выполняет в хранилище кортежей, управляются клиентским экземпляром Tuplespace через механизм удаленного исполнения методов RMI. Правда, в текущей реализации системы один экземпляр Tuplespace может работать только с одним сервером. Пока в классе Tuplespace нет функций работы с различными серверами. Чтобы приложение получило доступ к различным серверам T-Space, для каждого из них необходимо создавать свой собственный экземпляр класса Tuplespace.
Выполнение операции на сервере T-Space инициируется клиентом через Tuplespace с помощью механизма удаленного исполнения методов. Вся информация об операции передается между клиентом и сервером с помощью описанной выше коммутационной библиотеки. Причем, на сервере T-Space может быть несколько различных хранилищ кортежей, для управления которыми предназначено системное хранилище Galaxy. На сервере также есть и другое системное хранилище Admin, которое управляет политикой безопасности. Все операции доступные на сервере, управляются через класс TS, который перед исполнением операции, сверяется с системными хранилищами.
Код операции, которые можно использовать в пределах хранилища, экземпляр класса TS получает с помощью так называемой фабрики. По имени операции, кортежу и идентификатору клиента фабрика выбирает исполнимый код операции — обработчик (handler) и передает его в объект TS. Фабрики организованы в стек, который привязан к конкретному хранилищу. Если у фабрики нет кода, который соответствует запрашиваемым параметрам, то она посылает запрос на получение исполнимого кода к следующей фабрике стека. Таким образом, организация фабрик в стек позволяет легко изменять набор исполнимых операций и дополнять их новыми, для чего клиенту достаточно добавить свою фабрику в стек. Базовые операции хранилища реализованы в фабрике Basic. Структура сервера показана на рисунке 3.

Пользователи могут написать свой собственный обработчик операции и загрузить его на сервер T-Space. Для этого обработчик должен реализовать интерфейс TSHandler и может использовать в своем теле только простые операции работы с кортежами: запись и чтение кортежей, а также выполнять некоторые другие операции с данными. Этот интерфейс называется TSDB (TupleSpace DataBase). Он спроектирован так, чтобы операции с кортежами не зависели от реализации хранилища. Для добавления новой фабрики или нового обработчика используются операции addFactory и addHandler соответственно. Следует отметить, что эти операции должны разрешаться только особо проверенным пользователям.
Сейчас технология T-Space имеет три реализации интерфейса TSDB: TSSimpleDB — наиболее простая реализация, использующая массивы и хеш-таблицы; TSMMDB — более сложная база данных, работающая в оперативной памяти и использующая линейный ассоциативный хеш и T-дерево; TSLargeDB — интерфейс к СУБД DB2. Два первых хранилища работают только с оперативной памяти и самостоятельно организуют работу с кортежами, а класс TSLargeDB транслирует операции с кортежами в СУБД DB2. Обработчик может использовать как хранилище в оперативной памяти, так и DB2.
Класс TS является основным классом сервера. Он управляет сохранением кортежей и операциями работы с ними. Причем для кортежей и операций должно выполняться правило независимости одного от другого. То есть изменение количества кортежей ни как не должно влиять на набор операций в фабриках, а изменение числа операций не должно влиять на набор кортежей. Каждый экземпляр класса TS содержит имя хранилища, ссылки на интерфейс TSDB, через который организуется работа с кортежами, и на стек фабрик, соответствующий хранилищу. Функциональность класса TS такова: он по запросу клиента, получает из стека фабрик соответствующий исполнимый код операции, проверяет возможность выполнения операции с точки зрения политики безопасности, и только затем передает исполнимому коду аргументы, полученные от клиента.
Хранилище Admin содержит информацию о правилах доступа ко всем хранилищам сервера T-Space. В нем находятся кортежи, которые содержат следующую информацию: разрешение на доступ к каждому хранилищу, идентификаторы и пароли пользователей, списки групп пользователей. Это хранилище используется экземплярами классов TS для определения законности операции пользователей. Политика доступа к данным в T-Space построена по иерархическому принципу. Хранилища на сервере T-Space имеют определенную иерархию, в соответствии с которой определяются правила доступа к хранилищам. Так хранилище, которое находятся выше по иерархии, определяет права доступа к нижним по иерархии хранилищам. Кроме того, для каждой операции также установлены права доступа и исполнения. Таким образом, политика безопасности T-Space описывается в терминах прав доступа отдельных пользователей и групп, иерархии хранилищ кортежей и прав исполнения операторов.
Заключение
Разработка IBM позволяет организовывать передачу данных между элементами распределенных приложений и обеспечить их синхронизацию. Причем она имеет небольшой размер и достаточную функциональность, что позволяет эффективно использовать ресурсы распределенной системы. Однако, технология еще молодая, и для нее еще нет достаточного количества приложений, упрощающих разработку приложений и управление данными. Поэтому T-Space лучше всего использовать на небольших приложений, для которых несложно самостоятельно разработать все недостающие элементы. Стандартные механизмы организации систем клиент-сервер, которыми пользовались разработчики технологии T-Space, позволяют надеяться, что эта технология быстро займет свое место в ряду других аналогичных инструментов.
| Примеры запросов |
| Регулярный запрос: resultTuple = ts.read(«Superman», 75, new Rock(«Kryptonite») ); Этот запрос позволяет получить с сервера ts первый попавшийся кортеж, который соответствует шаблону <»Superman», 75, Rock(«Kryptonite»)>. При этом проверяется структурное соответствие кортежа. Запрос Match:queryTuple = new Tuple («Superman», 75, Rock); resultSetTuple = ts.scan (new MatchQuery(queryTuple )); Это также запрос на структурное соответствие кортежей, но в отличии от первого запроса, клиент получает все кортежи, соответствующие шаблону <»Superman», 75, Rock>. Причем, поскольку третий параметр является именем типа, то для поиска соответствующих кортежей достаточно, чтобы третье поле искомого кортежа было экземпляром наследника класса Rock. Запрос Or:queryTuple = new Tuple(new OrQuery(new IndexQuery(«Age», new Range(new Integer(10), new Integer(30))), new IndexQuery(«Age», new Range(new Integer(60) new Integer(90))))); resultSetTuple = ts.scan(queryTuple); Этот запрос также является комбинацией двух других запросов. Функция scan вернет все кортежи, у которых поле Age имеет тип Integer, а его значение лежит в диапазонах либо от 10 до 30, либо от 60 до 90. Запрос And:queryTuple = new Tuple(new AndQuery(new IndexQuery («Superhero», new Range(«A», «L»)), new IndexQuery(«Age», new Range(new Integer(10),new Integer(30))))); resultSetTuple = ts.scan(queryTuple); Этот запрос представляет собой комбинацию двух запросов. После его выполнения клиент получит все кортежи, в которых поле Superhero имеет тип String и его значение лежит между «A» и «L», а также поле Age является целым и лежит в диапазоне от 10 до 30. Запрос Index:queryTuple = new Tuple(new IndexQuery(«Superhoro», «Spiderman»)); resultSetTuple = ts.scan( queryTuple ); Это пример использования поиска шаблонов по имени поля. Функция возвращает все кортежи, в которых поле Superhoro имеет тип String и значение «Spiderman». Запрос Index с использованием диапазона значений:queryTuple = new Tuple(new (IndexQuery(«Superhero», new Range(«A», «L»))); resultSetTuple = ts.scan( queryTuple ); Запрос, аналогичен предыдущему, с той лишь разницей, что вместо значения поля Superhero задается диапазон его значений: от «A» до «L». |
