Время шло, приложений для БД становилось все больше и больше, а вместе с этим улучшалась и поддержка таблиц в языках баз данных.
Концепция нового поколения таблиц, соответствующая стандарту SQL и архитектуре некоторых коммерческих баз данных, предусматривала поддержку явно определенных производных таблиц (например, временных пользовательских таблиц), таблиц переходов, табличных функций, задаваемых пользователем, и средств поиска в таблицах. Совокупность этих компонентов мы называем их динамическими таблицами, поскольку они существуют только на этапе выполнения. Основная трудность, возникающая при управлении этими динамическими таблицами, заключается в адаптации существующих реляционных механизмов и установлении связей между процедурами создания производных таблиц и ссылками на эти таблицы. В данной статье мы остановимся на описании стандартных конструкций, используемых при компиляции и обработке таблиц на этапе выполнения. Кроме того, приведем подробное описание реализации общих конструкций в современных системах управления реляционными базами данных (в частности, в продукте IBM DATABASE 2 Common Server). Опыт работы с этими прототипами показал простоту, универсальность и эффективность данного подхода.
Использование таблиц и операций с ними были положены в основу реляционной модели и языка запросов SQL еще с момента изобретения этого языка в начале 70-х. В запросах определялись операции, где одни таблицы, а другие выдавались на выходе. Обработка запросов механизмом системы управления реляционными базами данных также строилась на основе реляционных операторов (ограничений, проекций, объединений и т.д.), которые манипулировали потоками записей таблиц.
Язык SQL поддерживает таблицы двух основных типов: базовые и производные. В стандарте SQL-92 базовые таблицы используются для хранения информации в БД. В отличие от базовых производные таблицы определяются в терминах существующих базовых или других производных таблиц. Они могут задаваться или явно пользователем, или неявно механизмом базы данных. В стандарте SQL-92 явно определенные производные таблицы называются «представлениями» («views») и создаются при помощи оператора CREATE VIEW. Неявно определенные производные таблицы представляют собой временные наборы данных, которые формируются в процессе обработки таблиц, предназначены для записи промежуточных результатов и в общем случае не могут напрямую управляться пользователем. Внутреннее управление организуется при помощи средств СУБД.
Приложений для БД становится все больше и больше, совершенствуется и концепция таблиц в четвертой версии языка SQL и в ряде коммерческих СУБД. В качестве примера можно привести определяемые пользователем временные таблицы стандарта SQL-92, таблицы перехода внутри триггеров в SQL3 и определяемые пользователем табличные функции в продукте IBM DATABASE 2 (DB2) Universal Database (UDB).
Эти новые производные таблицы являются временными, но в отличие от неявно определенных производных таблиц они напрямую управляются пользователем. В любом случае физическая таблица, созданная при помощи этих расширений, не существует во время компиляции и не создается оператором SQL, ссылающимся на нее. К примеру, таблицы переходов, связанные с триггером, представляют собой неявно определенные таблицы, которые будут содержать копии строк, создаваемые операторами INSERT, UPDATE и DELETE при срабатывании триггера. В теле триггера определяются действия, выполняемые при его переключении, и содержатся ссылки на временные таблицы. Поскольку тело триггера компилируется до выполнения оператора SQL, вызываемого при срабатывании триггера, до момента запуска оператора SQL таблицы переходов просто не существует. Давайте попробуем рассмотреть, каким образом механизм базы данных представляет ссылки на таблицу переходов во время компиляции.
Основная трудность, возникающая при работе с этими расширениями, заключается в адаптации существующих реляционных механизмов и установлении связей между процедурами создания производных таблиц и ссылками на эти таблицы. Эта задача во многом напоминает задачу разрешения ссылок на внешние имена, характерную для современных языков программирования. Триггер компилятора SQL точно так же, как и компилятор языка программирования, должен пометить ссылки в таблице переходов как неразрешенные. Разрешение ссылок происходит в случае срабатывания триггера, при этом в его теле содержится актуальная таблица переходов. Другими словами, связь между процедурой создания таблицы и ссылкой на таблицу устанавливается не статически, а динамически. Соответственно, и таблицы эти называются динамическими (в отличие от обычных производных таблиц).
Процесс связывания ссылки на таблицу с ее физическим содержимым носит название динамического связывания. В данной статье мы хотели бы подробнее остановиться именно на этом процессе. Из вышесказанного можно сделать следующие выводы. Во первых, следует отметить, что основной вопрос, который необходимо решить при организации поддержки различных динамических таблиц — это динамическое связывание. Мы рассмотрим стандартные конструкции, используемые для обработки динамических таблиц на этапе компиляции и выполнения. Основная идея заключается в том, чтобы представить динамические таблицы в виде обобщенных функций, с помощью которых формируются наборы записей. Для каждой динамической таблицы компилятор создает шаблон, в котором содержится информация, известная на этапе компиляции (например, определение колонок). Во вторых, применяемый нами подход практически не оказывает никакого воздействия на существующую технологию этапа выполнения. Мы помещаем большую часть изменений, вносимых на этапе выполнения, в новый функциональный компонент — динамический брокер, отвечающий за динамическое связывание неразрешенных ссылок на таблицы. В третьих, используемая технология почти не отражается на производительности. Динамическое связывание происходит только при первом обращении к динамической таблице (при ее открытии). Основываясь на данном подходе, мы определяем порядок поддержки некоторых новых расширений таблиц (в частности, табличных функций, триггеров, поисковых процедур и временных таблиц) в продукте DB2 Common Server — ранней версии DB2 UDB. Опыт работы с подобными прототипами доказывает простоту, универсальность и эффективность выбранных нами методов.
Поскольку использование динамических таблиц представляет собой относительно новую технологию, для начала кратко остановимся на порядке управления триггерами в некоторых продуктах. В СУБД DB2 UDB тело триггера компилируется как часть оператора SQL, управляющего переключением триггера. В данном случае динамическое связывание отсутствует. Недостаток этого подхода заключается в значительном объеме работ, который требуется для того, чтобы компилятор разобрался в семантике триггеров и в дальнейшем мог предотвратить некорректную оптимизацию. При работе с продуктом DB2 для AS/400 пользователь пишет программу триггера на языке C или COBOL. При срабатывании триггера программе передается указатель на раздел триггера, в котором содержится информация об операторах переключения и о буфере для старой и новой записей. Низкоуровневые интерфейсы прикладных программ (application programming interfaces, API) используются для организации доступа к записям буфера через код программы триггера. Ни один из описанных подходов не применим к другим динамическим таблицам.
Оставшаяся часть статьи посвящена рассмотрению следующих вопросов. Сначала мы обсудим структуру динамических таблиц и проиллюстрируем процесс динамического связывания. Далее будут описаны конструкции, используемые на этапе компиляции, стандартные процедуры обработки динамических таблиц компилятором SQL и расширенная архитектура этапа выпомитесь с тем, какое влияние на процесс динамического связывания оказывают триггеры, поисковые механизмы, расширенные табличные функции и определяемые пользователем временные таблицы.
Динамические таблицы
В данном разделе содержится краткое введение в структуру динамических таблиц и иллюстрируется процесс динамического связывания.
Табличные функции, определяемые пользователем. Табличные функции — это функции, возвращающие набор записей. С их помощью можно не только наиболее универсальным способом (в отличие от использования представлений) создавать новые таблицы из существующих, но и получать доступ к внешним данным (к данным, находящимся в плоских файлах) при помощи тех же механизмов запросов. К примеру, для определения на языке C табличной функции avg_temp, которая ежедневно возвращает информацию о среднесуточной температуре для ряда городов в виде , можно написать следующий оператор DB2 UDB:
CREATE FUNCTION avg_temp () RETURNS TABLE (city VARCHAR (30), date DATE, temp INTEGER) LANGUAGE C ...
Ключевое слово TABLE в операторе RETURNS говорит о том, что функция является табличной. После того, как данная функция определена, она может быть использована в качестве запроса (например, для выдачи средней температуры в Чикаго 13 июля 1959 года):
SELECT temp FROM TABLE
(avg_temp ()) AS adt
WHERE city = ?CHICAGO?
AND date = DATE «1959-07-13»Обратите внимание на то, что таблица avg_temp в операторе SELECT не существует и не доступна базе данных до момента запуска табличной функции на выполнение. Другими словами, компилятор сгенерировал исполняемый план (иногда его называют разделом доступа) для оператора SELECT, который ссылается на несуществующую таблицу.
Таблицы переходов в триггерах. Как уже было сказано ранее, таблица переходов содержит набор строк, который был создан в результате переключения триггера (т.е., вставленные, измененные и удаленные строки). Таблица переходов может занимать все тело триггера и использоваться в качестве основы производной таблицы.
Определим таблицу employees и триггер keep_stat, который срабатывает после внесения в таблицу изменений:
CREATE TABLE employees
(name VARCHAR (30),
salary DECIMAL (9, 2),
dept VARCHAR (5))
CREATE TRIGGER keep_stat
AFTER UPDATE ON employees
REFERENCING NEW_TABLE AS
new
FOR EACH STATEMENT
BEGIN ATOMIC
INSERT INTO stat
SELECT MIN (salary),
AVG (salary),
MAX (salary) FROM new
ENDТело триггера определяется операторами, находящимися внутри блока BEGIN. При срабатывании триггера в таблицу stat заносится строка с информацией о новой минимальной, средней и максимальной зарплате. Данные выбираются из набора строк с обновленными значениями (оператор REFERENCING OLD_TABLE используется для ссылки на строки с первоначальными значениями). При определении триггера оператор UPDATE on employees создает таблицу переходов (в описании триггера указывается, что она будет новой), в которую заносятся измененные строки. В данном случае в новой таблице будет содержаться новая информация о сотрудниках отдела продаж:
UPDATE employees SET salary =
salary * 1.1
WHERE dept = «Sales»Оператор UPDATE отвечает за наполнение информацией таблицы переходов. Триггер срабатывает после выполнения этого оператора. Обратите внимание на то, что таблица переходов, на которую имеется ссылка в операторе INSERT, находящемся в теле триггера, не существует до тех пор, пока не будет выполнен оператор UPDATE. После этого компилятор должен сгенерировать исполняемый план для оператора INSERT, в котором имеется ссылка на несуществующую таблицу.
Поиск по таблице. В некоторых операторах SQL ключевое слово TABLE относится к данным встроенного типа. В этом случае поисковые средства связывают таблицы (в частности, если они используются для определения колонок, появляющихся в результате выполнения запроса) с главными переменными. Поисковые средства представляют собой «дескрипторы», которые обеспечивают доступ приложений к производным таблицам при помощи многократного выполнения операций языка SQL в пределах одной транзакции. Главная переменная, характеризующая тип поискового средства, описывается оператором прикладной программы DECLARE SECTION:
EXEC SQL BEGIN DECLARE SECTION;
SQL TYPE IS TABLE (name VARCHAR (30), salary DECIMAL (9, 2))
AS LOCATOR emp_loc;
SQL TYPE IS TABLE LIKE
depart ments AS LOCATOR dept_loc;
EXEC SQL END DECLARE SECTION;Главная переменная типа поискового средства должна быть объявлена с указанием полной информации о структуре таблицы (т.е., с описанием списка имен колонок и пар типов данных) или со ссылкой на имя таблицы (в предыдущем примере — departments), на основании которого можно получить исчерпывающие сведения о структуре таблицы. После того, как главная переменная поискового механизма определена, она может применяться и в других операторах SQL, в которых используются таблицы. В следующем примере главной переменной emp_loc ставится в соответствие элемент типа TABLE, содержащий имена сотрудников отдела продаж, зарплата которых превышает 50 тыс. долл:
EXEC SQL SET :emp_loc = (SELECT
(SELECT *
FROM TABLE (d.emps)
WHERE salary>50000)
FROM departments AS d
WHERE name = «Sales»);Обратите внимание на то, что в действительности оператор, приведенный в примере, не пересылает данные обо всех сотрудниках отдела продаж в главную программу. Вместо этого он создает производную таблицу и определяет уникальное значение, которое однозначно указывает на производную таблицу на сервере и присваивает его главной переменной emp_loc. Поскольку переменная emp_lock однозначно указывает на производную таблицу, она может использоваться в том случае, если в результате исполнения оператора SQL должна получиться таблица. Например, следующий запрос возвращает среднюю зарплату сотрудников, которая была помещена в таблицу, описываемую переменной emp-lock:
EXEC SQL SELECT AVG (salary) FROM TABLE (:emp_loc);
Временные таблицы и другие конструкции, определяемые пользователем. Определяемые пользователем временные таблицы — это таблицы, которые создаются и поддерживаются механизмом SQL для прикладных программ, подключаемых к СУБД. Они определяются как обычные базовые таблицы, но не содержат никакой информации до запуска конкретного приложения. На начальном этапе приложение должно установить ссылку на созданную им временную таблицу и сделать ее доступной для проведения различных действий. Помимо временных таблиц язык SQL имеет и другие конструкции, поддерживающие явное задание производных таблиц, содержимое которых не определено до этапа выполнения. К этим конструкциям относятся именованные табличные выражения и результирующие наборы, возвращаемые хранимыми процедурами.
Очень важным является то, что во всех этих конструкциях структура явно определенных производных таблиц известна механизму SQL (с момента определения их в качестве обычных таблиц), однако в них не содержится никакой информации до запуска прикладной программы или оператора SQL, ссылающегося на данные элементы.
Представление расширенных табличных объектов
Во введении мы кратко коснулись стандартного способа представления всех видов динамических таблиц (в качестве функций, создающих таблицы на этапе выполнения). В данном разделе мы постараемся описать, каким образом неразрешенные динамические таблицы можно создать путем расширения существующих табличных объектов, а в дальнейшем рассмотрим вопрос их использования для динамического связывания. Для в (например, сортировки или объединения) к входящим таблицам. Основная структура данных, связанная со всеми табличными операциями, представляет собой табличный объект (table object, TAOB). Каждая ссылка на таблицу имеет свой собственный табличный объект.
Текущие табличные объекты. Табличный объект — это дескриптор, служащий для определения ссылки на таблицу во всех табличных операциях. Некоторые атрибуты TAOB известны и определяются на этапе компиляции в виде констант (выбираемых из системного каталога или оператора SQL). В качестве примера можно привести тип и идентификатор (ID) базовой таблицы, область буфера активных колонок, предикаты связанных аргументов поиска и т.д. Некоторые другие атрибуты табличного объекта используются для контроля за состоянием таблицы на этапе выполнения (например, идентификатор текущей записи, количество выбранных записей, статус последней операции и др.). На рис.1 отображены наиболее важные атрибуты TAOB.
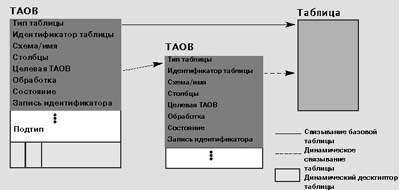
|
| Рис. 1. Архитектура TAOB |
Тип таблицы задается при помощи первого атрибута. Возможные значения атрибута делятся на временные и базовые. Идентификатор таблицы — это атрибут, позволяющий однозначно определить каждую конкретную таблицу. Для базовых таблиц идентификатор известен на этапе компиляции и устанавливается компилятором. Идентификатор временной таблицы определяется на этапе выполнения уже после того, как таблица создана. Как показано на рис.1, в табличном объекте этапа компиляции содержится указатель на целевой TAOB. Идентификатор целевого табличного объекта указывает на актуальную таблицу. После создания временной таблицы все операции обращаются к идентификатору посредством косвенного указателя, содержащегося в ее собственном табличном объекте.
Многие табличные операции базируются на сканировании либо отношений, либо индексов. Для поддержки текущего состояния сканирования компонент управления данными создает при открытии целевой таблицы специальную структуру. Эта управляющая структура используется для контроля за информацией о позиции для конкретного уровня доступа к данным, а дескриптор служит для организации доступа к целевой таблице при выполнении операций, связанных со сканированием. В поле статуса хранятся сведения о текущем состоянии табличной операции (например, открыта, закрыта, обнаружен конец файла). Поле record_id содержит идентификатор последней выбранной записи.
Новые атрибуты для динамических таблиц. Рассмотрим поля табличного объекта, предназначенные для поддержки динамических таблиц. В отличие от обычной динамической таблице нужна дополнительная информация, которая заносится в TAOB на этапе компиляции (требуемые данные выбираются из оператора SQL или системного каталога). Эти сведения нужны для разрешения «неопределенности», возникающей на этапе выполнения. Характер данной информации варьируется в зависимости от конкретного типа динамических таблиц:
- Табличные функции: дескриптор вызова функции (function invocation descriptor, UFOB) нужен для расширенных табличных функций; идентификатор используется внутренними табличными функциями.
- Таблицы переходов: в данном случае необходимо знать тип таблицы переходов (старая или новая), имя связанного триггера и имя связанной базовой таблицы.
- Поисковый механизм: объект, в котором содержится определение колонок для организации поиска в таблице.
- Временные таблицы, определяемые пользователем: требуется информация о типе временной таблицы (глобальная, локальная или декларированная локальная) и имени связанной таблицы.
Итак, мы определили новые типы таблиц: табличная функция, таблица переходов, механизм табличного поиска и временная таблица, определенная пользователем. Дескриптор динамической таблицы добавляется к табличному объекту в качестве общего управляющего блока для динамических таблиц. Для базовых и временных таблиц используется пустой набор. Дескриптор динамической таблицы содержит следующую информацию:
- Подтип: поле подтипа является расширением типа таблицы. Для табличных функций он может принимать значения внутреннего или внешнего. Для таблиц переходов подтип может быть новым или старым. Для таблиц переходов — глобальным, локальным или декларированным локальным.
- Схема и имя таблицы: в данном параметре содержатся схема и имя таблицы, с которыми связана основная динамическая таблица. Он применяется только для таблиц переходов и временных таблиц, определяемых пользователем.
- Схема и имя триггера: для таблицы переходов данный атрибут описывает схему и имя для объявленного триггера.
- Объект определения колонок: данный атрибут указывает на определение колонки для механизма поиска в таблице.
- Объект внешних функций: этот атрибут содержит информацию о функциональном дескрипторе UFOB, которая нужна для вызова внешней функции.
В следующем разделе мы покажем, каким образом описанный здесь табличный объект используется на этапе выполнения для динамического связывания актуальных таблиц и неразрешенных табличных ссылок.
Расширенная среда этапа выполнения
Типичный механизм реляционной базы данных этапа выполнения содержит компонент реляционной службы данных (relational data service, RDS), необходимый для логического (реляционного) представления БД, и компонент службы управления данными (data manager service, DMS) для физического представления БД. Общая архитектура представлена на рис.2. Она включает новый компонент — брокер динамической таблицы, используемый для поддержки динамических таблиц.
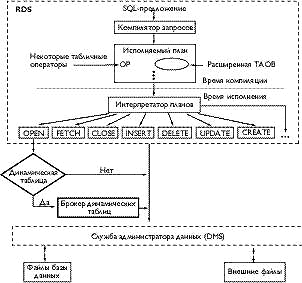
|
| Рис. 2. Архитектура типичной реляционной СУБД. Брокер динамических таблиц вводится для динамического связывания при открытии таблицы. После разрешения табличнхы ссылок все операции с таблицами выполняются как раньше |
Как показано на рисунке, запрос на получение доступа к базовой таблице и обычным производным таблицам выполняется стандартным способом. Интерпретатор вызывает соответствующую процедуру доступа к реляционным данным, которая в свою очередь обращается к процедуре низкоуровневого доступа к данным DMS. Поскольку TAOB предметной таблицы уже «связан» с идентификатором соответствующей физической таблицы (для базовых таблиц это происходит на этапе компиляции, а для обычных производных таблиц — на этапе выполнения), никаких дополнительных усилий в данном случае прилагать не потребуется.
Организация доступа к динамическим таблицам осложняется тем, что они создаются во внешней среде при выполнении оператора SQL, в то время как обычные производные таблицы создаются внутри системы. Компонент брокера динамических таблиц служит для выполнения процедуры динамического связывания. В данном разделе вы познакомитесь с кратким обзором существующей среды выполнения программ, а также с тем, каким образом компонент брокера интегрируется с имеющимися исполняемыми процедурами.
Существующая среда выполнения программ. Прежде чем получить доступ к таблицам (как базовым, так и производным), необходимо создать их. Базовая таблица должна быть создана до компиляции обращающихся к ней операторов SQL. Идентификатор таблицы известен априори и хранится в табличном объекте среди операций, осуществляющих доступ к таблице. Производные таблицы создаются на основе уже существующих за счет выполнения оператора SQL. Обычные производные таблицы сначала необходимо создать (присвоив им соответствующий идентификатор). Для получения доступа нужно выполнить оператор, который определяет (неявно) производную таблицу. Эти производные таблицы в общем случае удаляются после выполнения оператора SQL.
Прежде чем проводить с таблицей какие-либо манипуляции, необходимо открыть ее для инициализации соответствующей рабочей области. Исполняемая процедура открытия таблицы использует табличный идентификатор и вызывает низкоуровневую процедуру DMS. После открытия таблицы ее кортежи становятся доступными каждой исполняемой процедуре. После завершения необходимых манипуляций вызывается процедура закрытия таблицы, освобождающая рабочую область.
Брокер динамических таблиц. Поскольку все операции над таблицей возможны только после ее открытия, динамическую связь удобно устанавливать непосредственно в процессе открытия. Для этого диспетчер связи добавляетсой таблицей управление передается брокеру, который разрешает неопределенные ссылки на динамическую таблицу и связанную с ней информацию. После разрешения ссылок все процедуры выполняются точно так же, как если бы основная таблица была обычной производной таблицей.
Динамическое связывание выполняется в два этапа: на первом ищется целевая таблица, на втором полученная информация сохраняется в текущем TAOB для дальнейшего использования. Хотя детали процесса просмотра таблицы и установки атрибутов варьируются от одной динамической таблицы к другой, фундаментальный механизм остается неизменным. Логику работы брокера динамических таблиц можно проследить, изучив следующий сегмент псевдокода, написанного на C-подобном языке.
switch access_taob.type
{
case TRANSITION_TABLE:
link_transition_table(access_taob);
break;
case TABLE_FUNCTION:
link_table_function(access_taob);
break;
case TABLE_LOCATOR:
link_table_locator(access_taob);
break;
case USER_DEFINED_TEMPORARY_TABLE:
link_user_defined_tempo
rary_table(access_taob);
break;
}Функции link_transition_table(), link_table_function(), link_table_locator() и link_user_defined_temporary_table() служат для организации связей между динамическими таблицами. В следующем разделе описывается реализация данных процедур.
Поддержка динамических таблиц
Ознакомившись с данным разделом, вы узнаете о том, как расширенная архитектура этапа выполнения поддерживает динамические таблицы.
Таблицы переходов в триггерах. Таблицы переходов получают информацию о состоянии обрабатываемых строк после выполнения над таблицей операции триггера SQL. Если говорить более конкретно, то старая таблица переходов содержит данные об обрабатываемых строках до выполнения операций UPDATE и DELETE, а в новую таблицу переходов помещаются значения строк, к которым относятся операции UPDATE и INSERT. При выполнении триггерной операции (INSERT, DELETE или UPDATE) таблицы переходов создаются на основе значения поля подтипа таблицы переходов (старого или нового), триггерной операции и текущего содержимого таблицы.
Хотелось бы отметить еще две важные детали. Во-первых, таблица переходов создается в момент выполнения триггерного оператора. Поэтому TAOB должен быть записан в специальной области процедуры брокера динамической таблицы link_transition_table(), предназначенной для разрешения ссылок на таблицу переходов. Эта задача возлагается на исполняемый план, который связан с телом триггера. Во-вторых, активизация триггера может быть вложенной, поскольку некоторые операторы SQL, находящиеся в теле триггера, способны вызывать другие (или тот же самый) триггеры. Структура данных для TAOB таблиц переходов представляет собой стек, в котором табличные объекты нижнего уровня обладают более высоким приоритетом (точно так же вызов процедур реализован и в обычных языках программирования). Табличные объекты помещаются в стек таблицы переходов в точке входа в теле триггера, а затем извлекаются из тела триггера.
Брокер динамической таблицы ищет в стеке таблиц переходов точку входа в актуальную таблицу и записывает полученный идентификатор таблицы в TAOB ссылки на текущую таблицу. Чтобы проиллюстрировать вышесказанное, приведем псевдокод основной логики процедуры брокера динамической таблицы link_transition_table():
link_transition_table(access_taob)
{
TAOB actual_taob;
/* (1) Просмотр стека таблицы
переходов */
if (access_taob[arrow]dt_cb.subtype == NEW)
actual_taob = tran_tbl_stack[top].new;
else
actual_taob
tran_tbl_stack[top].old;
/* (2) Копирование специальных
атрибутов */
access_taob[arrow]type = actual_taob[arrow]type;
access_taob[arrow]id = actual_taob[arrow]id;
/* (3) Копирование общих атрибу
тов, зависящих от
конкретной реализации */
odify_other_attributes(access_taob, actual_taob);
}Для того, чтобы продемонстрировать процедуру динамического связывания таблиц переходов на этапе выполнения, приведем следующий пример. Пусть t1, t2 и t3 — таблицы, имеющие колонки c1 и c2, а триггеры trig1 и trig2 отражают изменения, происходящие после выполнения различных операторов над таблицами t1 и t2 соответственно. Триггер trig1 обрабатывает только новую таблицу переходов nt, а trig2 выполняет операции как над новой таблицей переходов (nt), так и над старой (ot).
CREATE TRIGGER trig1 AFTER UPDATE ON t1
REFERENCING NEW_TABLE AS nt
FOR EACH STATEMENT MODE DB2SQL
BEGIN
...
CASE (SELECT COUNT(*) FROM nt)
WHEN 2:
UPDATE t2 SET c2 = c2 * c2 WHERE c2<0;
END CASE;
...
END
CREATE TRIGGER trig2 AFTER UPDATE ON t2
REFERENCING NEW_TABLE AS nt
OLD_TABLE AS ot
FOR EACH STATEMENT MODE DB2SQL
BEGIN
...
INSERT INTO t3 SELECT nt.c1, ot.c2 FROM nt, ot;
...
ENDОперации обновления в таблице t1 переключают триггер trig1, который в свою очередь приводит к срабатыванию триггера trig2:
UPDATE t1 SET c2 = -c2 WHERE c2<0
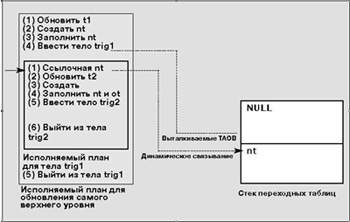
|
| Рис. 3. Конфигурация времени исполнения и динамическое связывание после введения trig 1 |
Конфигурация среды исполнения и характер процесса динамического связывания при срабатывании триггера trig1 отражены на рис.3. При обновлении таблицы t1 создается таблица переходов nt, в которой хранится информация об обрабатываемых строках. Перед вводом триггера trig1 табличный объект nt заносится в стек таблицы переходов (при этом старая таблица переходов не генерируется и обнуляется), после чего динамическое связывание выполняется при получении первой ссылки на nt в теле триггера. На рис.4 приводится конфигурация среды при срабатывании триггера trig2.
Временные таблицы, определяемые пользователем. Глобальная временная таблица представляет собой определяемую пользователем временную таблицу, с которой в течение сеанса соединения с базой данных можно выполнять любые операторы SQL. Она является «глобальной» в том смысле, что все изменения отражаются немедленно, а операции выполняются последовательно в одном сеансе связи с базой данных.
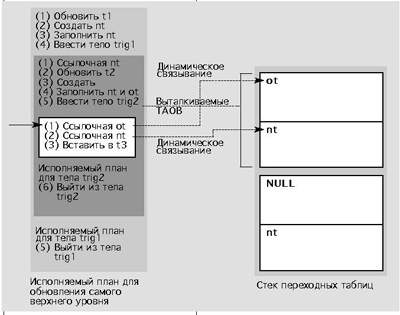
|
| Рис. 4. Конфигурация времени исполнения и динамическое связывание после введения trig 2 |
В то же время таблица считается «временной», поскольку ее содержание доступно только во время соединения с базой данных; физическое содержимое глобальной временной таблицы удаляется в конце сеанса связи. Другая важная особенность глобальных временных таблиц заключается в том, что их нельзя совместно использовать в различных сеансах связи с БД. Все это лучше продемонстрировать на примере. Допустим, gtt — глобальная временная таблица, а t1 и t2 — базовые таблицы с теми же колонками, что и в gtt. При установлении соединений с базой данных (последовательных или чередующихся), таблицы t1 и t2 заполняются строками так, как показано на рис.5.
При открытии глобальной временной таблицы для выполнения оператора SQL процедура брокера динамической таблицы link_user_ defined_temporary_table ищет актуальную таблицу в глобальной таблице символов, расположенной в рабочей области соединения.

|
| Рис. 5. Глобальные временные таблицы |
Если нужная информация найдена, TAOB актуальной таблицы используется для выполнения динамического связывания таблиц. Если не найдена, объект актуальной таблицы создается и вводится в символьную таблицу для последующего поиска. С помощью TAOB вновь созданного объекта таблицы устанавливается динамическая связь, необходимая для получения доступа к основной таблице. Процесс связывания таблиц аналогичен определению ссылок на таблицу переходов и описывается фрагментом псевдокода процедуры брокера динамической таблицы link_user_ defined_temporary_table():
link_user_defined_temporary_tableccess_taob[arrow]id = actual_taob[arrow]id;
/* 4. Копирование общих
атрибутов, зависящих от
конкретной реализации. */
modify_other_attributes
(access_taob, actual_taob);
}
break;
case LOCAL:
{
...
}
}
}В конце сенса связи с базой данных механизм базы данных сканирует таблицу глобальных символов и удаляет все объекты таблиц, созданные для получения доступа к глобальной временной таблице в ходе данного сеанса.
Локальные временные таблицы и декларированные локальные временные таблицы аналогичны глобальным временным таблицам. Единственным различием является область существования. Локальные временные таблицы совместно используются во всех операциях SQL, содержащихся в одном и том же модуле, а декларированные локальные временные таблицы помещаются в основной блок PSM (Persistent Stored Module4). Поэтому структура данных и логика разрешения таблиц для глобальных временных таблиц применима и к локальным и к декларированным локальным временным таблицам. Но поскольку область действия таблицы символов ограничена, логика инициализации и очистки, приведенная выше для глобальных временных таблиц, должна соответствовать зоне действия всех основных операторов SQL.
Табличные функции. Табличные функции могут быть внутренними или внешними. Область внутренних табличных функций состоит из последовательности операторов SQL. В отличие от этого внешние табличные функции разрабатываются средствами базовых языков: C, C++, Java, Visual Basic и т.д.
Для функций внутренних таблиц физические таблицы представляют собой исполняемый план для тела табличной функции. Поэтому процедура брокера link_table_function вызывает диспетчер плана механизма базы данных. Нужный план, обозначаемый соответствующим идентификатором, хранится в дескрипторе динамической таблицы базового TAOB. Загружаемый в память дескриптор плана также записывается в TAOB для последующего вызова табличных функций.
Внешние табличные функции механизм базы данных рассматривает как «табличные процедуры черного ящика». Поэтому объект физической таблицы представляет собой точку входа во внешнюю функцию, которая реализует табличную функцию. Чтобы получить точку входа во внешнюю функцию, процедура link_table_function динамически загружает нужную библиотеку в адресное пространство механизма базы данных. Загружаемая в память таблица символов библиотеки ищет нужную внешнюю функцию. После определения точки входа во внешнюю функцию она записывается в дескриптор динамической таблицы базового TAOB для последующего вызова функций этой таблицы.
Логика процедуры link_table_function иллюстрируется следующим псевдокодом:
link_table_function(access_taob)
{
TAOB actual_taob;
switch (access_taob[arrow]dt_cb.subtype)
case INTERNAL_TF:
/* Внутренняя табличная
функция: план доступа к
загрузке. */
access_taob[arrow]
dt_cb.plan_cb_ptr =
load_plan(access_taob [arrow]dt_cb.planID);
break;
case EXTERNAL_TF:
/* Внешняя табличная
функция: библиотека
загрузки и разрешающая точка входа. */
library_handle =
dynamicLoad
(access_taob[arrow]dt_cb.libPath);
access_taob[arrow]dt_cb.function_entry = resolveEntry(library_handle,
access_taob[arrow]dt_cb.functionName);
break;
}В настоящее время табличные функции СУБД DB2 UDB поддерживают только операции чтения (т.е., открытие, выборку и закрытие).
Механизм поиска в таблице. Таблица поиска служит для контроля за поисковой процедурой, созданной в данной транзакции. Таблица поиска отображает идентификатор поискового средства на указатель TAOB актуальной связанной таблицы. В начале транзакции в поисковой таблице не содержится никакой информации. В процессе выполнения новые точки входа в таблицу создаются всякий раз при связывании поисковых таблиц с главной переменной (например, в операторе SET). В конце транзакции поисковая таблица очищается, а все поисковые механизмы освобождаются.
Когда в операторе SQL происходит обращение к средству поиска в таблице процесс динамического связывания выполняется в два этапа. Во-первых, идентификатор поискового средства, хранящийся в главной переменной, связывается и записывается в дескриптор динамической таблицы TAOB основного доступа. Связывание происходит при выполнении плана оператора SQL. В приводимом ниже псевдокоде userObject — идентификатор поискового средства, выбираемый из главной переменной, а sqlObject — табличный объект доступа:
bind_in(type, sqlObject, userObject)
{
switch (type)
{
case TABLE_LOCATOR:
sqlObject[arrow]dt_cb.
locatorID = userObject;
break;
case...
}
}При открытии связанной таблицы идентификатор поискового средства, установленный ранее в табличном объекте доступа, используется для просмотра таблицы поиска и выборки актуального TAOB. После этого атрибуты текущего TAOB инициализируются в соответствии с параметрами актуального TAOB:
link_table_locator(access_taob)
{
TAOB actual_taob;
/* 1. Просмотр глобальной
символьной таблицы. */
actual_taob = find_table_locator
(access_taob[arrow]dt_cb.locatorID);
/* 2. Копирование специальных
атрибутов. */
access_taob[arrow]type = actual_taob[arrow]type;
access_taob[arrow]id =
actual_taob[arrow]id;
/* 3. Копирование общих
атрибутов, зависящих от
конкретной реализации. */
modify_other_attributes(
access_taob, actual_taob);
}Заключение
Традиционная концепция таблиц в реляционных базах данных отражена в языке SQL и в ряде коммерческих баз данных. В отличие от традиционных таблиц динамические таблицы существуют только на этапе выполнения запроса и напрямую управляются пользователем. Компилятор запросов генерирует неразрешенные табличные ссылки и для их разрешения использует механизм связывания этапа выполнения.
Мы описали общие принципы поддержки динамических таблиц в существующих компиляторах запросов. Все динамические таблицы стандартным образом обслуживаются компилятором, а функции брокера добавляются в исполняемую среду для обеспечения динамического связывания. Мы описали расширения компилятора и исполняемой среды для продукта DB2 Common Server и пояснили, каким образом общие конструкции могут использоваться для поддержки таблиц переходов, табличных функций, временных таблиц, определенных пользователем и средств поиска в таблицах. Кроме того, на базе этих конструкций мы создали прототип. Успешное функционирование этого прототипа оправдало наши ожидания и подтвердило простоту и эффективность выбранного подхода.
Дальнейшие исследования будут вестись в следующих направлениях:
- Абстрактные таблицы. Недавно появившиеся абстрактные таблицы представляют собой удобный способ определения всех табличных операций самим пользователем. Можно задавать операции открытия, выборки, закрытия, вставки, обновления, удаления и даже отката и фиксации транзакций. Не думаю, что подобное обобщение окажет какое-либо воздействие на реальные конструкции, но тем не менее оно позволяет поближе познакомиться со спецификациями языка.
- Технология массового параллелизма: Пятая версия продукта DB2 UDB поддерживает массово-параллельную обработку (MPP), при которой таблицы разбиваются на несколько параллельно обслуживаемых узлов. Копия одного и того же исполняемого плана запускается сразу же на нескольких узлах вместе с табличными очередями на отправку потоков данных. Результирующая таблица каждого узла проходит через очереди таблиц на «координирующий» узел, где происходит ее окончательная обработка и привязка к клиенту. В дальнейшем мы хотели бы усовершенствовать наши конструкции и адаптировать их к работе в подобной параллельной среде.
