Шаг за шагом
NetMaker. Предварительный анализ и подготовка данных.
BrainMaker. Обучение и тестирование нейросети, получение результатов
О нейросетевых технологиях и об их использовании в приложениях сейчас пишут довольно много. С одной стороны, это, конечно, помогает оценить перспективность этих технологий, но в то же время обилие теоретических материалов может вызвать у читателя ощущение сложности их конкретного применения для решения насущных, обычно не очень масштабных задач. В нашей статье рассматривается конкретный пример создания нейросети для финансового прогнозирования на основе одной из доступных сегодня программ, использующих методы нейрокомпьютинга BrainMaker. На простых жизненных ситуациях мы хотим показать последовательность конкретных шагов создания нейросети, предварительной обработки и анализа входных данных.
| BrainMaker популярный нейросетевой пакет, разработанный компанией California Scietific Software. Пакет состоит из нескольких модулей, среди которых основными являются сам BrainMaker, а также модуль предварительной подготовки и анализа данных NetMaker | ||
Про нейросети сегодня говорят очень много, как правило, общими фразами и часто слишком восторженно. Тем не менее, многие технические аналитики на практике рисуют графики, читают прессу и довольствуются естественной нейросетью в своей голове для сведения всех input в один output купить или продать. Кроме того, они, как правило, не являются специалистами по нейросетевым технологиям, а в научных статьях не обюясняется, как, например, взять конкретный пакет и сделать своими руками что-нибудь простое и полезное.
Давайте рассмотрим пример создания нейросети для финансового прогнозирования, разобрав попутно последовательность и технику использования средств пакета BrainMaker 3.1 .
Шаг за шагом
Первый шаг при разработке нейросети определить, что же она должна делать. Этот вопрос важнее, чем кажется на первый взгляд. Предположим, наша нейросеть предсказывает наступление какого-либо события с погрешностью 20%. Сегодня акции стоят 95 долл., а завтра будут стоить 100. Что может быть спрогнозировано с большей точностью абсолютная цена акций, изменение цены или направление движения рынка? В первом случае прогноз будет в пределах 80-120 долл. При прогнозе изменения цены результат будет находиться в интервале 4-6 долл., что соответствует абсолютной цене 99-101 долл.. Ну, а предугадать направление движения рынка вообще можно безошибочно. Таким образом, результат зависит уже от того, как сформулирована цель разработки нейросети.
В нашем примере нейросеть разворачивается с целью прогнозирования изменения цен на акции некоторой компании Bart-Davis-100 (BD100). Для наглядности применения аналитических средств будем использовать специально подобранные данные. Файлы и инструкции, необходимые для воспроизведения примера на своем компьютере, можно взять на сервере . Для практического использования, естественно, нужно строить нейросеть на реальных, а не на абстрактных данных.
Затем необходимо определить состав исходных данных (второй шаг) и собрать их (третий шаг). Исходный файл представляет собой текстовую таблицу (185 строк), в которой находятся упорядоченные по строкам и столбцам технические индикаторы, индексы и цены (Таблица 1).
| Таблица 1. | |||||||||
| day | BD100 | price1 | price2 | index1D | index2D | line | streng | utilD | transpD |
| 1 | 2877 | 38.77 | 46.77 | 14.68 | -5.4 | 114.37 | 97.62 | 26.22 | 3.23 |
| 2 | 2789 | 39.07 | 46.88 | 20.69 | -3.55 | 126.19 | 91.92 | 26.84 | 2.6 |
| 3 | 2622 | 39.47 | 47.11 | 23.66 | 0.15 | 140.34 | 99.76 | 28.64 | 2.92 |
Каждой строке соответствуют данные одного дня. В столбцах, обозначенных day, BD100, price1, price2, index1D, index2D, line, streng, utilD, transpD, содержатся данные одного типа.
Первый столбец (day) порядковый номер дня, выполняет чисто информативные функции.
Столбец BD100 содержит значения BD100, которые одновременно являются как входными данными, так и результатом работы нейросети прогнозом. Поэтому позже нам придется добавить еще один столбец, содержащий будущие известные значения BD100, на которых мы сможем обучать нейросеть.
Остальные величины в данный момент не имеют значения. На практике это могут быть цены на сырьевые товары (нефть, золото) на мировом рынке, значения фондовых индексов, отражающих движение цен на биржах (Dow-Jones, Nikkei и др.), индикаторы технического анализа и т.д.
На четвертом шаге производится анализ и предварительная обработка данных. Эта часть работы выполняется в программе NetMaker.
Пятый, шестой и седьмой шаги обучение, тестирование и использование нейросети будут сделаны уже в самом пакете BrainMaker.
NetMaker. Предварительный анализ и подготовка данных.
Построим график изменения BD100 (рис.1). Значение BD100, как мы видим, сильно колеблется, но при этом общее движение цены (тренд) направлено вверх.
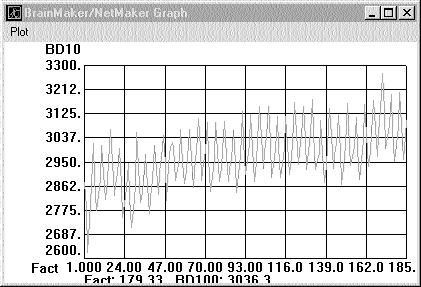
Рис. 1.
Чтобы прогноз был более точным, имеет смысл использовать не абсолютные значения BD100, а только их изменения по сравнению с предыдущим днем. То же относится и к величинам price1, price2. Итак, добавим три новых столбца BD100D, price1D, price2D с приращениями абсолютных значений. Поскольку данные в столбцах с изменениями цен получаются в результате вычитания значений предыдущего дня из значений текущего, первая строка будет содержать некорректные значения. Поэтому в дальнейшем мы ее удалим. Значения в столбцах index1D, index2D, utilD, transpD уже записаны в виде приращений.
Для анализа взаимосвязей между входными данными и значениями BD100, которые мы собираемся прогнозировать, можно использовать Data Correlator. Рассмотрим взаимосвязь между BD100 и index1D, построив, с помощью Data Correlator, следующий график (рис.2).
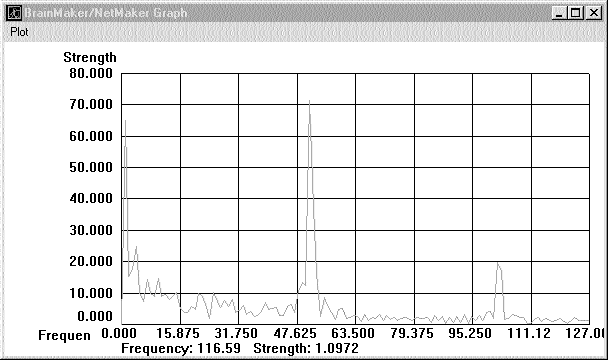
Рис. 2.
На горизонтальной оси показано время, причем единица времени соответствует одной строке из входной таблицы (в нашем случае это один день). Ноль делит горизонтальную ось на две части будущее и прошедшее время относительно BD100. В левой части показано прошедшее, а в правой будущее время.
На вертикальной оси представлена степень корреляции или взаимосвязи BD100 и index1D. Положительная корреляция означает, что если значения в первом столбце увеличиваются, то растут значения и во втором столбце. И наоборот, если значения в первом столбце уменьшаются, то уменьшаются значения и во втором столбце. Отрицательная корреляция означает, что если значения в первом столбце увеличиваются, то значения во втором столбце уменьшаются. И наоборот, если значения в первом столбце уменьшаются, то увеличиваются значения во втором столбце. Степень корреляции может изменяться от -1 до 1. Абсолютное значение, равное 1, означает, что изменения данных величин в точности соответствуют друг другу. Насколько существенна корреляция с абсолютным значением меньше 1 (0.1, 0.3, 0.6), однозначно сказать нельзя, и лучше считать, что эта оценка является субюективным мнением аналитика и зависит от ряда других обстоятельств.
Теперь давайте проанализируем полученный график. Обратите внимание на пик, расположенный немного левее нулевого значения на горизонтальной оси. Временное смещение (лаг) равно -1, а степень корреляции около 0.25. Нулевой лаг означает, что изменения значений в первом и втором столбцах происходят одновременно. На данном графике отрицательный лаг означает, что сначала происходит изменение значений index1D, а затем, через промежуток времени, равный лагу, изменяются значения BD100.
Положительный лаг означает, что сначала происходит изменение BD100, а затем, через промежуток времени, равный лагу, изменяются значения index1D. Таким образом, нас больше всего интересует сильная корреляция с отрицательным лагом, при которой изменения входного параметра могут повлечь за собой изменение прогнозируемой величины через какое-то время. Следовательно, если изменения index1D предшествуют изменению BD100, можно использовать значения index1D для предсказания значений BD100 на один день вперед. Поэтому добавим в таблицу столбец, в котором содержатся вчерашние значения index1D и назовем его ind-1.
Попробуем выявить присущие данному рынку циклы, что позволит установить оптимальную дальность прогноза равной одному циклу. Для этого воспользуемся инструментом Cyclic Analysis, с помощью которого получаем график, изображенный на рис.3.
На горизонтальной оси показана частота появления цикла, на вертикальной его сила. Левый пик с частотой, равной 1 это цикл, соответствующий общему движению рынка. Нам же надо найти самый короткий, ярко выраженный цикл. Этому циклу соответствует другой пик с частотой 51. Чтобы разглядеть его получше, можно изменить масштаб графика. Определим длину этого цикла. Общее количество дней 185, частота 51. Следовательно, длина цикла: 185/51 = приблизительно 4 дня.
Для уменьшения случайного шума сгладим BD100D с помощью скользящего среднего (Moving Average). Для сглаживания рекомендуется использовать интервал, равный половине цикла. В нашем случае это два дня. Новую колонку назовем Bdavg2 и запишем в нее значения скользящего среднего.
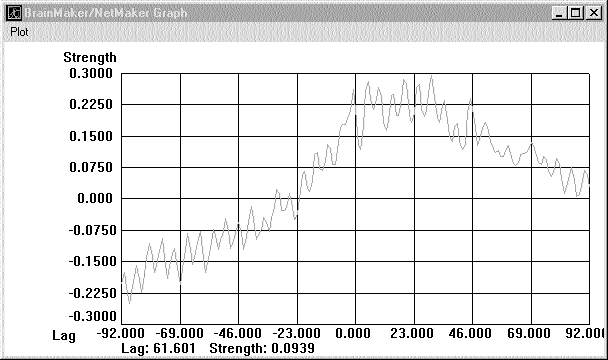
Рис. 3.
Теперь самое время поговорить о том, как нейросеть «видит» входные данные. К сожалению, нельзя просто задать столбец с данными за понедельник, вторник и т.д. Нейросеть «видит» только один факт, представленный текущей строкой. Она «не помнит» что было до этого. Поэтому, если вы хотите подать на вход данные за последние сто торговых дней, то в каждой строке должно быть сто полей. И неважно, что в предыдущей строке входного файла они уже есть. Придется указать их еще раз. При этом следует иметь в виду, что с увеличением количества входов растет сама нейросеть, а, соответственно, ее способность к обучению снижается. В то же время, если нейросеть будет «видеть» тренд, она сделает лучший прогноз. Выбор оптимальных данных и их количества не имеет однозначного решения и на практике производится в процессе настройки нейросети.
Так как в нашем примере цикл составляет четыре дня, то для информирования нейросети о тренде мы будем использовать текущие значения входного параметра и значения четырехдневной давности. Текущие значения уже есть, следовательно, надо создать столбцы с данными за четыре дня назад для всех входных столбцов, кроме ind-1. Путем смещения значений в столбцах BD100D, price1D, price2D, index1D, index2D, line, streng, utilD, transpD на 4 строки вниз получаем новые столбцы со значениями четырехдневной давности. Метки новых столбцов: BD-4, pric1-4, pric2-4, ind1-4, ind2-4, line-4, stren-4, util-4, tran-4 соответственно.
При обучении нейросети в каждой строке входного набора данных (факте) следует указать заранее известное значение (pattern), которое должна предсказывать нейросеть. В процессе обучения нейросеть сравнивает свой ответ с этим эталоном и, в случае ошибки, меняет свою структуру. Этот процесс продолжается до тех пор, пока не будет достигнут требуемый уровень точности. Для этих целей сформируем столбец BD+4 с будущими значениями BD100D, т. е. с теми, которые BD100D примет через 4 дня. Это делается путем смещения значений столбца BD100D вверх на 4 строки.
Теперь можно немного привести в порядок наши данные:
- удалим столбцы BD100, price1 и price2 они больше не понадобятся;
- переместим BD+4 в правый крайний столбец.
При формировании столбцов с данными за четыре дня назад был произведен сдвиг на четыре строки вниз. Ранее мы сдвигались на одну строку вниз при создании столбцов BD100D, price1D, price2D. Следовательно, надо удалить первые пять строк, которые не содержат корректных данных. Кроме того, для формирования BD+4 мы перемещались вверх на 4 строки. Поэтому нужно удалить еще четыре нижних строки. В результате всех этих операций осталось 176 фактов из 185. Иначе говоря, на этапе подготовки данных было потеряно около 5% входных данных. Эти потери следует учитывать при планировании количества данных в процессе развертывания нейросети.
Теперь следует указать назначение каждой колонки полученной таблицы:
комментарии (Annote) колонка day; вход (Input) колонки index1D,
index2D, line, streng, utilD, transpD, BD100D, price1D, price2D, Bdavg2, ind-1, BD-4, pric1-4, pric2-4, ind1-4, ind2-4, line-4, tran-4; образец для обучения (Pattern) колонка stren-4, util-4, BD+4.
Итак, предварительная обработка данных закончена и можно создать файлы для программы BrainMaker. Формируются три файла: описание нейросети, данные для обучения и данные для тестирования нейросети.
BrainMaker. Обучение и тестирование нейросети, получение результатов
Для обучения надо запустить BrainMaker и загрузить файл с описанием нейросети. При этом ссылки на файлы с данными для обучения и тестирования будут сделаны автоматически. При обучении сети используется 158 фактов из 176, т. е. 10% или 18 фактов зарезервированы для тестирования при формировании файлов в NetMaker.
Предсказывать какие-либо изменения на финансовых рынках достаточно сложно, поэтому зададим требуемую точность предсказания равной 80%. После запуска обучения на экране возникнет картинка, приведенная на рис.4.
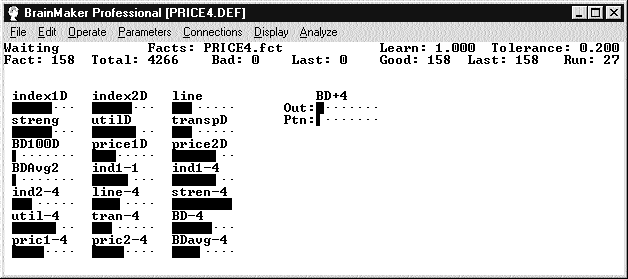
Рис. 4.
Черные горизонтальные столбики (термометры) показывают входные и выходные значения. Их использование облегчает наблюдение за быстро меняющимися значениями. Обратите внимание, что BD+4 соответствуют два термометра: Out показывает значение, сгенерированное нейросетью, а Ptn то значение, которое должно быть предсказано.
Первая строка с данными под главным меню называется status line. В ней показано, что в текущий момент делает BrainMaker и какие задействованы файлы. Learning rate используется для более точной настройки процесса обучения нейросети.
Tolerance это максимально допустимая величина ошибки во время обучения. Если tolerance = 0, то выходной результат (output), выдаваемый нейросетью, должен абсолютно точно совпадать с образцом для обучения (pattern). В большинстве случаев это нереально, особенно для финансовых приложений, которые считаются наиболее сложными. При tolerance = 0.1 выход нейросети (output) будет рассматриваться как корректный, если он отличается не более чем на 10% от заданного значения (pattern). Если же output будет вне этого интервала, то BrainMaker внесет изменения в структуру нейросети таким образом, чтобы при следующей попытке получить более корректный результат. Как уже говорилось, этот процесс будет продолжаться до тех пор, пока значение ошибки не снизится до установленного параметром tolerance предела.
Строка statistics line содержит информацию о ходе обучения или тестирования нейросети: Fact порядковый номер факта из обучающей или тестирующей последовательности (номер строки в таблице с исходными данными), который обрабатывается в это время; Total общее количество фактов, обработанных на данный момент; Bad количество фактов, для которых был получен некорректный результат в текущем проходе входной последовательности; Last количество фактов, для которых был получен некорректный результат в предыдущем проходе входной последовательности; Good количество фактов, для которых был получен корректный результат в текущем проходе входной последовательности; Last количество фактов, для которых был получен корректный результат в предыдущем проходе входной последовательности; Run общее количество проходов входной последовательности, включая текущий.
В процессе обучения можно наблюдать его динамику (рис.5).
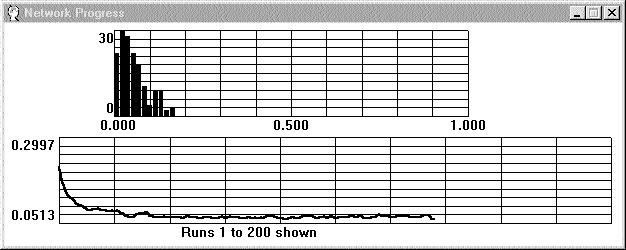
Рис. 5.
Верхний график в виде гистограммы отображает распределение ошибок за один проход обучающей последовательности фактов. На горизонтальной оси показана величина ошибки, а на вертикальной количество ошибок. По мере обучения вертикальные столбики смещаются влево, отражая процесс уменьшения величины ошибок при обработке фактов. Обучение заканчивается, когда не остается ни одного факта, обработанного с ошибкой, величина которой больше установленного нами допустимого уровня 0.2. Наблюдение за графиком поможет определить достижимый уровень ограничения ошибок при разработке нейросети. В нашем случае, например, можно довести этот уровень до 0.125.
Нижний график отображает динамику изменения общей ошибки нейросети в процессе обучения. На горизонтальной оси показан номер прохода обучающей последовательности. На вертикальной оси величина ошибки. Общая ошибка нейросети вычисляется как RMS Error (Root Mean Squared) по следующей формуле:
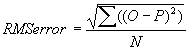 , где O output, P pattern, N количество фактов.
, где O output, P pattern, N количество фактов.
По окончании процесса обучения необходимо проверить качество работы нейросети на данных, которые она еще «не видела». При тестировании нейросети будет происходить обработка фактов и сравнение полученных результатов (output) с образцами (pattern). Ошибки при этом вычисляются, но корректировка структуры нейросети не производится. В строке statistics line отображается результат тестирования Good:15 Bad:3. Если нейросеть настроить, то этот результат можно улучшить. Предположим, что такой результат нас устраивает, и посмотрим, как конкретно используется нейросеть для получения прогноза величины, которая нам заранее не известна.
Загрузим в NetMaker файл с новыми данными, для которых результат уже заранее не известен. С этим файлом нужно проделать те же манипуляции, что и при подготовке данных для обучения, за исключением создания столбца с известными будущими значениями BD+4. Естественно, анализ циклов и корреляции данных тоже делать не нужно.
Если теперь в BrainMaker подать на вход обученной нейросети новые данные, то в поле Out (рис.4) будет показан прогноз значения BD100D на четыре дня вперед. Изменив способ отображения с thermometers на number можно получить числовое значение прогноза. Затем прогноз обычно записывают в специальный выходной файл или устанавливают динамическую связь (DDE) BrainMaker с другими приложениями. Например, делают следующую цепочку. Из системы получения финансовых данных в реальном времени передают эти данные в EXCEL, где в автоматическом режиме производятся манипуляции по подготовке, которые мы делали в NetMaker (формирование новых столбцов, смещения, расчет новых параметров и т. д.) Затем снова через динамический обмен подготовленные данные поступают в BrainMaker, и опять же через динамический обмен прогноз возвращается в EXCEL.
|
Литература:
BrainMaker Prfessional. Neural Network Simulation Software UserБ??s Guide and Reference Manual
http://www.aha.ru/~mdo/office/bm-fin.htm
