- 3.1. Пиксельные форматы
- 3.2. Двойная буферизация
- 3.3. Перекрытия
- 3.4. Множественность цветовых карт (colormaps)
- 3.5. Вывод стерео
Реалистичный 3D-рендеринг - получение изображений трехмерных сцен с фотографическим качеством в вычислительном плане является одной из самых дорогих задач. Даже на наиболее быстрых рабочих станциях с мощными RISC-процессорами, не говоря уже о ПК, для поддержки рендеринга устанавливаются специальные платы, работающие параллельно с основными процессорами и выполняющие только графическую обработку. Вообще говоря, существующее программное обеспечение позволяет выполнять рендеринг на компьютерах любого класса - вопрос только во времени. Сегодня интенсивно развиваются такие приложения, как обработка медицинских данных, цифровое телевидение, моделирование динамических процессов, для которых рендеринг должен выполняться в темпе поступления данных или интерактивно. В этих приложениях специализированная аппаратная поддержка рендеринга критически необходима. Данная статья посвящена рассмотрению основных архитектурных принципов, на которых строится современная графическая аппаратура. Иметь представление об этих принципах весьма полезно для оценки конкретной графической системы - современные реализации отличаются скорее качественно, чем количественно, в различной степени поддерживая разные графические операции. Именно поэтому часто оказывается, что тесты графической производительности: скорость генерации прямых, количество закрашиваемых треугольников - не дают адекватной картины реальных возможностей вычислительной системы.
1. Графический конвейер
Если не ограничиваться аппаратурой, а рассмотреть поддержку графической обработки для современных систем в целом, то видно, что она базируется на понятии конвейера: графические данные проходят последовательно несколько этапов обработки - выходные данные одного этапа сразу передаются на вход следующего. Абстрагируясь от связанных с конкретными реализациями деталей, можно рассмотреть универсальный графический конвейер и выделить в нем 5 этапов.
1) Этап генерации (G) - создание и модификация прикладных структур данных.
2) Этап обхода (T) прикладных структур данных и порождение соответствующих графических данных.
3) Этап преобразования (X), на котором графические данные из системы координат объекта преобразуются в систему координат наблюдателя, выполняется расчет освещенности, отсечение преобразованных данных, а затем проецирование результата в пространство окна.
4) На этапе растеризации (R) создаются и записываются в буфер кадра дискретные образы примитивов: точки, отрезки и полигоны. Буфер кадра - это банк памяти, предназначенный для хранения массива пикселей изображения. На этом этапе для всех вершин геометрических объектов вычисляется закраска, производится наложение определенных участков текстуры, а также выполняются пиксельные операции, такие, например, как сравнение по глубине.
5) На этапе вывода (D) происходит сканирование буфера кадра и вывод изображения на экран дисплея.
Два первых этапа сильно зависят от приложения, имеющегося графического интерфейса пользователя и от способа организации самой прикладной программы (скажем эти этапы могут быть совмещены). Поэтому графические системы общего назначения поддерживают главным образом последние три этапа, которые собственно и реализуют рендеринг.
Реальной и широко распространенной реализацией этапов рендеринга для универсального конвейера стал программный интерфейс для 3D графики OpenGL [1]. Поскольку OpenGL ориентирован исключительно на рендеринг, он может быть встроен в любую оконную систему или вовсе использоваться без нее. Действительно, входом для OpenGL служат данные, описывающие вершины геометрических объектов и их свойства, а выходом - изображение, сформированное конвейером обработки в буфере кадра. В конвейере OpenGL поддерживаются такие графические операции, которые могут быть реализованы как при наличии специализированной аппаратуры, так и без нее. В результате реализация графического конвейера OpenGL имеет несколько важных свойств.
Эти свойства сделали OpenGL стандартом в технологии открытых систем.
В OpenGL уже упомянутый универсальный графический конвейер в общем виде получает конкретную детализацию, которую иллюстрирует рисунок 1.
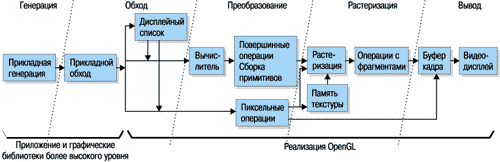
Рисунок 1.
Отображение конвейера OpenGL на универсальный графический конвейер.
1.1. Классификация графической аппаратуры
Реализации графических систем можно классифицировать по степени аппаратной поддержки этапов конвейера рендеринга.
В архитектуре графических систем универсальный процессор компьютера, управляющий графической аппаратурой, принято называть хостом. Для оценки графической подсистемы важно, какие этапы графического конвейера выполняются на хосте программно, а какие на специализированной графической аппаратуре - аппаратно.
Курт Акелей, соавтор спецификации OpenGL, ввел полезную для классификации графических подсистем систематику [2], основанную принципах разделения этапов графического конвейера на программную и аппаратную реализации. Буквы GTXRD - этапы универсального графического конвейера, дефис между ними указывает, что этапы справа от него реализованы в основном аппаратно. Например, графическая плата для ПК - стандартный адаптер VGA может быть примером архитектуры GTXR-D, ибо аппаратно реализован лишь этап вывода. Графическая подсистема SGI Indigo Extreme служит примером архитектуры GT-XRD, в ней аппаратно реализованы последние 3 этапа, SGI Indy 24 GTX-RD, RealityEngine GT-XRD, E&S 4000 G-TXRD.
1.2. Маршруты рендеринга
Конкретный вид и качество полученного в результате рендеринга изображения сцены зависит от текущих режимов OpenGL и заданных для них параметров. Так многоугольник изображается по-разному в зависимости от режимов освещенности, текстуры, смешивания (blending), устранения лестничного эффекта, проверки глубины и многого другого. В реализации OpenGL полезно представлять данный набор режимов рендеринга и их параметров как маршрут рендеринга. Каждому маршруту будет соответствовать своя последовательность графических операций, реализуемых либо программно, либо аппаратно. Производительность рендеринга на некотором маршруте зависит от того, насколько хорошо этот маршрут оптимизирован и аппаратно поддержан в данной конкретной реализации OpenGL.
На практике система, считающаяся GT-XRD-архитектурой, может не полностью поддерживать аппаратно этапы преобразования и растеризации, например она может не иметь поддержки наложения текстуры в аппаратуре растеризации. Поэтому систематика GTXRD дает только общее и довольно грубое представление о тех операциях, которые поддерживаются аппаратно. Если приложение использует, например, текстурирование в реализации OpenGL, в которой соответствующей аппаратной поддержки нет, эта операция будет выполняться программно. Более того, в такой ситуации отдельные операции преобразования, которые могли бы быть выполнены аппаратно в режиме без наложения текстуры, также будут производиться программно. Важно понимать, что наличие аппаратной поддержки какой-либо функции не дает гарантии, что она действительно будет выполняться аппаратно с конкретным маршрутом рендеринга.
Если рассмотреть два маршрута рендеринга, для которых обеспечивается аппаратная поддержка, то, скорее всего, один из маршрутов будет работать быстрее, чем другой. Например, если в сцене присутствуют источники света, то при включении одного источника рендеринг будет выполняться быстрее, чем, скажем, при восьми. Даже в реализациях, в которых тест глубины пикселей поддержан аппаратно, маршруты с выключенным тестом глубины будут выполняться быстрее, чем при отсутствии этого режима. При оценке реализации OpenGL для конкретного приложения лучше всего рассмотреть реальные маршруты рендеринга, определяемые в приложении, и установить, насколько данная реализация OpenGL эффективно использует имеющуюся аппаратуру.
2. Аппаратные ускорители для OpenGL
Специальная графическая аппаратура сейчас имеется практически на любых компьютерах, в том числе на ПК и на простейших 2D графических рабочих станциях, где она принадлежит к классу GTXR-D. Она оценивается по таким параметрам, как разрешение экрана и количество цветов, а также по пропускной способности буфера кадра. Аппаратные ускорители здесь рассчитаны на работу с простыми примитивами - отрезки и прямоугольники 2D. При переходе к 3D графике значительно усложняются и методы, и поддерживающая их аппаратура.
3. Вывод на экран (D)
Дисплейная аппаратура для 3D-графики, реализующая OpenGL, более сложна, чем в системах 2D, где она обеспечивает вывод на экран единственного буфера кадра, все пиксели которого имеют один и тот же формат.
3.1. Пиксельные форматы
OpenGL позволяет использовать две цветовые модели - RGBA (red, green, blue, alpha) и цветовой индекс. RGBA очень похожа на режим TrueColor в X Window: компоненты R, G, B явно задают интенсивность оттенков красного, зеленого и синего для данного цвета. Цветовой индекс подобен режиму Pseudo-Color, он косвенно адресует цвет по его номеру в заданной цветовой палитре. Обычно реализации OpenGL позволяют одновременно изображать на экране окна с обеими цветовыми моделями. Количество цветов в палитре, или цветовое разрешение для каждого окна также может варьироваться. Поэтому, например, на экране могут сосуществовать и окно с 8-битовым цветовым индексом, и окно с 24-битовым RGBA. В таких системах дисплейная аппаратура сканирует не только значения всех пикселей из буфера кадра, но также и их форматы, после чего выясняется, какой цвет надо помещать на экран.
3.2. Двойная буферизация
OpenGL поддерживает двойную буферизацию для каждого окна. Окно имеет два цветовых буфера - передний и задний. Из переднего буфера происходит вывод на экран, параллельно с которым в заднем буфере строится новое изображение. При поступлении запроса на обмен содержимое заднего буфера логически переносится в передний. Двойная буферизация очень существенна для 3D, так как позволяет получить гладкую анимацию из кадров, формируемых путем рендеринга. При такой аппаратной поддержке физического переноса данных не происходит, а значит, нет и связанных с этим задержек. Обмен буферов должен быть согласован с интервалом вертикальной развертки монитора - происходить при холостом движении пушки монитора в начальную точку экрана, с которой начинается сканирование следующего кадра видео. Такое согласование позволяет избежать зрительного артефакта, известного как разрыв, наблюдаемый, при изменении буфера в середине сканирования, в результате чего на экране показывается часть изображения из переднего буфера, а часть - из заднего.
Если нет аппаратной поддержки, задний буфер обычно размещается в памяти хоста. В этом случае обмен буферов требует копирования из памяти хоста в буфер кадра и добиться синхронизации с вертикальной разверткой затруднительно. Поэтому аппаратная двойная буферизация типична для 3D GTX-RD и GT-XRD систем.
3.3. Перекрытия
Аппарат перекрытий - это механизм создания в буфере кадра дополнительных изображений, которые выводятся поверх основного, не разрушая его: после снятия перекрытия основные окна не требуют перерисовки. Это особенно актуально для 3D-сцен, изображаемых с помощью OpenGL, так как их регенерация - это повторное выполнение рендеринга. Перекрытия используются для реализаций меню pop-up и pull-down, резиновой нити и аннотаций. Интерактивные манипуляции с этими объектами производятся поверх изображений в основных окнах, перерисовка которых обходится дорого.
Перекрытия обычно поддерживаются аппаратно - непосредственно в реализации OpenGL, либо системе X Window, используемой вместе с OpenGL.
3.4. Множественность цветовых карт (colormaps)
Реализации OpenGl часто включают в себя поддержку работы с несколькими цветовыми картами - несколько окон, в которых используются различные множества цветов, могут одновременно изображаться на экране с правильными цветами. Если множественность цветовых карт не поддерживается, то цвета в некоторых окнах будут искажаться, а при переходе фокуса ввода от одного окна к другому станет происходить изменение цветов - мелькание. Число физических цветовых карт ограничено, и если оно превышает определенный предел, то будет наблюдаться аналогичный эффект.
3.5. Вывод стерео
3D графические системы, в которых используется OpenGL, оснащаются дисплейной аппаратурой, поддерживающей стереовывод. Обычно для этого используется монитор с двойной скоростью регенерации и специальные очки с быстрым переключением жидко-кристаллических шторок между глазами оператора, синхронно со сменой видеокадров. Дисплей непрерывно сканирует изображение то для левого глаза, то для правого.
OpenGL предусматривает 4-х буферную схему - для стереовывода почти всегда требуется двойная буферизация, в которой к переднему и заднему буферам добавляются левый и правый. Такая буферизация предусматривает значительную память и большую скорость регенерации монитора, поэтому аппаратная поддержка стерео в OpenGL пока не получила распространения. Чтобы добиться стереоэффекта, приложение OpenGL должно выполнять рендеринг двух видов, в которых точки наблюдения соответствуют положению левого и правого глаза, слегка различаясь при этом.
4. Растеризация (R)
Растеризация - это процесс конвертации уже преобразованных в оконные координаты примитивов в значения пикселей, принадлежащих оконной области вывода буфера кадра. Этап растеризации OpenGL можно разбить на 3 подэтапа: фрагментация примитива, наложение текстуры и тумана, операции над фрагментами.
4.1. Фрагментация примитива
Фрагментация определяет пиксельные позиции в буфере кадра, занятые примитивом. Для каждой занятой пиксельной позиции генерируется фрагмент - пиксельная позиция вместе с цветом, глубиной и координатами текстуры. Данные, связанные с фрагментом, используются на следующих этапах для вычисления истинного цвета пикселя. Факторы, влияющие на фрагментацию, включают режимы устранения лестничного эффекта, толщину линии, стиль линии, удаление скрытых поверхностей, а также пиксельные режимы.
Такие примитивы, как многоугольники, обычно разбиваются на набор хорд - горизонтальных линий толщиной в 1 пиксель, заданных позицией начального пикселя и длиной. Фрагменты генерируются путем продвижения вдоль хорд. Цвет, глубина и координаты текстуры получаются интерполяцией соответствующих значений между двумя концами хорды.
Таким образом растеризация многоугольников имеет две стадии: конвертация в хорды и их растеризация. Конвертер хорд многоугольника может быть реализован аппаратно. Результаты его работы передаются аппаратной машине фрагментации хорд, которая, продвигаясь вдоль хорды, получает интерполяцией глубину и цвет. Для снижения стоимости аппаратуры систем GTX-RD конверсия хорд может осуществляться в хосте, тогда аппаратная поддержка фрагментации многоугольников ограничивается машиной фрагментации хорд.
Другие примитивы: точки или отрезки, могут также конвертироваться в хорды, либо их фрагментация поддерживается специальными машинами.
4.2. Наложение текстуры
В OpenGL цвет каждого фрагмента может быть изменен посредством наложения текстуры и тумана. Наложение текстуры напоминает наклеивание обоев на поверхность. Заданные для фрагмента координаты текстуры определяют элемент текстурного изображения - тексель, значение которого комбинируется с цветом фрагмента. Аппаратура наложения текстуры довольно дорога - она работает с каждым пикселем в отдельности и требует большой объем быстрой памяти.
4.3. Операции над фрагментами
Буфер кадра в OpenGL содержит не только значения цвета. Имеются также служебные буфера, хранящие информацию по каждому пикселю - буферы: глубины, шаблона, накопления, альфа и вспомогательный. Могут быть буфера для двойной и стереобуферизации. Служебные буферы обычно размещаются в специальной графической памяти. Альтернатива - размещение их в оперативной памяти хоста.
Некоторые операции с фрагментами, например проверка глубины, изменяют служебные буферы, но встречаются и такие, которые их не используют, например проверка отсечения. Операции над фрагментами образуют конвейер (рисунок 2), наиболее дорогими операциями в котором являются чтение/запись служебного буфера - тесты глубины и шаблона.
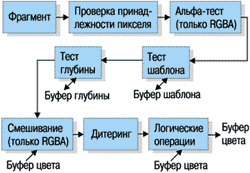
Рисунок 2.
Конвейер операций над фрагментами.
Учитывая, что операции обновления разных пикселей выполняются независимо, их можно распараллелить. Эффективный способ реализации этой процедуры - использование нескольких пиксельных процессоров, каждый из которых занимается обработкой своего подмножества пикселей экрана. Однако у такого подхода имеется предел по стоимости/эффективности. Предположим, что каждый пиксель экрана имеет свой собственный процессор, а поскольку в любой момент времени большинство пикселей не обновляются, очень многие процессоры будут всегда простаивать.
5. Преобразование геометрии (G)
Этап преобразований можно разбить на несколько подэтапов. Модельное преобразование: объектные координаты конвертируются в систему координат наблюдателя, в соответствии с текущей матрицей. Производится также преобразование нормалей к поверхностям и приведение их к единичной длине. Вычисление освещенности: если освещение включено, OpenGL выполняет вычисление освещенности каждой вершины, исходя из параметров освещения. Проекционное преобразование: координаты наблюдателя конвертируются по текущей проекционной матрице. Проверка отсечения: примитивы отсекаются по текущему объему отсечения и дополнительно заданной плоскости отсечения. Перспективное деление: происходит переход к однородным координатам (x, y ,z, w) делением x, y, z на w. Преобразование порта вывода: координаты вершин отображаются в порт вывода (view port).
Все эти подэтапы требуют интенсивных вычислений и повторяются для каждой вершины. Число операций с плавающей точкой при преобразовании одной 3D вершины, освещенной единственным простым источником света, примерно 100. Это значит для того, чтобы выполнить 30 раз в секунду рендеринг сцены, состоящей из 10 тыс. треугольников, требуется около 90 млн. вещественных операций в секунду только на геометрические преобразования. Поэтому разгрузка процессора хоста и выполнение геометрических преобразований на специализированной графической аппаратуре имеет большое значение для приложений, требующих высокой скорости рендеринга.
6. Конвейерная обработка и распараллеливание
Обычно используют два метода аппаратного ускорения. Конвейерная обработка - метод, применяемый, в случае когда этапы задачи упорядочены подобно сборочной линии. Специализированная аппаратура выполняет операции для каждого этапа, передает результаты на следующий этап и сразу же принимается за новую работу, не дожидаясь окончания всего процесса. Теоретически конвейерная обработка ускоряет процесс пропорционально числу этапов конвейера.
Второй метод - распараллеливание. Он применяется, когда задача может быть разделена на почти независимые кванты. Аппаратура для выполнения задачи дублируется несколько раз - создается несколько параллельных процессоров. Каждый квант работы обрабатывается свободным процессором. На рисунке 3 показаны архитектуры конвейерной обработки и распараллеливания.
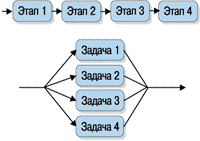
Рисунок 3.
(а) Конвейерная архитектура - четыре этапа; (б) Параллельная архитектура
- четыре задачи.
Хотя конвейерная обработка и распараллеливание особенно полезны на этапе геометрических преобразований, эти два метода используются повсюду в универсальном графическом конвейере. Пример операций с фрагментами, выполняемыми параллельно, показан на рисунке 2.
Конвейерная обработка проста, но она не всегда так гибка, как распараллеливание. Этапы в аппаратном конвейере зачастую реализуют схемно, в результате чего трудно добавить новый этап. Если нагрузка на некотором этапе становится больше, чем на других, этот этап начинает сдерживать работу всего конвейера, и производительность системы падает. Распараллеливание гибче, чем конвейерная обработка, так как каждый квант выполняется в основном независимо. В отличие от аппаратного конвейера параллельные процессоры могут выполнить дополнительную работу и не допустить простоя остальной аппаратуры.
Важно то, что конвейерная обработка и распараллеливание не противоречат, а дополняют друг друга. Например, внутри каждого параллельного геометрического процессора легко обнаружить конвейер вычислений с плавающей точкой.
Еще одним существенным моментом оценки графической аппаратуры является то, каким из двух способов, схемным или более общим, микропрограммным, она реализована. Обычно схемная аппаратура работает быстрее, но она не очень гибка и проектировать ее труднее. Схемная аппаратура больше подходит для хорошо определенных задач, которые почти наверняка не будут меняться. Аппаратура растеризации и вывода на дисплей часто реализуется схемно, а аппаратура для геометрических преобразований обычно микропрограммно.
6.1. Типы распараллеливания
Известны два способа реализации микропрограммных процессоров: SIMD (Single Instruction, Multiple Data) - все процессоры выполняют одну и ту же микропрограмму, и MIMD (Multiple Instruction, Multiple Data) - каждый процессор выполняет свою собственную микропрограмму. Понятно, что SIMD-архитектура дешевле, чем MIMD. Преимущество SIMD-процессоров проявляется при вычислениях однородной природы, например при обработке треугольников одного типа с одинаковыми режимами OpenGL. MIMD-архитектура больше подходит для менее однородных работ, допустим для обработки треугольников с изменяющимися режимами OpenGL.
Конвейер с N этапами или N-кратное распараллеливание не обязательно приводят к N-кратному увеличению производительности. При изменении состояния внутри аппаратного конвейера, вероятно, потребуются отстойники, снижающие производительность, поскольку не все этапы будут постоянно загружены. Аналогично в параллельной системе может не хватать работы для загрузки всех N процессоров или могут возникать коммуникационные издержки, необходимые для координации параллельной обработки.
7. Требования к аппаратуре для оконной системы
До сих пор проблемы графического рендеринга обсуждались без учета того факта, что на экране дисплея могут одновременно строить изображения несколько программ. На графических станциях обычно множество программ выполняются одновременно и разделяют доступ к аппаратуре ускорения графики. Это разделение управляется обычно оконной системой, X-сервером в случае X Window.
7.1. Переключение графического контекста
В Х Window лишь единственная программа, а именно X-сервер, может непосредственно управлять графической аппаратурой. X-клиенты посылают запросы X-серверу для диспетчеризации. На самом деле процесс X-сервера действует как заместитель по рендерингу для всех Х-клиентов. Такой подход создает две проблемы.
Во-первых, в системах GTX-RD и GT-XRD графический контекст OpenGL, от которого зависит настройка аппаратуры, весьма велик, так как он включает все параметры освещения, матрицы, режимы, память текстур и пр. Чтобы реализация OpenGL могла работать в рамках оконной системы, должен быть эффективный способ перенастройки аппаратуры при переключении контекста.
Во-вторых, когда ускоряющая графическая аппаратура действует достаточно быстро, издержки генерации, пересылок и диспетчеризации Х-протокола возрастают по сравнению с аппаратным рендерингом. Быстрая графическая подсистема не достигнет своей потенциальной производительности, если она не может достаточно быстро получать команды OpenGL. Расширение OpenGL - GLX, интегрирующее Х с OpenGL, исправляет положение. GLX дополняет реализацию OpenGL средствами прямого рендеринга так, что локальная OpenGL программа может выполнять рендеринг непосредственно на графическую аппаратуру.
Когда весь рендеринг передается аппаратуре через Х-сервер, то последний настраивает ее по мере переключения контекста. При прямом рендеринге перенастройка должна производиться несвязанными процессами в разных адресных пространствах. Если графическая аппаратура поддерживает переключение контекста асинхронно с рендерингом, ядро и оконная система могут "договориться" о виртуализации графики для OpenGL-программ, не сообщая им об этом.
Другой подход к ускорению переключения контекста - поддержка множества контекстов в графической аппаратуре. Это может быть дорого, поскольку контекст OpenGL велик и требует много аппаратных ресурсов. Аппаратные ресурсы для контекстов не увеличивают производительность, когда имеется единственный процесс рендеринга. Кроме того, в системе может быть превышено число аппаратных контекстов, поэтому по-прежнему должно поддерживаться переключение контекста в памяти хоста.
7.2. Быстрое отсечение по окну
В конвейере операций над фрагментами (рисунок 2) имеется проверка принадлежности пикселя окну, результатом которой становится отбрасывание фрагмента, если он находится вне области рисования окна.
Обычно в архитектурах GTX-RD и GT-XRD отсечение по окну должно выполняться аппаратно, поскольку проверка принадлежности пикселя завершает графический конвейер. При использовании прямого рендеринга программа обычно не распознает области рисования текущего окна. По этим причинам отсечение по окну обычно реализуется аппаратно, а информация об отсечении корректируется Х-сервером по мере того, как меняется раскрой экрана.
Известны два общих подхода к аппаратной поддержке отсечения по окну. В методе отсекающих прямоугольников видимую область окна задают ограниченным числом прямоугольников (обычно от 1 до 4). Таким способом можно производить отсечение только в окнах с простой конфигурацией. В методе номеров отсечения каждому пикселю в буфере кадра сопоставляется номер отсечения - номер окна, видимой области которого принадлежит пиксель. Все видимые окна нумеруются последовательно. Номер 0 присвоен области экрана, не содержащей окон. При отображении фрагмента проверяется, совпадает ли номер его окна с соответствующим номером отсечения. Обычно для номера отсечения отводится 2-4 бита, что дает 3-15 значений. Этот метод работает для произвольных областей, тогда как первый - только для простых. Обычно применяется гибридный подход, объединяющий оба метода.
Аппаратная информация об отсечении должна сохраняться и изменяться Х-сервером при изменении областей отсечения окон. Заметим, что число значений номеров отсечения ограничено, поэтому Х-сервер должен быть готов виртуализировать использование номеров отсечений, если слишком много окон имеют сложные области отсечения.
7.3. Аппаратные курсоры
Оконные системы используют курсоры для отслеживания движений мыши. Аппаратная реализация курсора означает, что изображение текущего курсора в текущей позиции рисуется аппаратно поверх изображения, выводимого из буфера кадра. Если аппаратный курсор не поддерживается, Х-сервер должен рисовать изображение курсора в буфере кадра. Если команды рендеринга затрагивают изображение курсора, то он должен быть перерисован. Это не только приводит к мерцанию курсора, но и означает, что программа рендеринга должна знать положение курсора. В результате 3D рендеринг сильно усложняется, поэтому обычно курсор реализуют аппаратно.
8. Узкие места в графической подсистеме
Узкое место - это ситуация, когда одна задача ограничивает производительность всей системы до такой степени, что другие задачи не могут достичь своих потенциальных возможностей. Добавление аппаратуры ускорения OpenGL мотивируется достижением лучшей графической производительности. Но если аппаратура не сбалансирована, то она будет недозагружена из-за узких мест в системе, и общая производительность будет меньше ожидаемой.
Узкие места проявляются на том или ином этапе конвейера. Например, для приложений визуального моделирования, подобных летным тренажерам, где активно используется заполнение больших текстурированных многоугольников, узким местом может быть этап растеризации. Для программы визуализации молекул, отображающей тысячи атомов, по всей видимости, узким местом будет этап преобразований. Предельная скорость аппаратных преобразований выражается в тысячах многоугольников в секунду и зависит от установленных режимов преобразования, например от числа источников света.
Некоторые задачи, например, анализ прочностных характеристик автомобиля по методу конечных элементов, не могут генерировать графические команды так быстро, чтобы загрузить графическую подсистему. Они имеют узкое место на этапах генерации и обхода и ограничены производительностью хоста.
Хороший метод для определения того, ограничивает ли производительность программы, например, скорость заполнения, состоит в перерисовке окон очень малого размера. Если скорость возрастает, то программа почти наверняка ограничена скоростью заполнения. В определении пределов производительности хоста могут помочь профайлеры и специальные отладчики для OpenGL, позволяющие найти, какие операции OpenGL наиболее часто использует ваша программа.
Еще одно узкое место - скорость, с которой команды передаются из хоста в OpenGL. Если приложение выполняется на локальной графической станции, для ускорения передачи проще всего использовать прямой рендеринг. Один из способов ускорения передачи - использовать дисплейные списки OpenGL. Если нет прямого рендеринга, дисплейные списки передаются Х-серверу так, что для выполнения всего списка достаточно передать лишь одну команду. Это может значительно снизить сетевые издержки непрямого рендеринга. Дисплейные списки также можно загрузить в аппаратуру так, что они будут выполняться без издержек хоста.
Возможно также появление больших задержек - зависания на интерфейсе между быстрым компьютером и быстрой графической подсистемой. Причиной может быть шина хоста, используемая для связи с графической подсистемой, ширина полосы пропускания которой может быть недостаточна для управления графикой с требуемой вами производительностью.
Возможны и другие узкие места. Если программа достаточно часто изменяет состояние OpenGL, то эти изменения режимов становятся узким местом. Загружаемые в аппаратуру карты текстуры - другое потенциально узкое место.
Понимание узких мест для данного приложения на данной системе важно для его настройки. Программа, ограниченная скоростью заполнения, может использовать лучшее освещение и более детальную сетку без ухудшения производительности. Аналогично, ограниченная скоростью преобразований программа может достичь лучшей производительности, если уменьшить число преобразуемых многоугольников, используя более грубую сетку.
9. Остерегайтесь тестов
Следует весьма осторожно относится к графическим тестам. Производительность, действительно имеющая значение, - это производительность конкретного приложения.
Графические тесты часто связаны с искусственной рабочей нагрузкой. Реальная графическая программа не просто отображает миллионы 3D-линий, а напротив, выводит разнообразные примитивы и использует разные режимы, однако издержки переключения редко измеряются тестами. Реальные программы также тратят время на генерацию данных для рендеринга, а это задача, для которой нет тестов. Тесты полезны лишь для определения верхнего предела производительности данной задачи рендеринга, но не следует ожидать, что реальное приложение достигнет результатов теста.
Литература
[1]. M. Segal, K. Akeley. The OpenGL Graphics System: A Specification, Version 1.0. Silicon Graphics, June 30, 1992.
[2]. K. Akeley. The Silicon Graphics 4D/240GTX Superworkstation, IEEE Computer Graphics and Applications, July 1989.
Оценивая реализацию OpenGL для каждого конкретного приложения, следует определить, какие графические функции реализуются аппаратно, а какие - программно. Не ожидайте, что любая особенность OpenGL будет иметь аппаратную поддержку. Проверьте выбранную систему на соответствие требованиям вашей прикладной деятельности. Не доверяйте "стандартным" тестам, ибо они могут измерять графическую производительность на маршруте рендеринга, который не особенно важен для вашего приложения. Ничто не сможет заменить ваши собственные тесты на тех маршрутах рендеринга, которые критичны для конкретного приложения.
Универсальный конвейер GTXRD дает хороший способ для грубой классификации графической архитектуры. Работу приложений OpenGL ускоряют выполненные частично или полностью аппаратно этапы растеризации и преобразования. Хорошая поддержка оконной системы требует дополнительной аппаратуры. Производительность подсистемы графической аппаратуры для OpenGL должна быть сбалансированной для вашего приложения. Чем быстрее графическая аппаратура, тем более важной становится поддержка прямого рендеринга.
