Данная статья продолжает начатое в [1] описание системы визуализации данных Iris EXPLORER компании Silicon Graphics и, в отличие от предыдущей публикации, посвященной предметной стороне дела - способам представления данных и методам их визуализации, ориентирована на технологические инструментальные аспекты использования этой системы, а именно: средства ввода данных и средства подготовки модулей. Статья довольно подробно описывает визуальную технологию работы с инструментальными средствами. Цель, конечно, состоит не в том, чтобы дать исчерпывающее описание предмета, а в том, чтобы передать дух визуального аппарата, что, к сожалению, невозможно без знакомства с деталями.
Технологические средства системы Iris EXPLORER объединяет одно важное обстоятельство - все они реализованы, как визуальные утилиты. Пользователь системы работает в графической среде, в которой каждому объекту соответствует свой графический образ, и оперирует набором интерактивных операций, позволяющих выделить, переместить или выполнить объект. Конечно, метафора визуальной среды уже стала классикой программирования, но все дело в том, что в системе EXPLORER объектами являются программы, рассматриваемые как функциональные единицы - модули.
В предыдущей статье рассматривалось, как из готовых модулей визуально строятся приложения. У системы EXPLORER есть еще одно достоинство - полный и согласованный репертуар средств, поддерживающих разработку модулей для визуальной среды. По-видимому, не вызовет возражений утверждение, что для прикладных программистов создание интерактивной графической оболочки приложений является трудной задачей, которая требует освоения мощного блока базовых программных инструментальных средств, например X Window, Motif или OpenGL. Альтернатива, предлагаемая в системе EXPLORER, базируется на том, чтобы полностью разделить создание алгоритмической части приложения и его интерактивной оболочки, причем последняя задача решается с помощью визуальных же средств и, естественно, не требует привлечения каких-либо мощных инструментов.
Радикальное упрощение процесса создания интерфейса не дается бесплатно - в системе EXPLORER можно реализовать интерфейс только определенного вида. Чтобы оценить, насколько сбалансированы возможности системы и простота ее использования, нужно обратиться к фактической стороне.
Хотя принципы, на которых построены рассматриваемые средства, в значительной мере не зависят от предметной ориентации системы EXPLORER, некоторые конкретные решения определяются предметной областью, то есть областью визуализации данных. В связи с этим необходимы базовые сведения о системе EXPLORER (подробности содержатся в [1]).
Общие сведения
Предметной областью системы EXPLORER является визуализация данных, обработка изображений и создание продукции мультимедиа. В ряду систем аналогичной направленности EXPLORER выделяется своим оригинальным пользовательским интерфейсом, основные характеристики которого - визуальность, объектная ориентированность и модульность.
Для представления объектов обработки в системе EXPLORER существует пять типов данных: Lattice, Pyramid, Geometry, Parameter и Pick. Только с объектами этих пяти типов могут работать функциональные единицы системы - модули. Каждый модуль реализует некоторое преобразование объектов в рамках перечисленного мира типов. Конкретное приложение строится как композиция модулей. Типы Lattice и Pyramid предназначены для представления исходных данных. Если говорить о задачах визуализации данных, то конечной целью приложения является преобразование исходных объектов в тип Geometry. Этот тип представляет геометрию визуализируемых объектов как совокупность точек, линий и полигонов. В системе EXPLORER есть набор модулей, выполняющих различные виды преобразований из исходных данных в тип GEOMETRY. Выбором того или иного способа преобразования определяются различные формы геометрического представления исходных данных. Построив геометрические объекты, можно воспользоваться модулями визуализации, например модулем Render, который показывает изображения объектов в 3D-пространстве.
Концепция сборки приложений из модулей отображается в интерфейс пользователя следующим образом. Каждый модуль имеет визуальный образ - прямоугольное окно в смысле системы X Window, которое называется управляющей панелью модуля. В управляющей панели размещаются виджеты - устройства для графического ввода значений параметров обработки (данных типа Parameter).
Создание приложения - в системе EXPLORER это называется компоновкой схемы - производится с помощью Редактора Схем (Map Editor). Модули, а точнее их управляющие панели, переносятся в рабочее поле Редактора Схем и связываются между собой. Функциональные возможности модуля - способность к связыванию с другими модулями - определяются двумя аспектами: реализованным в модуле алгоритмом и интерфейсом модуля по данным.
Интерфейс модуля по данным образован множеством его входных и выходных портов или типов данных, который модуль принимает на входе или выдает в результате обработки. Порты имеют визуальные образы на панели модуля в виде меню входов и выходов. Каждому порту соответствует пункт меню, где указывается имя порта, имеющее прикладной смысл и тип данных.
Что такое связь модулей в схеме приложения и как она создается? Связь соединяет выходной порт одного модуля со входным портом другого. Она создается визуально, для чего из меню входов и меню выходов выбирается нужная пара портов. Множество связанных модулей образует схему, которую можно выполнить и получить результат в окне модуля визуализации. При работе схемы последовательность выполнения ее модулей определяется вычисленностью их входных портов. Таким образом, основным способом разработки приложений в системе EXPLORER является визуальная компоновка схем, заключающаяся в выборе подходящего набора модулей и связывании их входных и выходных портов. Компоновка схем производится в окне Редактора Схем.
Несмотря на то что большинство задач может быть решено путем использования поставляемых в системе EXPLORER модулей, вопрос об открытости и расширяемости системы не теряет своей актуальности. В состав EXPLORER входят специальные инструментальные средства, решающие следующие три задачи:
- ввод данных и преобразование в типы данных EXPLORER;
- создание модулей EXPLORER из программ, написанных на языках C или Fortran;
- разработка внешнего пользовательского интерфейса модулей.
Утилита ввода и преобразования данных DataScribe
Данные, предназначенные для визуализации, обычно являются результатом численного моделирования, мониторинга или оцифровки. Программы генерации этих данных, конечно, не могут и не должны быть написаны в расчете на форматы системы визуализации, поэтому перед разработчиком визуального приложения обычно стоит задача преобразовать свои данные в объекты EXPLORER - типы Lattice и Pyramid.
Тип Lattice подробно описан в предыдущей статье [1]. Это агрегатный тип, содержащий координаты узлов сетки, массивы значений данных, определенных на этих узлах, и размерности массивов. Форма представления данных типа Lattice зависит от вида сетки, которая может быть однородной, заданной границей или криволинейной. На языке программирования C тип Lattice представляется структурой с вариантами, существует, кроме того программный интерфейс для работы с данными этого типа. Для программиста нет, собственно, никаких проблем, чтобы ввести свои данные и сформировать соответствующую структуру. Однако использование визуального конвертора - утилиты DataScribe позволяет не вдаваться в детали представления и дает новое качество как по способу формирования модуля ввода, так и по его общности.
Построение модулей ввода
Утилита DataScribe используется для построения модулей, выполняющих ввод числовых данных из файлов и преобразование этих данных в тип Lattice. Предполагается, что входные файлы имеют определенную структуру и состоят из скалярных данных и массивов.
С точки зрения пользователя утилита DataScribe представляется в виде нескольких взаимосвязанных окон - панелей, в процессе работы с которыми происходит описание форматов входных файлов, выходных объектов типа Lattice и выполняется связывание отдельных скалярных величин и массивов из входных файлов с компонентами структур выходных объектов. Описание строится иерархически. Верхний уровень называется скриптом модуля ввода. Скрипт состоит из нескольких входных и выходных шаблонов. Входной шаблон описывает формат исходных данных, считываемых из входного файла, а выходной содержит описание объектов типа Lattice. В свою очередь, шаблон состоит из последовательности описателей данных - глифов. В результате выполнения DataScribe строится модуль в смысле системы EXPLORER, имеющий в качестве параметров имена входных файлов. Для ввода имен файлов в управляющей панели будут построены виджеты, и, следовательно, один модуль может использоваться для ввода данных из разных файлов.
Работу с утилитой DataScribe можно рассмотреть на примере построения скрипта для чтения двухмерного массива чисел, представленных в кодировке ASCII, и преобразования их в тип Lattice. Предположим, что файл данных начинается с двух целых чисел (в примере это 5,5), которые определяют размерности следующего за ними массива значений данных:
5 5
6 4 3 4 6
4 5 4 5 4
3 4 6 4 3
3 4 5 4 3
5 5 6 5 5
Далее описывается последовательность действий для построения скрипта. Из меню главного окна DataScribe выбирается пункт построения шаблона - пункт Template. В рабочем поле появляется диалоговая панель, в которую требуется ввести основные характеристики шаблона (Рис. 1).
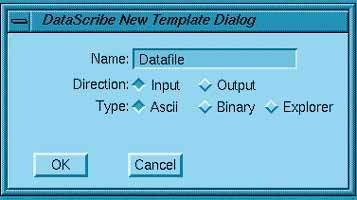
Рисунок 1.
В текстовый слот, озаглавленный Name, вводится имя шаблона - Datafile. Включается кнопка Input в группе Direction, определяющая, что описываются входные данные. В группе Type выбирается кнопка ASCII, задающая тип кодировки. При нажатии OK в окне раскрывается пока пустой шаблон и теперь можно приступить к его заполнению.
В шаблоне перечисляются объекты данных, которые будут вводится из одного входного файла. Каждый объект данных задается своим типом. Все легальные в DataScribe типы данных представлены в Палитре типов данных (Рис. 2).

Рисунок 2.
Типы данных изображаются в палитре пиктограммами или глифами (gliph). Чтобы определить объект данных, нужный глиф переносится в шаблон. Для рассматриваемого примера выбирается глиф типа Vector и помещается в шаблон Datafile. Этот глиф описывает вектор размерностей массива данных - первые два числа из файла: 5 и 5. Глифы имеют атрибуты - параметры, значения которых требуется определить. Если нажать на кнопку с правого края глифа, он раскрывается, и атрибуты становятся видны - это имя, тип компонентов и количество элементов. Изображение раскрытого глифа до ввода значений его атрибутов показано на Рис. 3.
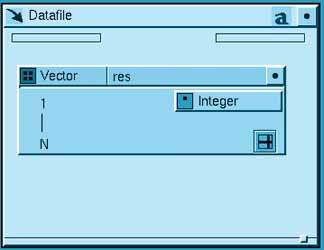
Рисунок 3.
Имя глифа вектора размерностей, например "res", впечатывается в текстовый слот, расположенный в заголовке глифа. Тип компонентов глифа берется из Палитры типов данных - в нашем случае это Integer. Длина вектора размерностей (она фиксирована и равна 2) впечатывается в текстовый слот, в котором исходно задан символ N. На этом определение первого объекта данных - вектора размерностей - завершено, и можно определять второй объект - массив значений. Ему отвечает глиф 2D Array из Палитры типов данных (Рис. 2), который перемещается в шаблон Datafile.
Обозначим глиф массива значений данных DataValue, введя это имя в заголовок. Глиф 2D-массива почти такой же, как и глиф вектора размерностей. Отличие только в том, что появились два индексных направления, обозначенных 1-N1 и 1-N2. Установим курсор для ввода текста на N1 и впечатаем вместо этого res[1]. Заменим таким же образом N2 на res[2]. Тем самым мы связали размерность 2D-массива значений с компонентами вектора размерностей res, который будет вводится из того же файла и который был определен в предшествующем глифе. На этом определение входного шаблона Datafile завершено (Рис. 4).
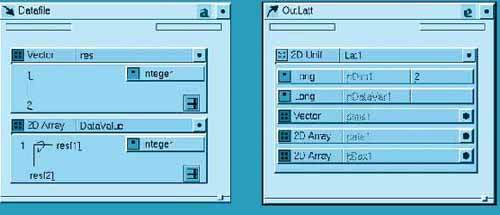
Рисунок 4.
Теперь можно преобразовать входные данные в объект типа Lattice. Определим для него выходной шаблон, вернувшись для этого к главному окну DataScribe и выберем из меню пункт Template. Зададим имя шаблона - OutLatt, выберем в качестве Direction - Output и Type - Explorer, поскольку Lattice - это тип данных Explorer. Выходной шаблон будет состоять из единственного объекта типа 2D-uniform Lattice - двухмерная однородная сетка, поэтому в шаблон OutLatt перемещается глиф 2D Unif из Палитры типов данных (Рис. 2). Обозначим этот глиф Lat1, а раскрыв его, увидим внутреннюю структуру объекта этого типа. На Рис. 4 выходной шаблон с глифом Lat1 расположен в правой части окна.
Структура объекта типа Lattice включает следующие компоненты:
- nDim - размерность сетки. В нашем случае она равна 2;
- nDataVar - количество значений данных в одном узле (равно 1);
- dims - вектор количества узлов сетки в каждом координатном направлении;
- data - 2D-массив значений данных, заданных на узлах.
Формируя выходной объект, мы задаем в шаблоне nDim=2 и nDataVar=1, все остальное получится из входного файла. Для этого выполняется связывание компонентов входного и выходного шаблонов. Процедура связи такая же, как и при связывании портов модулей в Редакторе Схем. Здесь необходимо связать вектор размерностей res из входного шаблона Datafile с вектором количества узлов dims из выходного шаблона OutLatt. Связь устанавливается путем выделения сначала глифа res и затем компонента dims глифа Lat1.
Чтобы завершить пример, требуется также связать глиф DataValue (входной массив значений) с компонентом data глифа Lattice1 из выходного шаблона OutLatt. Если теперь сохранить построенный скрипт под именем Simple, то будет сформирован модуль системы Explorer, который имеет один виджет для ввода параметра - имени файла и выходной порт типа Lattice. При выполнении модуля в этом порту будут находиться конвертированные данные из входного файла.
Теперь можно начать исследование данных, построив простую схему из модулей Simple, Contour и Render (Рис. 5). В окне модуля Render видны результаты визуализации данных, построенные модулем Contour в виде линий равного уровня значений функции.
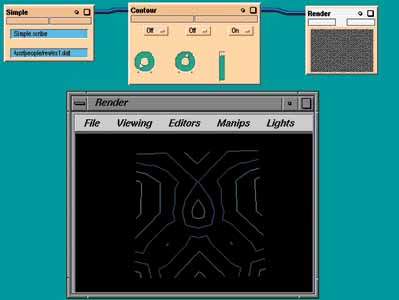
Рисунок 5.
Хотя рассмотренный пример прост, он содержит практически все принципиальные моменты для визуального построения модулей ввода данных. Во-первых, формат представления данных из входного файла описывается глифами, определяющими типы входных объектов и их атрибуты. Возможные типы объектов содержатся в Палитре типов данных и переносятся в шаблон визуально. Во-вторых, преобразование данных из входных файлов в типы данных EXPLORER производится путем установки связей между компонентами глифов входных и выходных шаблонов. В-третьих, атрибуты объектов - типы данных, имена и размерности могут - заноситься либо непосредственно в шаблон, либо связываться с ранее определенными объектами шаблона. Последнее относится к размерностям. Несмотря на то что в примере мы конструировали модуль ввода данных, имея в виду конкретный массив, ясно, что с помощью этого же модуля можно ввести данные из любого файла, который содержит значения данных в виде двухмерной матрицы любой формы.
На Рис. 6 приведен пример оцифрованного рентгеновского снимка сосудистой системы. Полутоновое черно-белое изображение введено в виде двумерного массива значений яркостей пикселей с помощью модуля Simple, переведено в 3D-пространство модулем DisplaceLat, преобразовано в поверхность модулем LatToGeom, раскрашено модулем GenerateColormap и, наконец, визуализировано модулем Render.
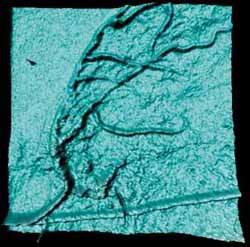
Рисунок 6.
Дополнительные возможности утилиты DataScribe
Дополнительные возможности утилиты DataScribe можно и не знать, но они весьма полезны для того, чтобы заранее не привязывать форматы входных файлов к системе EXPLORER.
В один скрипт можно включить несколько входных и выходных шаблонов, что позволит приложению в системе EXPLORER вводить данные из нескольких файлов и, возможно, связывать их с одним выходным шаблоном. Например, координаты сетки могут быть записаны в одном файле, значения данных в другом, и из этих двух файлов можно сформировать один объект типа Lattice.
Массивы, определяемые в шаблонах, могут быть иерархическими. Это значит, что при задании типов их компонентов можно использовать не только примитивные типы, как, например, Integer, но и любой из типов, указанных в Палитре типов данных (Рис. 2). Так, двухмерное изображение в формате RGBA (red, green, blue, opacity) может быть представлено, как 2D-массив векторов длины 4. Иерархическая структура особенно полезна при работе с тензорными величинами. Например, в задачах из области механики сплошных сред, значения данных представляют собой тензор напряжений, заданный в каждом узле. Его можно представить в виде 3D-массива, каждый элемент которого является 2D-массивом размерности 3х3.
Из входных файлов можно выбирать только часть содержащейся в них информации. Такая ситуация возникает, если файл записан в каком-то стандартном формате или содержит поясняющие тексты. В этом случае в шаблон включается глиф типа Pattern, имеющий в качестве значения некий текст, представляющий собой образец, который ищется в файле при вводе. Интерпретация глифов, следующих в шаблоне за глифом типа Pattern, продолжается с позиции, в которой найден образец.
Следующая возможность утилиты DataScribe позволяет выбрать из файла регулярно расположенное подмножество данных, что может быть полезно, например, если в файле для каждого узла представлены значения нескольких величин - температура, давление, скорость. Конкретное приложение может интересоваться только одной из этих величин, например давлением. В таком случае при описании входного шаблона для выборки нужных элементов в глифе дополнительно задается правило изменения индексов.
Для представления данных в системе EXPLORER помимо типа Lattice используется также тип Pyramid, позволяющий компактно представить данные конечно-элементного анализа и молекулярные данные. Хотя DataScribe не дает возможности непосредственно сформировать данные типа Pyramid, здесь не возникает проблем, поскольку тип Pyramid представляет собой иерархию данных типа Lattice. В результате, данные Pyramid можно ввести в два приема: вначале ввести из файлов все нужные объекты типа Lattice, а затем сформировать из них объект типа Pyramid, например, с помощью модуля ComposePyr.
Утилита Module Builder
Утилита Module Builder (Mbuilder) решает задачу превращения программы, написанной на языке программирования C или Fortran, в модуль, подготовленный к исполнению в системе EXPLORER. Потребность создания собственных модулей в дополнение к поставляемым в комплекте с EXPLORER может возникнуть, например, для реализации алгоритмов генерации данных с последующей их визуализацией, либо при добавлении новых методов визуализации. Предполагается, что программный код, который реализует выполняемую модулем обработку данных, создается штатными средствами операционной системы и помещается в один или несколько файлов. Собственно создание модуля из программного кода производится визуально и состоит из двух основных этапов.
Во-первых, определяется внутренний интерфейс модуля:
- входные и выходные порты;
- аргументы функции, которая реализует программную обработку;
- связи между портами и аргументами функции.
Во-вторых, строится управляющая панель модуля, которая определяет его пользовательский интерфейс. Выбирается состав, тип и расположение виджетов.
Основное окно (Рис. 7) утилиты Mbuilder содержит кнопки для перехода к управляющим панелям, текстовые слоты для ввода имени создаваемого модуля (Module Name) и названий файлов, содержащих исходные или объектные коды программы (User Func File) - таких файлов может быть несколько.
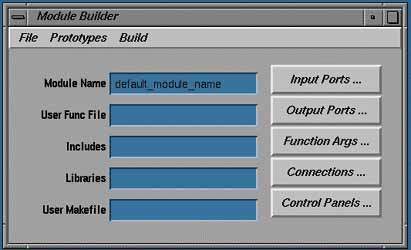
Рисунок 7.
Можно либо создать совершенно новый модуль, начиная с нуля, либо модифицировать уже имеющиеся. В том числе можно использовать модули, поставляемые вместе с системой (они поставляются не только с внешним интерфейсом, но и с исходными текстами). При модификации модуля можно, например, изменить состав виджетов, специализировав модуль в контексте разрабатываемого приложения, и сохранить его под новым именем.
Разрабатывая тела модулей, можно использовать любые из имеющихся средств системы UNIX и языка C: библиотеки функций, файлы прототипов, Make-файлы. Дополнительные файлы указываются в соответствующих слотах главного окна и используются при сборке модуля. Кроме того, для работы со своими типами данных EXPLORER предоставляет набор функций C, составляющих программный интерфейс с приложением.
В результате выполнения утилиты Mbuilder происходит компиляция всех нужных исходных файлов, создание файла ресурсов модуля (.mres) и генерация оболочки модуля, благодаря которой он может включаться в схемы.
Определение портов
Входные порты соответствуют входным объектам данных, которые модуль будет получать в начале своего выполнения из выходных портов модулей, предшествующих текущему модулю. Специальным случаем входного порта является порт - параметр, которому соответствует виджет на управляющей панели для ввода значения параметра.
Входные и выходные порты определяются одинаково в графических панелях Input(Output) Ports (Рис. 8). Имя порта задается в текстовом слоте. При сборке схем по этому имени происходит идентификация порта в меню портов модуля. Порты могут иметь только один из пяти типов данных: Lattice, Pyramid, Geometry, Parameter, Pick. Редактор Схем использует информацию о типах портов, когда происходит их связывание, причем можно связать только порты одного типа.
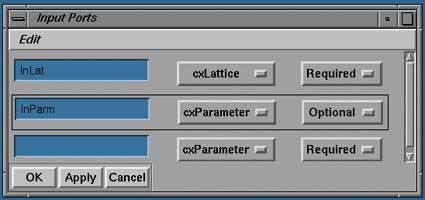
Рисунок 8.
Каждый порт имеет определенный статус - обязательный (Required) или вспомогательный (Optional). Различие в статусе состоит в том, что для инициирования выполнения модуля в схеме все обязательные порты должны быть связаны, а подаваемые на их входы данные должны быть вычислены. Для вспомогательных портов этого не требуется.
Если определяется порт типа Lattice или Pyramid, то появляется окно для задания ограничений на объект этого типа. Тип Lattice весьма общий и позволяет представить многообразие объектов, однако реальный модуль может обрабатывать только некоторое их подмножество. Допустимые значения для компонентов данных типа Lattice размещаются в панели, приведенной на Рис. 9.
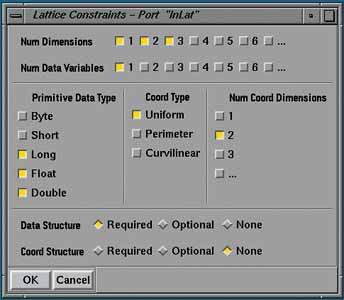
Рисунок 9.
Можно установить жесткие ограничения на входной порт, задав, например, размерность пространства nDim=2 или тип значений PrimType=float. Тогда при соединении портов эти ограничения будут проверяться и в случае нарушения будет выдана ошибка. Можно, однако, создать универсальный модуль, который способен обрабатывать более широкий класс объектов - тогда в окне выбираются все или большая часть из возможных значений.
Поддержку возможности работать с портом, на который могут подаваться объекты с разными размерными параметрами, должна обеспечивать программная реализация модуля, а обработка различных типов значений данных (PrimType) и узлов сетки (CoordType) осуществляется силами системы EXPLORER. В этом случае перед выполнением тела модуля будет происходить преобразование входных данных из того типа, в котором они вычислены (в разных схемах типы могут быть разными), в тип, определенный для аргумента функции, в который эти данные передаются. Иными словами, функция для модуля может быть написана для обработки единственного типа данных, скажем float, но модуль будет в состоянии правильно работать с любым поступающим на входной порт типом данных.
Определение аргументов функции
Интерфейс модуля с реализующей его функцией определяется путем ввода имен файлов программы в главном окне и описания аргументов в окне которое показано на Рис. 10.
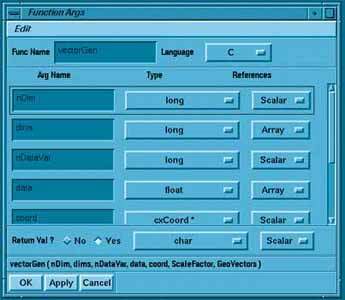
Рисунок 10.
В этом окне определяется также язык программирования, на котором написана функция: C(C++) или Fortran, а в разделе окна, озаглавленном Arg Name, перечисляются имена аргументов, причем в том же порядке, в котором они стоят в заголовке функции. Далее для каждого аргумента определяется соответствующий тип данных, выбираемый из меню, которое содержит все примитивные типы C и типы данных системы EXPLORER. В разделе References указывается, передается ли аргумент по ссылке или по значению, а в разделе Return Val - возвращает ли функция значение. Информации, вводимой в этом окне, достаточно для построения прототипа функции и в меню окна имеется пункт для создания текстового файла прототипа.
Все описанные в окне аргументы функции должны быть связаны с входными или выходными портами. Связывание аргументов и портов производится в окне Связи (Connections) (Рис. 11).
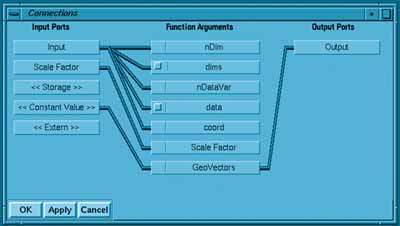
Рисунок 11.
Окно Связи состоит из трех частей: Input Ports, Function Arguments, Output Ports, в которых перечисляются входные порты, аргументы функции и выходные порты. Визуальный механизм связывания остается прежним и заключается в выборе пары объектов из разных частей окна. В качестве объектов связывания выступают порты и аргументы функции, причем, связать можно либо объекты целиком, либо их компоненты, меню выбора которых появляется при указании курсором на объект.
Несколько аргументов функции можно связать с одним выходным портом и полностью сформировать объект EXPLORER, даже если функция не использует типы данных этой системы. Аналогично можно ввести несколько аргументов из одного входного порта. При связывании должны соблюдаться следующие правила.
1. Все выходные порты должны быть полностью определены. Каждый элемент выходного порта должен иметь источник в виде аргумента функции или входного порта.
2. Можно либо связать некоторую структуру целиком, либо связать все ее отдельные компоненты.
3. Входные порты можно связать либо с аргументами функции, либо с выходным портом. Порт может иметь несколько связей для каждого из его компонента.
Создание управляющей панели модуля
Управляющая панель является визуальным образом модуля, посредством которого он включается в схему обработки. Управляющая панель - это окно где размещаются виджеты, предназначенные для ввода параметров модуля - объектов типа Parameter. Управляющая панель создается и модифицируется в Редакторе Управляющих Панелей (Control Panel Editor - CPE). CPE может быть вызван из Редактора Схем, утилиты Module Builder и утилиты DataScribe.
CPE имеет два окна: окно редактирования (Рис. 12) и окно предварительного просмотра (Рис. 13).
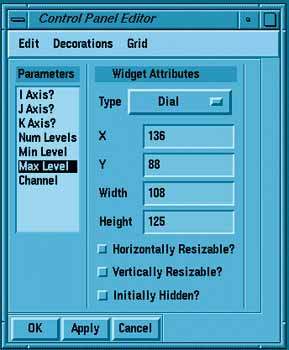
Рисунок 12.
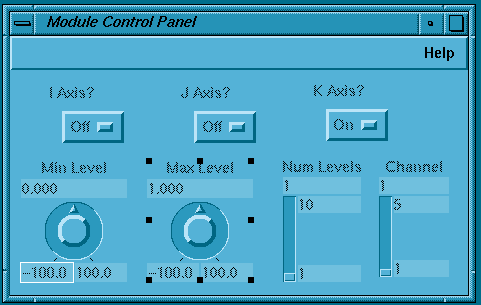
Рисунок 13.
В окне предварительного просмотра всегда можно видеть текущее состояние редактируемой панели. Когда определяется внутренний интерфейс модуля, система EXPLORER автоматически создает исходную управляющую панель, которую можно улучшить средствами CPE, а именно:
- выбрать тип виджета для каждого параметра;
- определить оформление и скомпоновать виджеты в окне;
- установить текущее значение и диапазон значений в виджете;
- создать меню модуля.
Главная цель редактирования управляющей панели - определить для каждого параметра модуля способ ввода его значений. Делается это все тем же приемом - связыванием параметра и виджета. В окне редактирования содержится список параметров модуля и список типов виджетов. Выбрав какой-либо параметр, для него подбирается подходящий тип виджета, который после этого появляется в окне предварительного просмотра.
В системе EXPLORER параметры могут целыми (long integer), вещественными (double) или текстовыми (char). Список типов виджетов включает кнопки, слайдер, циферблат (dials), слот для ввода и редактирования текста, меню опций и селектор файлов. Параметры и виджеты должны соответствовать друг другу. Так, для ввода вещественных параметров используется циферблат, а для ввода целых - слайдер. Некоторые типы виджетов эквивалентны по типу вводимых данных и взаимозаменяемы. Например, вместо слайдера или циферблата можно использовать текстовый слот.
Виджеты, предназначенные для ввода числовых данных, имеют минимальные и максимальное значения, а также текущее значение, которое будет устанавливаться каждый раз при запуске схемы. Любое из этих чисел можно изменить, введя новое значение в соответствующий текстовый слот окна предварительного просмотра. Таким же образом устанавливаются состояния кнопок и меню опций.
Далее можно оформить виджеты и скомпоновать управляющую панель - виджеты можно визуально перемещать внутри панели и менять их размеры, а для отдельного виджета можно выбрать декорации - вертикальные и горизонтальные линии, рамки, метки. Эти элементы оформления содержатся в меню декораций и визуально переносятся в виджет.
Создание групп и независимых приложений
Рассмотренный до сих пор аппарат системы EXPLORER оперирует двумя функциональными уровнями: модулями и схемами приложений, составленными из модулей. При решении прикладной задачи обнаруживается, что схема имеет тенденцию быстро усложняться и в конце концов становится малообозримой. С другой стороны, обычно используется только часть функциональных возможностей модулей, а некоторые управляющие параметры можно зафиксировать после того, как для них подобраны оптимальные значения.
Аппарат группирования модулей позволяет объединить несколько связанных модулей, выделив их из схемы приложения, и создать для этой группы одну управляющую панель, включив в нее только те параметры, которые действительно требуется изменять. С точки зрения пользователя группа будет выглядеть как единая функциональная единица. Рассмотрим в качестве примера схему, изображенную на Рис. 14.
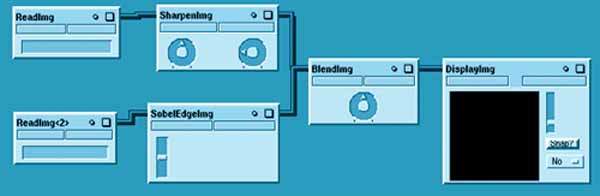
Рисунок 14.
Данная схема применяется для обработки изображений и использует три метода, каждому из которых соответствует свой модуль: SharpenImg, SobelEdgeImg и BlendImg. Все модули имеют свои управляющие параметры, для работы с которыми используются соответствующие виджеты. Работу с этой схемой можно упростить, если объединить все три модуля обработки изображений в группу, как показано на Рис. 15 меткой Group. Управляющая панель группы содержит все виджеты из панелей модулей.
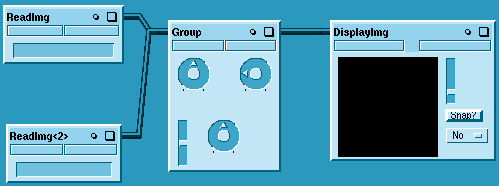
Рисунок 15.
Группирование модулей можно осуществить непосредственно в Редакторе Схем - модули, объединяемые в группу, выделяются, например, резиновым прямоугольником. Затем выполняется пункт "Group" из меню Редактора Схем. Чтобы построить из выбранных модулей группу нужно:
- определить, какая часть из портов и виджетов модулей должна быть вынесена на уровень группы;
- создать управляющую панель группы.
Для выбора портов используется инструментальная панель, называемая Group Editor, где объединены порты всех группируемых модулей и каждому порту сопоставлена кнопка, имеющая состояние, показывающее, включается ли соответствующий порт в группу. Group Editor учитывает, какие из портов обязательно должны быть вынесены на уровень группы - иначе группа никогда не будет выполняться из-за отсутствия входных данных. Для таких портов соответствующие кнопки имеют включенное состояние и не могут переключаться.
Когда определен состав портов, создается управляющая панель группы по умолчанию и ее можно отредактировать с помощью Редактора Управляющих Панелей.
Заключение
Заканчивая обзор системы EXPLORER, хотелось бы отметить несколько обстоятельств. В системе EXPLORER последовательно реализуются три важных принципа организации программных систем: объектная ориентированность, модульность и визуальный графический интерфейс. Способ создания приложений из модулей составляет интересную альтернативу привычным меню - ориентированным прикладным системам. Этот способ можно рассматривать как развитие классического понятия ОС Unix - конвейера, на визуальную среду программирования.
Инструментальные средства системы EXPLORER - визуальные утилиты - позволяют строить внешний интерфейс модулей без привлечения базового программного аппарата графических библиотек, управления окнами и событиями.
Реализованный в системе EXPLORER подход необязательно связан с приложениями визуализации данных и может быть расширен на другие предметные области. Подкреплением такому мнению служит то, что EXPLORER открыт не только для добавления новых модулей, но в нем есть также программный аппарат для определения пользовательских типов данных.
Литература
[1]. Коваленко В., Визуализация данных в системе IRIS EXPLORER. - "Открытые системы", N2, 1996, с. 74-79.
